 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Can Trust be Predicted with Context-Awareness in Dynamic Heterogeneous Networks?
Dec 12, 2025Trust prediction provides valuable support for decision-making, risk mitigation, and system security enhancement. Recently, Graph Neural Networks (GNNs) have emerged as a promising approach for trust prediction, owing to their ability to learn expressive node representations that capture intricate trust relationships within a network. However, current GNN-based trust prediction models face several limitations: (i) Most of them fail to capture trust dynamicity, leading to questionable inferences. (ii) They rarely consider the heterogeneous nature of real-world networks, resulting in a loss of rich semantics. (iii) None of them support context-awareness, a basic property of trust, making prediction results coarse-grained. To this end, we propose CAT, the first Context-Aware GNN-based Trust prediction model that supports trust dynamicity and accurately represents real-world heterogeneity. CAT consists of a graph construction layer, an embedding layer, a heterogeneous attention layer, and a prediction layer. It handles dynamic graphs using continuous-time representations and captures temporal information through a time encoding function. To model graph heterogeneity and leverage semantic information, CAT employs a dual attention mechanism that identifies the importance of different node types and nodes within each type. For context-awareness, we introduce a new notion of meta-paths to extract contextual features. By constructing context embeddings and integrating a context-aware aggregator, CAT can predict both context-aware trust and overall trust. Extensive experiments on three real-world datasets demonstrate that CAT outperforms five groups of baselines in trust prediction, while exhibiting strong scalability to large-scale graphs and robustness against both trust-oriented and GNN-oriented attacks.
LLM Agents Should Employ Security Principles
May 29, 2025Large Language Model (LLM) agents show considerable promise for automating complex tasks using contextual reasoning; however, interactions involving multiple agents and the system's susceptibility to prompt injection and other forms of context manipulation introduce new vulnerabilities related to privacy leakage and system exploitation. This position paper argues that the well-established design principles in information security, which are commonly referred to as security principles, should be employed when deploying LLM agents at scale. Design principles such as defense-in-depth, least privilege, complete mediation, and psychological acceptability have helped guide the design of mechanisms for securing information systems over the last five decades, and we argue that their explicit and conscientious adoption will help secure agentic systems. To illustrate this approach, we introduce AgentSandbox, a conceptual framework embedding these security principles to provide safeguards throughout an agent's life-cycle. We evaluate with state-of-the-art LLMs along three dimensions: benign utility, attack utility, and attack success rate. AgentSandbox maintains high utility for its intended functions under both benign and adversarial evaluations while substantially mitigating privacy risks. By embedding secure design principles as foundational elements within emerging LLM agent protocols, we aim to promote trustworthy agent ecosystems aligned with user privacy expectations and evolving regulatory requirements.
How Feasible is Augmenting Fake Nodes with Learnable Features as a Counter-strategy against Link Stealing Attacks?
