 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Feasible is Augmenting Fake Nodes with Learnable Features as a Counter-strategy against Link Stealing Attacks?
Mar 12, 2025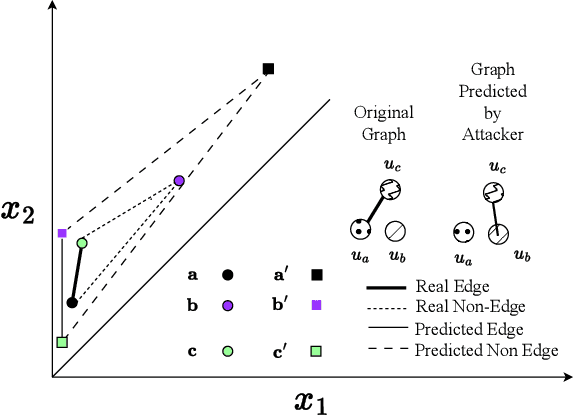

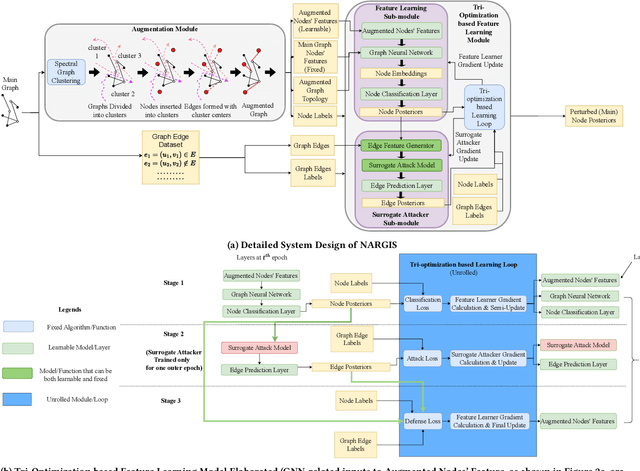
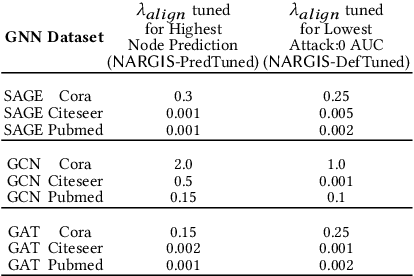
Graph Neural Networks (GNNs) are widely used and deployed for graph-based prediction tasks. However, as good as GNNs are for learning graph data, they also come with the risk of privacy leakage. For instance, an attacker can run carefully crafted queries on the GNNs and, from the responses, can infer the existence of an edge between a pair of nodes. This attack, dubbed as a "link-stealing" attack, can jeopardize the user's privacy by leaking potentially sensitive information. To protect against this attack, we propose an approach called "$(N)$ode $(A)$ugmentation for $(R)$estricting $(G)$raphs from $(I)$nsinuating their $(S)$tructure" ($NARGIS$) and study its feasibility. $NARGIS$ is focused on reshaping the graph embedding space so that the posterior from the GNN model will still provide utility for the prediction task but will introduce ambiguity for the link-stealing attackers. To this end, $NARGIS$ applies spectral clustering on the given graph to facilitate it being augmented with new nodes -- that have learned features instead of fixed ones. It utilizes tri-level optimization for learning parameters for the GNN model, surrogate attacker model, and our defense model (i.e. learnable node features). We extensively evaluate $NARGIS$ on three benchmark citation datasets over eight knowledge availability settings for the attackers. We also evaluate the model fidelity and defense performance on influence-based link inference attacks. Through our studies, we have figured out the best feature of $NARGIS$ -- its superior fidelity-privacy performance trade-off in a significant number of cases. We also have discovered in which cases the model needs to be improved, and proposed ways to integrate different schemes to make the model more robust against link stealing attacks.
TIMESAFE: Timing Interruption Monitoring and Security Assessment for Fronthaul Environments
Dec 17, 2024



5G and beyond cellular systems embrace the disaggregation of Radio Access Network (RAN) components, exemplified by the evolution of the fronthual (FH) connection between cellular baseband and radio unit equipment. Crucially, synchronization over the FH is pivotal for reliable 5G services. In recent years, there has been a push to move these links to an Ethernet-based packet network topology, leveraging existing standards and ongoing research for Time-Sensitive Networking (TSN). However, TSN standards, such as Precision Time Protocol (PTP), focus on performance with little to no concern for security. This increases the exposure of the open FH to security risks. Attacks targeting synchronization mechanisms pose significant threats, potentially disrupting 5G networks and impairing connectivity. In this paper, we demonstrate the impact of successful spoofing and replay attacks against PTP synchronization. We show how a spoofing attack is able to cause a production-ready O-RAN and 5G-compliant private cellular base station to catastrophically fail within 2 seconds of the attack, necessitating manual intervention to restore full network operations. To counter this, we design a Machine Learning (ML)-based monitoring solution capable of detecting various malicious attacks with over 97.5% accuracy.
CellularLint: A Systematic Approach to Identify Inconsistent Behavior in Cellular Network Specifications
Jul 18, 2024


