 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnknown Aware AI-Generated Content Attribution
Jan 01, 2026The rapid advancement of photorealistic generative models has made it increasingly important to attribute the origin of synthetic content, moving beyond binary real or fake detection toward identifying the specific model that produced a given image. We study the problem of distinguishing outputs from a target generative model (e.g., OpenAI Dalle 3) from other sources, including real images and images generated by a wide range of alternative models. Using CLIP features and a simple linear classifier, shown to be effective in prior work, we establish a strong baseline for target generator attribution using only limited labeled data from the target model and a small number of known generators. However, this baseline struggles to generalize to harder, unseen, and newly released generators. To address this limitation, we propose a constrained optimization approach that leverages unlabeled wild data, consisting of images collected from the Internet that may include real images, outputs from unknown generators, or even samples from the target model itself. The proposed method encourages wild samples to be classified as non target while explicitly constraining performance on labeled data to remain high. Experimental results show that incorporating wild data substantially improves attribution performance on challenging unseen generators, demonstrating that unlabeled data from the wild can be effectively exploited to enhance AI generated content attribution in open world settings.
Stress-Testing Model Specs Reveals Character Differences among Language Models
Oct 09, 2025Large language models (LLMs) are increasingly trained from AI constitutions and model specifications that establish behavioral guidelines and ethical principles. However, these specifications face critical challenges, including internal conflicts between principles and insufficient coverage of nuanced scenarios. We present a systematic methodology for stress-testing model character specifications, automatically identifying numerous cases of principle contradictions and interpretive ambiguities in current model specs. We stress test current model specs by generating scenarios that force explicit tradeoffs between competing value-based principles. Using a comprehensive taxonomy we generate diverse value tradeoff scenarios where models must choose between pairs of legitimate principles that cannot be simultaneously satisfied. We evaluate responses from twelve frontier LLMs across major providers (Anthropic, OpenAI, Google, xAI) and measure behavioral disagreement through value classification scores. Among these scenarios, we identify over 70,000 cases exhibiting significant behavioral divergence. Empirically, we show this high divergence in model behavior strongly predicts underlying problems in model specifications. Through qualitative analysis, we provide numerous example issues in current model specs such as direct contradiction and interpretive ambiguities of several principles. Additionally, our generated dataset also reveals both clear misalignment cases and false-positive refusals across all of the frontier models we study. Lastly, we also provide value prioritization patterns and differences of these models.
Topology-Aware Conformal Prediction for Stream Networks
Mar 06, 2025



Stream networks, a unique class of spatiotemporal graphs, exhibit complex directional flow constraints and evolving dependencies, making uncertainty quantification a critical yet challenging task. Traditional conformal prediction methods struggle in this setting due to the need for joint predictions across multiple interdependent locations and the intricate spatio-temporal dependencies inherent in stream networks. Existing approaches either neglect dependencies, leading to overly conservative predictions, or rely solely on data-driven estimations, failing to capture the rich topological structure of the network. To address these challenges, we propose Spatio-Temporal Adaptive Conformal Inference (\texttt{STACI}), a novel framework that integrates network topology and temporal dynamics into the conformal prediction framework. \texttt{STACI} introduces a topology-aware nonconformity score that respects directional flow constraints and dynamically adjusts prediction sets to account for temporal distributional shifts. We provide theoretical guarantees on the validity of our approach and demonstrate its superior performance on both synthetic and real-world datasets. Our results show that \texttt{STACI} effectively balances prediction efficiency and coverage, outperforming existing conformal prediction methods for stream networks.
Bridging the Creativity Understanding Gap: Small-Scale Human Alignment Enables Expert-Level Humor Ranking in LLMs
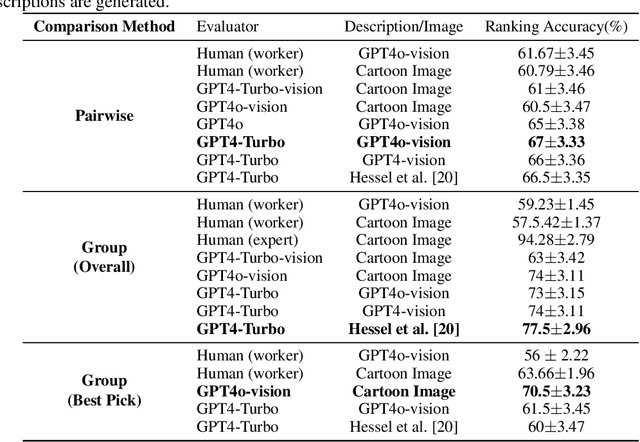
Feb 27, 2025Large Language Models (LLMs) have shown significant limitations in understanding creative content, as demonstrated by Hessel et al. (2023)'s influential work on the New Yorker Cartoon Caption Contest (NYCCC). Their study exposed a substantial gap between LLMs and humans in humor comprehension, establishing that understanding and evaluating creative content is key challenge in AI development. We revisit this challenge by decomposing humor understanding into three components and systematically improve each: enhancing visual understanding through improved annotation, utilizing LLM-generated humor reasoning and explanations, and implementing targeted alignment with human preference data. Our refined approach achieves 82.4% accuracy in caption ranking, singificantly improving upon the previous 67% benchmark and matching the performance of world-renowned human experts in this domain. Notably, while attempts to mimic subgroup preferences through various persona prompts showed minimal impact, model finetuning with crowd preferences proved remarkably effective. These findings reveal that LLM limitations in creative judgment can be effectively addressed through focused alignment to specific subgroups and individuals. Lastly, we propose the position that achieving artificial general intelligence necessitates systematic collection of human preference data across creative domains. We advocate that just as human creativity is deeply influenced by individual and cultural preferences, training LLMs with diverse human preference data may be essential for developing true creative understanding.
