 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Multi-Hop Relaying in Large-Scale Space-Air-Ground-Sea Integrated Networks
May 01, 2025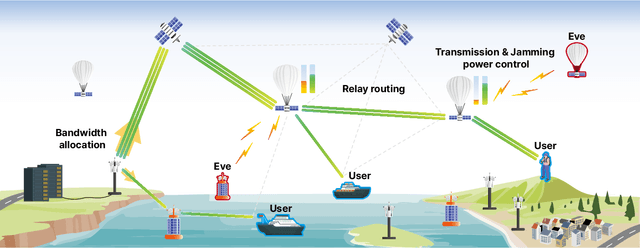
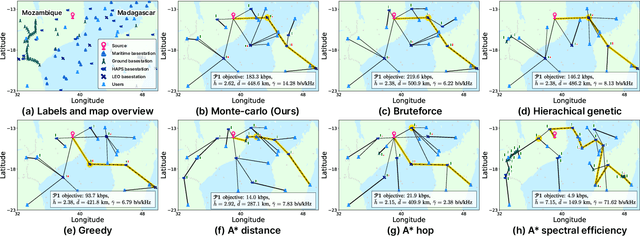

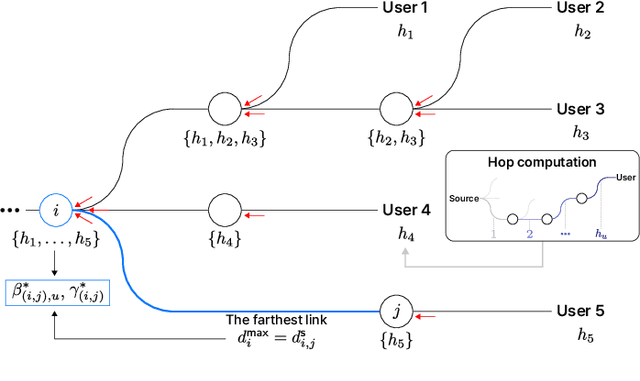
As a key enabler of borderless and ubiquitous connectivity, space-air-ground-sea integrated networks (SAGSINs) are expected to be a cornerstone of 6G wireless communications. However, the multi-tiered and global-scale nature of SAGSINs also amplifies the security vulnerabilities, particularly due to the hidden, passive eavesdroppers distributed throughout the network. In this paper, we introduce a joint optimization framework for multi-hop relaying in SAGSINs that maximizes the minimum user throughput while ensuring a minimum strictly positive secure connection (SPSC) probability. We first derive a closed-form expression for the SPSC probability and incorporate this into a cross-layer optimization framework that jointly optimizes radio resources and relay routes. Specifically, we propose an $\mathcal{O}(1)$ optimal frequency allocation and power splitting strategy-dividing power levels of data transmission and cooperative jamming. We then introduce a Monte-Carlo relay routing algorithm that closely approaches the performance of the numerical upper-bound method. We validate our framework on testbeds built with real-world dataset. All source code and data for reproducing the numerical experiments will be open-sourced.
Experimental Demonstration of Over the Air Federated Learning for Cellular Networks
Mar 09, 2025



Over-the-air federated learning (OTA-FL) offers an exciting new direction over classical FL by averaging model weights using the physics of analog signal propagation. Since each participant broadcasts its model weights concurrently in time and frequency, this paradigm conserves communication bandwidth and model upload latency. Despite its potential, there is no prior large-scale demonstration on a real-world experimental platform. This paper proves for the first time that OTA-FL can be deployed in a cellular network setting within the constraints of a 5G compliant waveform. To achieve this, we identify challenges caused by multi-path fading effects, thermal noise at the radio devices, and maintaining highly precise synchronization across multiple clients to perform coherent OTA combining. To address these challenges, we propose a unified framework for real-time channel estimation, model weight to OFDM symbol mapping and dual-layer synchronization interface to perform OTA model training. We experimentally validate OTA-FL using two relevant applications - Channel Estimation and Object Classification, at a large-scale on ORBIT Testbed and a portable setup respectively, along with analyzing the benefits from the perspective of a telecom operator. Under specific experimental conditions, OTA-FL achieves equivalent model performance, supplemented with 43 times improvement in spectrum utilization and 7 times improvement in energy efficiency over classical FL when considering 5 nodes.