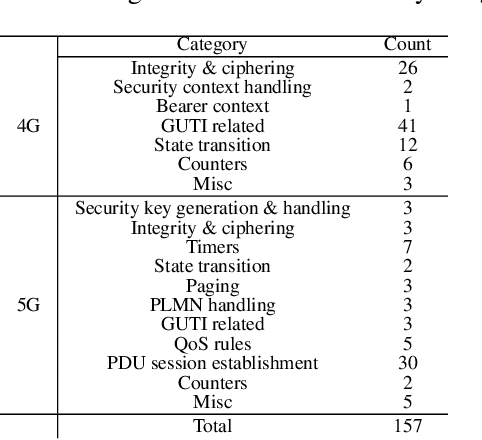
In recent years, there has been a growing focus on scrutinizing the security of cellular networks, often attributing security vulnerabilities to issues in the underlying protocol design descriptions. These protocol design specifications, typically extensive documents that are thousands of pages long, can harbor inaccuracies, underspecifications, implicit assumptions, and internal inconsistencies. In light of the evolving landscape, we introduce CellularLint--a semi-automatic framework for inconsistency detection within the standards of 4G and 5G, capitalizing on a suite of natural language processing techniques. Our proposed method uses a revamped few-shot learning mechanism on domain-adapted large language models. Pre-trained on a vast corpus of cellular network protocols, this method enables CellularLint to simultaneously detect inconsistencies at various levels of semantics and practical use cases. In doing so, CellularLint significantly advances the automated analysis of protocol specifications in a scalable fashion. In our investigation, we focused on the Non-Access Stratum (NAS) and the security specifications of 4G and 5G networks, ultimately uncovering 157 inconsistencies with 82.67% accuracy. After verification of these inconsistencies on open-source implementations and 17 commercial devices, we confirm that they indeed have a substantial impact on design decisions, potentially leading to concerns related to privacy, integrity, availability, and interoperability.
SPEC5G: A Dataset for 5G Cellular Network Protocol Analysis
Jan 22, 2023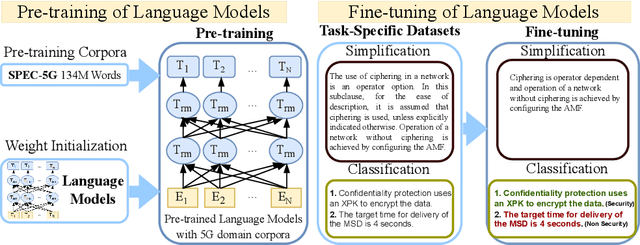
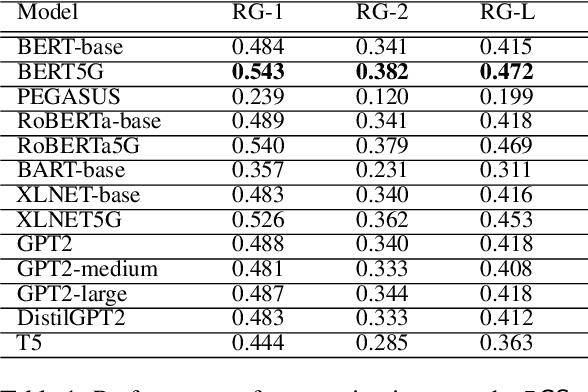
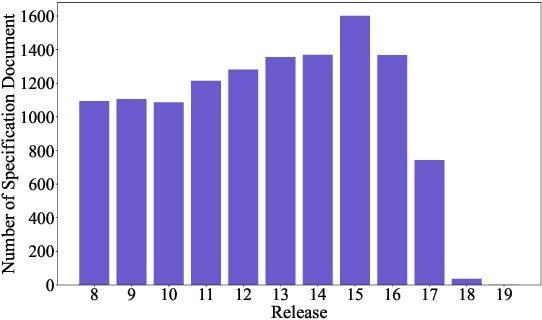
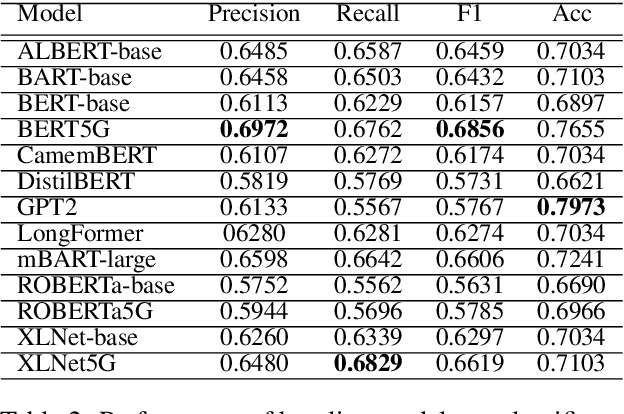
5G is the 5th generation cellular network protocol. It is the state-of-the-art global wireless standard that enables an advanced kind of network designed to connect virtually everyone and everything with increased speed and reduced latency. Therefore, its development, analysis, and security are critical. However, all approaches to the 5G protocol development and security analysis, e.g., property extraction, protocol summarization, and semantic analysis of the protocol specifications and implementations are completely manual. To reduce such manual effort, in this paper, we curate SPEC5G the first-ever public 5G dataset for NLP research. The dataset contains 3,547,586 sentences with 134M words, from 13094 cellular network specifications and 13 online websites. By leveraging large-scale pre-trained language models that have achieved state-of-the-art results on NLP tasks, we use this dataset for security-related text classification and summarization. Security-related text classification can be used to extract relevant security-related properties for protocol testing. On the other hand, summarization can help developers and practitioners understand the high level of the protocol, which is itself a daunting task. Our results show the value of our 5G-centric dataset in 5G protocol analysis automation. We believe that SPEC5G will enable a new research direction into automatic analyses for the 5G cellular network protocol and numerous related downstream tasks. Our data and code are publicly available.