 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Feasible is Augmenting Fake Nodes with Learnable Features as a Counter-strategy against Link Stealing Attacks?
Paper and Code
Mar 12, 2025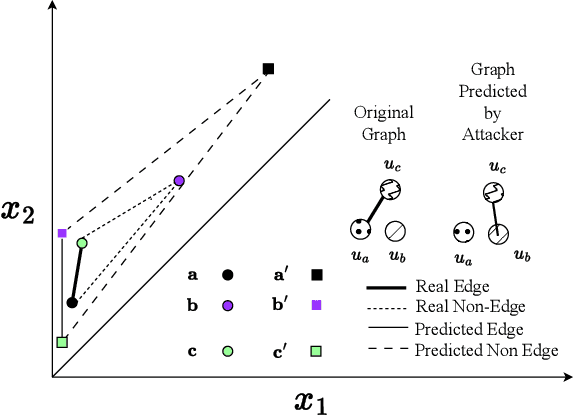

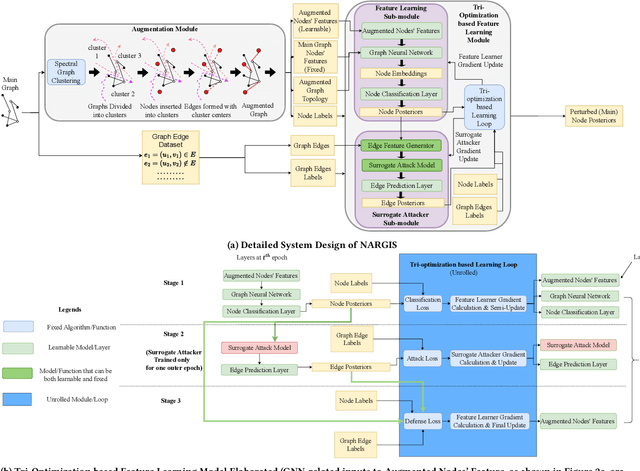
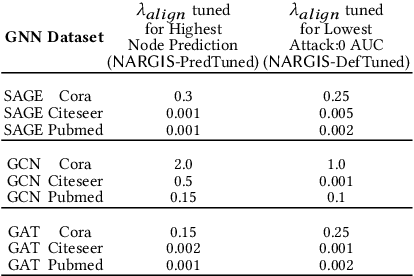
Graph Neural Networks (GNNs) are widely used and deployed for graph-based prediction tasks. However, as good as GNNs are for learning graph data, they also come with the risk of privacy leakage. For instance, an attacker can run carefully crafted queries on the GNNs and, from the responses, can infer the existence of an edge between a pair of nodes. This attack, dubbed as a "link-stealing" attack, can jeopardize the user's privacy by leaking potentially sensitive information. To protect against this attack, we propose an approach called "$(N)$ode $(A)$ugmentation for $(R)$estricting $(G)$raphs from $(I)$nsinuating their $(S)$tructure" ($NARGIS$) and study its feasibility. $NARGIS$ is focused on reshaping the graph embedding space so that the posterior from the GNN model will still provide utility for the prediction task but will introduce ambiguity for the link-stealing attackers. To this end, $NARGIS$ applies spectral clustering on the given graph to facilitate it being augmented with new nodes -- that have learned features instead of fixed ones. It utilizes tri-level optimization for learning parameters for the GNN model, surrogate attacker model, and our defense model (i.e. learnable node features). We extensively evaluate $NARGIS$ on three benchmark citation datasets over eight knowledge availability settings for the attackers. We also evaluate the model fidelity and defense performance on influence-based link inference attacks. Through our studies, we have figured out the best feature of $NARGIS$ -- its superior fidelity-privacy performance trade-off in a significant number of cases. We also have discovered in which cases the model needs to be improved, and proposed ways to integrate different schemes to make the model more robust against link stealing attacks.