TIMESAFE: Timing Interruption Monitoring and Security Assessment for Fronthaul Environments
Dec 17, 2024



5G and beyond cellular systems embrace the disaggregation of Radio Access Network (RAN) components, exemplified by the evolution of the fronthual (FH) connection between cellular baseband and radio unit equipment. Crucially, synchronization over the FH is pivotal for reliable 5G services. In recent years, there has been a push to move these links to an Ethernet-based packet network topology, leveraging existing standards and ongoing research for Time-Sensitive Networking (TSN). However, TSN standards, such as Precision Time Protocol (PTP), focus on performance with little to no concern for security. This increases the exposure of the open FH to security risks. Attacks targeting synchronization mechanisms pose significant threats, potentially disrupting 5G networks and impairing connectivity. In this paper, we demonstrate the impact of successful spoofing and replay attacks against PTP synchronization. We show how a spoofing attack is able to cause a production-ready O-RAN and 5G-compliant private cellular base station to catastrophically fail within 2 seconds of the attack, necessitating manual intervention to restore full network operations. To counter this, we design a Machine Learning (ML)-based monitoring solution capable of detecting various malicious attacks with over 97.5% accuracy.
Automatic AI Model Selection for Wireless Systems: Online Learning via Digital Twinning
Jun 22, 2024



In modern wireless network architectures, such as O-RAN, artificial intelligence (AI)-based applications are deployed at intelligent controllers to carry out functionalities like scheduling or power control. The AI "apps" are selected on the basis of contextual information such as network conditions, topology, traffic statistics, and design goals. The mapping between context and AI model parameters is ideally done in a zero-shot fashion via an automatic model selection (AMS) mapping that leverages only contextual information without requiring any current data. This paper introduces a general methodology for the online optimization of AMS mappings. Optimizing an AMS mapping is challenging, as it requires exposure to data collected from many different contexts. Therefore, if carried out online, this initial optimization phase would be extremely time consuming. A possible solution is to leverage a digital twin of the physical system to generate synthetic data from multiple simulated contexts. However, given that the simulator at the digital twin is imperfect, a direct use of simulated data for the optimization of the AMS mapping would yield poor performance when tested in the real system. This paper proposes a novel method for the online optimization of AMS mapping that corrects for the bias of the simulator by means of limited real data collected from the physical system. Experimental results for a graph neural network-based power control app demonstrate the significant advantages of the proposed approach.
Learning from the Best: Active Learning for Wireless Communications
Jan 23, 2024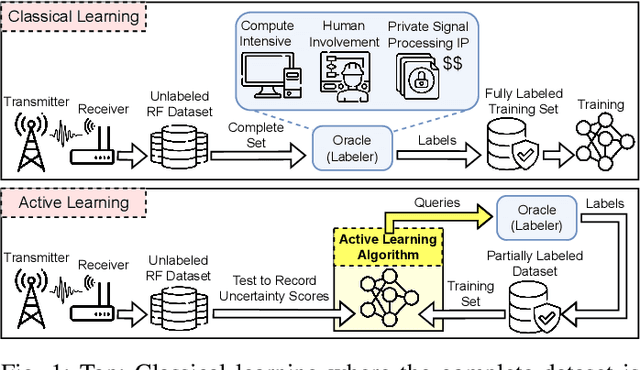
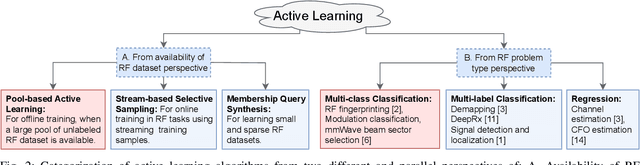
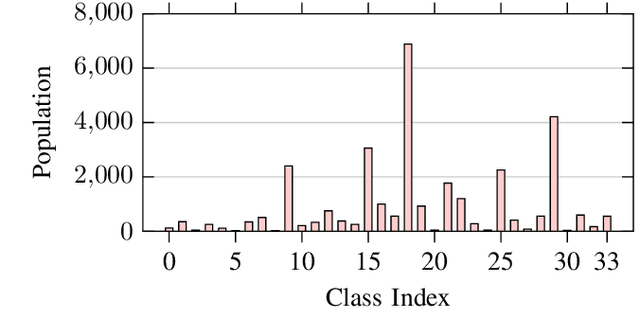
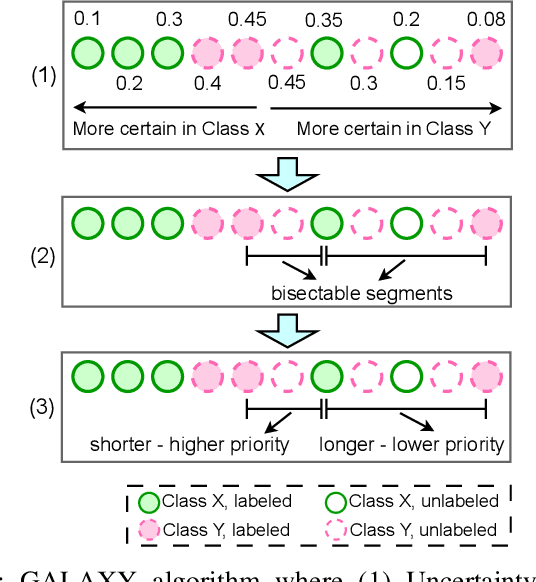