Harnessing Multiple Correlated Networks for Exact Community Recovery
Dec 03, 2024We study the problem of learning latent community structure from multiple correlated networks, focusing on edge-correlated stochastic block models with two balanced communities. Recent work of Gaudio, R\'acz, and Sridhar (COLT 2022) determined the precise information-theoretic threshold for exact community recovery using two correlated graphs; in particular, this showcased the subtle interplay between community recovery and graph matching. Here we study the natural setting of more than two graphs. The main challenge lies in understanding how to aggregate information across several graphs when none of the pairwise latent vertex correspondences can be exactly recovered. Our main result derives the precise information-theoretic threshold for exact community recovery using any constant number of correlated graphs, answering a question of Gaudio, R\'acz, and Sridhar (COLT 2022). In particular, for every $K \geq 3$ we uncover and characterize a region of the parameter space where exact community recovery is possible using $K$ correlated graphs, even though (1) this is information-theoretically impossible using any $K-1$ of them and (2) none of the latent matchings can be exactly recovered.
From Prototypes to General Distributions: An Efficient Curriculum for Masked Image Modeling
Nov 16, 2024Masked Image Modeling (MIM) has emerged as a powerful self-supervised learning paradigm for visual representation learning, enabling models to acquire rich visual representations by predicting masked portions of images from their visible regions. While this approach has shown promising results, we hypothesize that its effectiveness may be limited by optimization challenges during early training stages, where models are expected to learn complex image distributions from partial observations before developing basic visual processing capabilities. To address this limitation, we propose a prototype-driven curriculum leagrning framework that structures the learning process to progress from prototypical examples to more complex variations in the dataset. Our approach introduces a temperature-based annealing scheme that gradually expands the training distribution, enabling more stable and efficient learning trajectories. Through extensive experiments on ImageNet-1K, we demonstrate that our curriculum learning strategy significantly improves both training efficiency and representation quality while requiring substantially fewer training epochs compared to standard Masked Auto-Encoding. Our findings suggest that carefully controlling the order of training examples plays a crucial role in self-supervised visual learning, providing a practical solution to the early-stage optimization challenges in MIM.
Deep Active Learning in the Open World
Nov 10, 2024Machine learning models deployed in open-world scenarios often encounter unfamiliar conditions and perform poorly in unanticipated situations. As AI systems advance and find application in safety-critical domains, effectively handling out-of-distribution (OOD) data is crucial to building open-world learning systems. In this work, we introduce ALOE, a novel active learning algorithm for open-world environments designed to enhance model adaptation by incorporating new OOD classes via a two-stage approach. First, diversity sampling selects a representative set of examples, followed by energy-based OOD detection to prioritize likely unknown classes for annotation. This strategy accelerates class discovery and learning, even under constrained annotation budgets. Evaluations on three long-tailed image classification benchmarks demonstrate that ALOE outperforms traditional active learning baselines, effectively expanding known categories while balancing annotation cost. Our findings reveal a crucial tradeoff between enhancing known-class performance and discovering new classes, setting the stage for future advancements in open-world machine learning.
AHA: Human-Assisted Out-of-Distribution Generalization and Detection
Oct 10, 2024
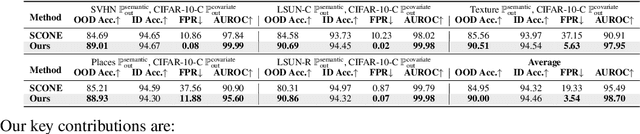

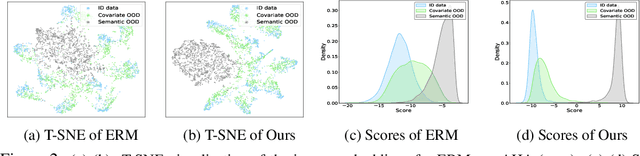
Modern machine learning models deployed often encounter distribution shifts in real-world applications, manifesting as covariate or semantic out-of-distribution (OOD) shifts. These shifts give rise to challenges in OOD generalization and OOD detection. This paper introduces a novel, integrated approach AHA (Adaptive Human-Assisted OOD learning) to simultaneously address both OOD generalization and detection through a human-assisted framework by labeling data in the wild. Our approach strategically labels examples within a novel maximum disambiguation region, where the number of semantic and covariate OOD data roughly equalizes. By labeling within this region, we can maximally disambiguate the two types of OOD data, thereby maximizing the utility of the fixed labeling budget. Our algorithm first utilizes a noisy binary search algorithm that identifies the maximal disambiguation region with high probability. The algorithm then continues with annotating inside the identified labeling region, reaping the full benefit of human feedback. Extensive experiments validate the efficacy of our framework. We observed that with only a few hundred human annotations, our method significantly outperforms existing state-of-the-art methods that do not involve human assistance, in both OOD generalization and OOD detection. Code is publicly available at \url{https://github.com/HaoyueBaiZJU/aha}.