Mar 12, 2025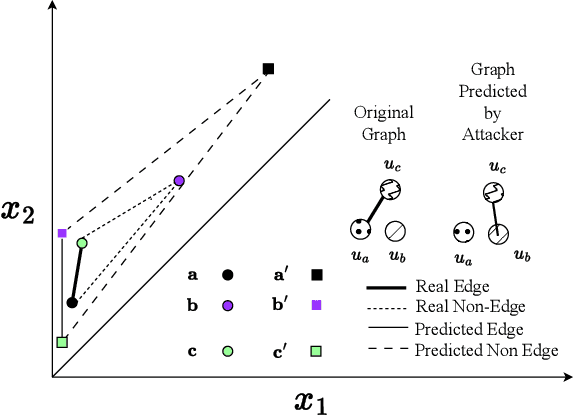

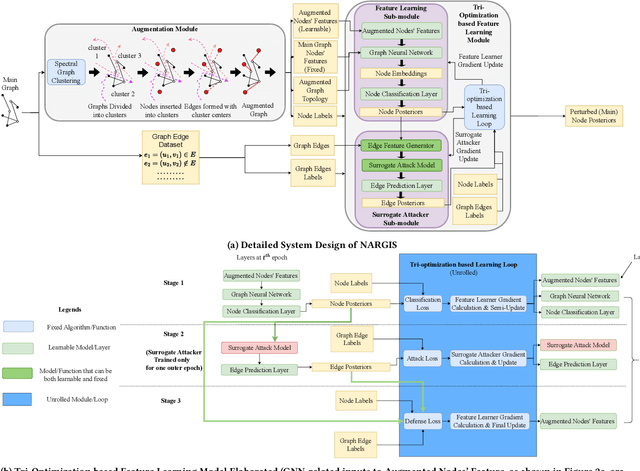
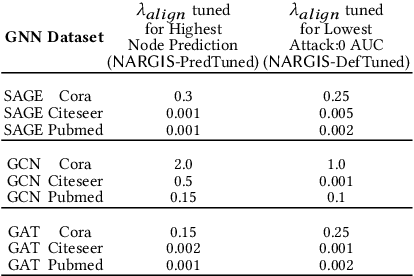
Graph Neural Networks (GNNs) are widely used and deployed for graph-based prediction tasks. However, as good as GNNs are for learning graph data, they also come with the risk of privacy leakage. For instance, an attacker can run carefully crafted queries on the GNNs and, from the responses, can infer the existence of an edge between a pair of nodes. This attack, dubbed as a "link-stealing" attack, can jeopardize the user's privacy by leaking potentially sensitive information. To protect against this attack, we propose an approach called "$(N)$ode $(A)$ugmentation for $(R)$estricting $(G)$raphs from $(I)$nsinuating their $(S)$tructure" ($NARGIS$) and study its feasibility. $NARGIS$ is focused on reshaping the graph embedding space so that the posterior from the GNN model will still provide utility for the prediction task but will introduce ambiguity for the link-stealing attackers. To this end, $NARGIS$ applies spectral clustering on the given graph to facilitate it being augmented with new nodes -- that have learned features instead of fixed ones. It utilizes tri-level optimization for learning parameters for the GNN model, surrogate attacker model, and our defense model (i.e. learnable node features). We extensively evaluate $NARGIS$ on three benchmark citation datasets over eight knowledge availability settings for the attackers. We also evaluate the model fidelity and defense performance on influence-based link inference attacks. Through our studies, we have figured out the best feature of $NARGIS$ -- its superior fidelity-privacy performance trade-off in a significant number of cases. We also have discovered in which cases the model needs to be improved, and proposed ways to integrate different schemes to make the model more robust against link stealing attacks.
TIMESAFE: Timing Interruption Monitoring and Security Assessment for Fronthaul Environments
Dec 17, 2024



5G and beyond cellular systems embrace the disaggregation of Radio Access Network (RAN) components, exemplified by the evolution of the fronthual (FH) connection between cellular baseband and radio unit equipment. Crucially, synchronization over the FH is pivotal for reliable 5G services. In recent years, there has been a push to move these links to an Ethernet-based packet network topology, leveraging existing standards and ongoing research for Time-Sensitive Networking (TSN). However, TSN standards, such as Precision Time Protocol (PTP), focus on performance with little to no concern for security. This increases the exposure of the open FH to security risks. Attacks targeting synchronization mechanisms pose significant threats, potentially disrupting 5G networks and impairing connectivity. In this paper, we demonstrate the impact of successful spoofing and replay attacks against PTP synchronization. We show how a spoofing attack is able to cause a production-ready O-RAN and 5G-compliant private cellular base station to catastrophically fail within 2 seconds of the attack, necessitating manual intervention to restore full network operations. To counter this, we design a Machine Learning (ML)-based monitoring solution capable of detecting various malicious attacks with over 97.5% accuracy.