Collecting an over-the-air wireless communications training dataset for deep learning-based communication tasks is relatively simple. However, labeling the dataset requires expert involvement and domain knowledge, may involve private intellectual properties, and is often computationally and financially expensive. Active learning is an emerging area of research in machine learning that aims to reduce the labeling overhead without accuracy degradation. Active learning algorithms identify the most critical and informative samples in an unlabeled dataset and label only those samples, instead of the complete set. In this paper, we introduce active learning for deep learning applications in wireless communications, and present its different categories. We present a case study of deep learning-based mmWave beam selection, where labeling is performed by a compute-intensive algorithm based on exhaustive search. We evaluate the performance of different active learning algorithms on a publicly available multi-modal dataset with different modalities including image and LiDAR. Our results show that using an active learning algorithm for class-imbalanced datasets can reduce labeling overhead by up to 50% for this dataset while maintaining the same accuracy as classical training.
T-PRIME: Transformer-based Protocol Identification for Machine-learning at the Edge
Jan 09, 2024



Spectrum sharing allows different protocols of the same standard (e.g., 802.11 family) or different standards (e.g., LTE and DVB) to coexist in overlapping frequency bands. As this paradigm continues to spread, wireless systems must also evolve to identify active transmitters and unauthorized waveforms in real time under intentional distortion of preambles, extremely low signal-to-noise ratios and challenging channel conditions. We overcome limitations of correlation-based preamble matching methods in such conditions through the design of T-PRIME: a Transformer-based machine learning approach. T-PRIME learns the structural design of transmitted frames through its attention mechanism, looking at sequence patterns that go beyond the preamble alone. The paper makes three contributions: First, it compares Transformer models and demonstrates their superiority over traditional methods and state-of-the-art neural networks. Second, it rigorously analyzes T-PRIME's real-time feasibility on DeepWave's AIR-T platform. Third, it utilizes an extensive 66 GB dataset of over-the-air (OTA) WiFi transmissions for training, which is released along with the code for community use. Results reveal nearly perfect (i.e. $>98\%$) classification accuracy under simulated scenarios, showing $100\%$ detection improvement over legacy methods in low SNR ranges, $97\%$ classification accuracy for OTA single-protocol transmissions and up to $75\%$ double-protocol classification accuracy in interference scenarios.
Experimental Study of Adversarial Attacks on ML-based xApps in O-RAN
Sep 07, 2023Open Radio Access Network (O-RAN) is considered as a major step in the evolution of next-generation cellular networks given its support for open interfaces and utilization of artificial intelligence (AI) into the deployment, operation, and maintenance of RAN. However, due to the openness of the O-RAN architecture, such AI models are inherently vulnerable to various adversarial machine learning (ML) attacks, i.e., adversarial attacks which correspond to slight manipulation of the input to the ML model. In this work, we showcase the vulnerability of an example ML model used in O-RAN, and experimentally deploy it in the near-real time (near-RT) RAN intelligent controller (RIC). Our ML-based interference classifier xApp (extensible application in near-RT RIC) tries to classify the type of interference to mitigate the interference effect on the O-RAN system. We demonstrate the first-ever scenario of how such an xApp can be impacted through an adversarial attack by manipulating the data stored in a shared database inside the near-RT RIC. Through a rigorous performance analysis deployed on a laboratory O-RAN testbed, we evaluate the performance in terms of capacity and the prediction accuracy of the interference classifier xApp using both clean and perturbed data. We show that even small adversarial attacks can significantly decrease the accuracy of ML application in near-RT RIC, which can directly impact the performance of the entire O-RAN deployment.