SIEVE: General Purpose Data Filtering System Matching GPT-4o Accuracy at 1% the Cost
Oct 03, 2024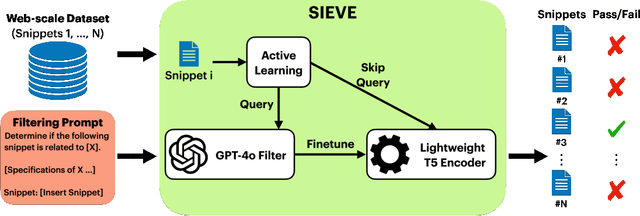
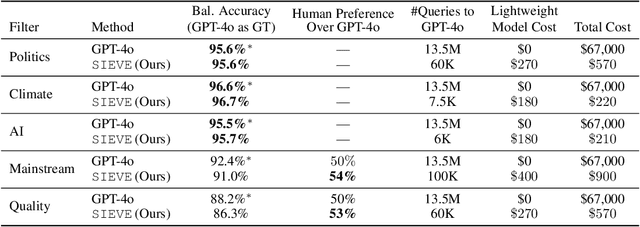
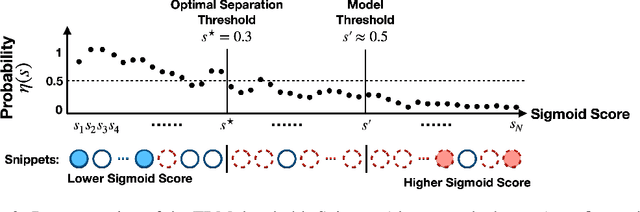
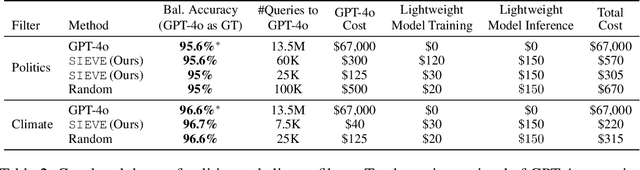
Creating specialized large language models requires vast amounts of clean, special purpose data for training and fine-tuning. With only a handful of existing large-scale, domain-specific datasets, creation of new datasets is required in most applications. This requires the development of new application-specific filtering of web-scale data. Filtering with a high-performance, general-purpose LLM such as GPT-4o can be highly effective, but this is extremely expensive at web-scale. This paper proposes SIEVE, a lightweight alternative that matches GPT-4o accuracy at a fraction of the cost. SIEVE can perform up to 500 filtering operations for the cost of one GPT-4o filtering call. The key to SIEVE is a seamless integration of GPT-4o and lightweight T5 models, using active learning to fine-tune T5 in the background with a small number of calls to GPT-4o. Once trained, it performs as well as GPT-4o at a tiny fraction of the cost. We experimentally validate SIEVE on the OpenWebText dataset, using five highly customized filter tasks targeting high quality and domain-specific content. Our results demonstrate the effectiveness and efficiency of our method in curating large, high-quality datasets for language model training at a substantially lower cost (1%) than existing techniques. To further validate SIEVE, experiments show that SIEVE and GPT-4o achieve similar accuracy, with human evaluators preferring SIEVE's filtering results to those of GPT-4o.
Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning
Jun 15, 2024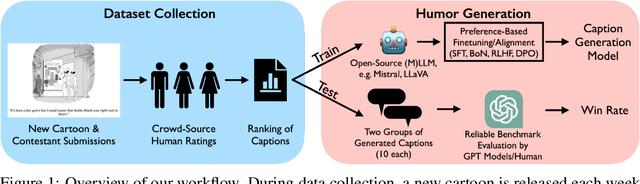

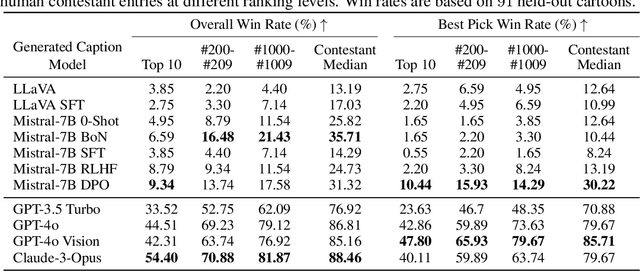
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human ratings on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.