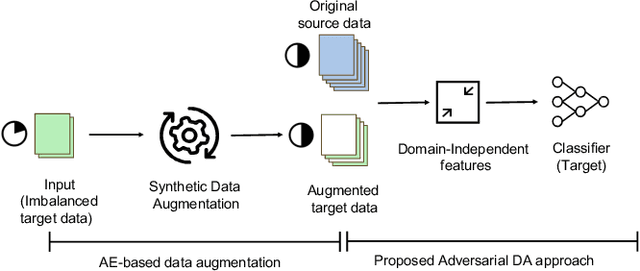
Adversarial Domain Adaptation for Metal Cutting Sound Detection: Leveraging Abundant Lab Data for Scarce Industry Data
Oct 23, 2024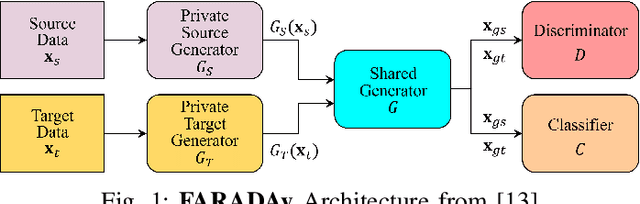
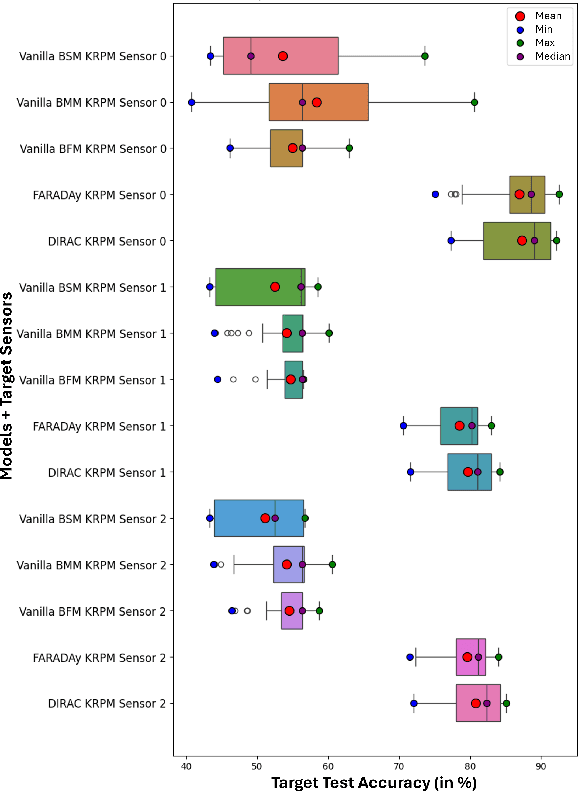
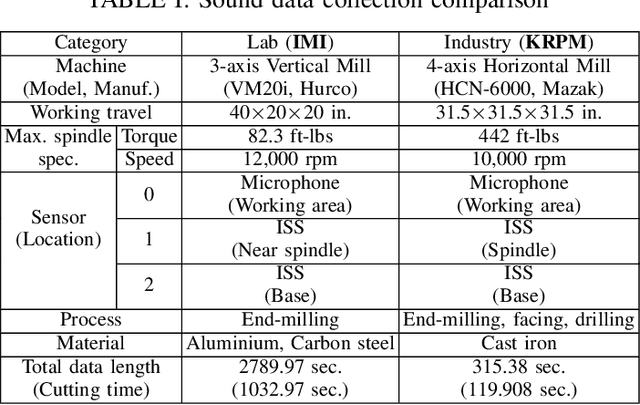

Cutting state monitoring in the milling process is crucial for improving manufacturing efficiency and tool life. Cutting sound detection using machine learning (ML) models, inspired by experienced machinists, can be employed as a cost-effective and non-intrusive monitoring method in a complex manufacturing environment. However, labeling industry data for training is costly and time-consuming. Moreover, industry data is often scarce. In this study, we propose a novel adversarial domain adaptation (DA) approach to leverage abundant lab data to learn from scarce industry data, both labeled, for training a cutting-sound detection model. Rather than adapting the features from separate domains directly, we project them first into two separate latent spaces that jointly work as the feature space for learning domain-independent representations. We also analyze two different mechanisms for adversarial learning where the discriminator works as an adversary and a critic in separate settings, enabling our model to learn expressive domain-invariant and domain-ingrained features, respectively. We collected cutting sound data from multiple sensors in different locations, prepared datasets from lab and industry domain, and evaluated our learning models on them. Experiments showed that our models outperformed the multi-layer perceptron based vanilla domain adaptation models in labeling tasks on the curated datasets, achieving near 92%, 82% and 85% accuracy respectively for three different sensors installed in industry settings.