Multiverse at the Edge: Interacting Real World and Digital Twins for Wireless Beamforming
May 10, 2023
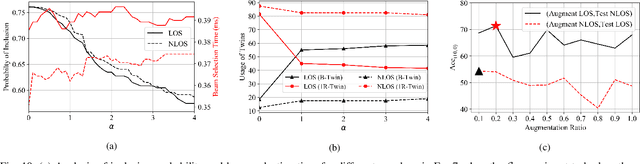


Creating a digital world that closely mimics the real world with its many complex interactions and outcomes is possible today through advanced emulation software and ubiquitous computing power. Such a software-based emulation of an entity that exists in the real world is called a 'digital twin'. In this paper, we consider a twin of a wireless millimeter-wave band radio that is mounted on a vehicle and show how it speeds up directional beam selection in mobile environments. To achieve this, we go beyond instantiating a single twin and propose the 'Multiverse' paradigm, with several possible digital twins attempting to capture the real world at different levels of fidelity. Towards this goal, this paper describes (i) a decision strategy at the vehicle that determines which twin must be used given the computational and latency limitations, and (ii) a self-learning scheme that uses the Multiverse-guided beam outcomes to enhance DL-based decision-making in the real world over time. Our work is distinguished from prior works as follows: First, we use a publicly available RF dataset collected from an autonomous car for creating different twins. Second, we present a framework with continuous interaction between the real world and Multiverse of twins at the edge, as opposed to a one-time emulation that is completed prior to actual deployment. Results reveal that Multiverse offers up to 79.43% and 85.22% top-10 beam selection accuracy for LOS and NLOS scenarios, respectively. Moreover, we observe 52.72-85.07% improvement in beam selection time compared to 802.11ad standard.
Implementing and Evaluating Security in O-RAN: Interfaces, Intelligence, and Platforms
Apr 21, 2023



The Open Radio Access Network (RAN) is a networking paradigm that builds on top of cloud-based, multi-vendor, open and intelligent architectures to shape the next generation of cellular networks for 5G and beyond. While this new paradigm comes with many advantages in terms of observatibility and reconfigurability of the network, it inevitably expands the threat surface of cellular systems and can potentially expose its components to several cyber attacks, thus making securing O-RAN networks a necessity. In this paper, we explore the security aspects of O-RAN systems by focusing on the specifications and architectures proposed by the O-RAN Alliance. We address the problem of securing O-RAN systems with an holistic perspective, including considerations on the open interfaces used to interconnect the different O-RAN components, on the overall platform, and on the intelligence used to monitor and control the network. For each focus area we identify threats, discuss relevant solutions to address these issues, and demonstrate experimentally how such solutions can effectively defend O-RAN systems against selected cyber attacks. This article is the first work in approaching the security aspect of O-RAN holistically and with experimental evidence obtained on a state-of-the-art programmable O-RAN platform, thus providing unique guideline for researchers in the field.
Neural Network-based OFDM Receiver for Resource Constrained IoT Devices
May 12, 2022
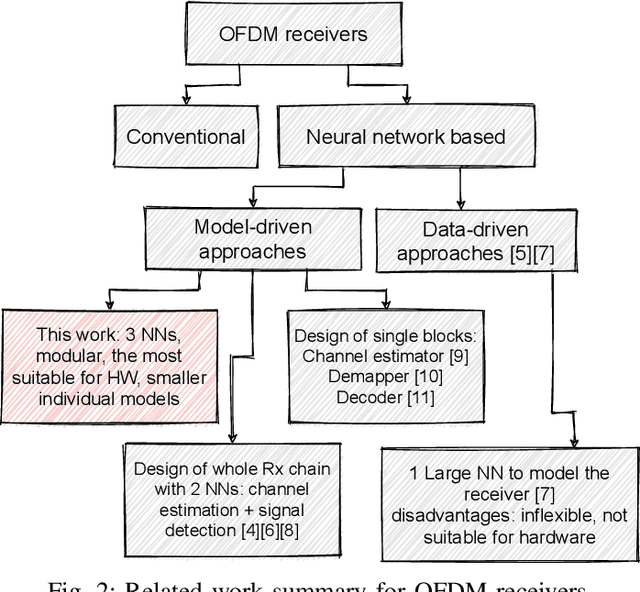
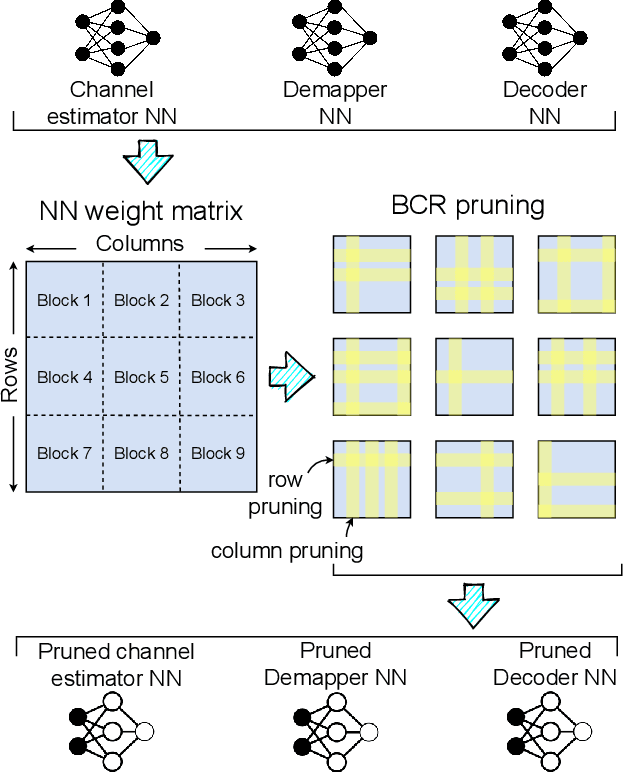
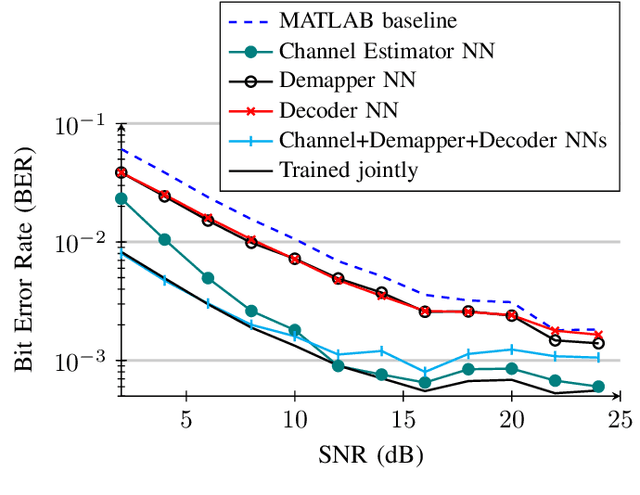
Orthogonal Frequency Division Multiplexing (OFDM)-based waveforms are used for communication links in many current and emerging Internet of Things (IoT) applications, including the latest WiFi standards. For such OFDM-based transceivers, many core physical layer functions related to channel estimation, demapping, and decoding are implemented for specific choices of channel types and modulation schemes, among others. To decouple hard-wired choices from the receiver chain and thereby enhance the flexibility of IoT deployment in many novel scenarios without changing the underlying hardware, we explore a novel, modular Machine Learning (ML)-based receiver chain design. Here, ML blocks replace the individual processing blocks of an OFDM receiver, and we specifically describe this swapping for the legacy channel estimation, symbol demapping, and decoding blocks with Neural Networks (NNs). A unique aspect of this modular design is providing flexible allocation of processing functions to the legacy or ML blocks, allowing them to interchangeably coexist. Furthermore, we study the implementation cost-benefits of the proposed NNs in resource-constrained IoT devices through pruning and quantization, as well as emulation of these compressed NNs within Field Programmable Gate Arrays (FPGAs). Our evaluations demonstrate that the proposed modular NN-based receiver improves bit error rate of the traditional non-ML receiver by averagely 61% and 10% for the simulated and over-the-air datasets, respectively. We further show complexity-performance tradeoffs by presenting computational complexity comparisons between the traditional algorithms and the proposed compressed NNs.