Uncovering Attacks and Defenses in Secure Aggregation for Federated Deep Learning
Oct 13, 2024
Federated learning enables the collaborative learning of a global model on diverse data, preserving data locality and eliminating the need to transfer user data to a central server. However, data privacy remains vulnerable, as attacks can target user training data by exploiting the updates sent by users during each learning iteration. Secure aggregation protocols are designed to mask/encrypt user updates and enable a central server to aggregate the masked information. MicroSecAgg (PoPETS 2024) proposes a single server secure aggregation protocol that aims to mitigate the high communication complexity of the existing approaches by enabling a one-time setup of the secret to be re-used in multiple training iterations. In this paper, we identify a security flaw in the MicroSecAgg that undermines its privacy guarantees. We detail the security flaw and our attack, demonstrating how an adversary can exploit predictable masking values to compromise user privacy. Our findings highlight the critical need for enhanced security measures in secure aggregation protocols, particularly the implementation of dynamic and unpredictable masking strategies. We propose potential countermeasures to mitigate these vulnerabilities and ensure robust privacy protection in the secure aggregation frameworks.
CellularLint: A Systematic Approach to Identify Inconsistent Behavior in Cellular Network Specifications
Jul 18, 2024


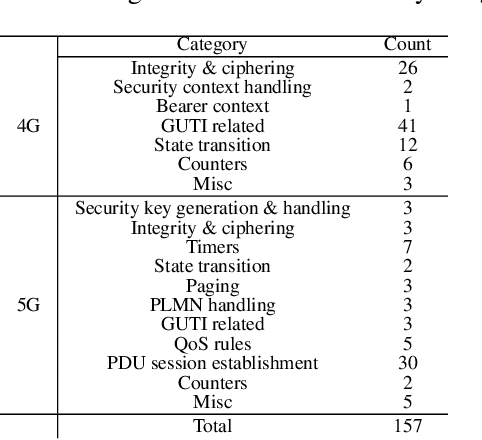
In recent years, there has been a growing focus on scrutinizing the security of cellular networks, often attributing security vulnerabilities to issues in the underlying protocol design descriptions. These protocol design specifications, typically extensive documents that are thousands of pages long, can harbor inaccuracies, underspecifications, implicit assumptions, and internal inconsistencies. In light of the evolving landscape, we introduce CellularLint--a semi-automatic framework for inconsistency detection within the standards of 4G and 5G, capitalizing on a suite of natural language processing techniques. Our proposed method uses a revamped few-shot learning mechanism on domain-adapted large language models. Pre-trained on a vast corpus of cellular network protocols, this method enables CellularLint to simultaneously detect inconsistencies at various levels of semantics and practical use cases. In doing so, CellularLint significantly advances the automated analysis of protocol specifications in a scalable fashion. In our investigation, we focused on the Non-Access Stratum (NAS) and the security specifications of 4G and 5G networks, ultimately uncovering 157 inconsistencies with 82.67% accuracy. After verification of these inconsistencies on open-source implementations and 17 commercial devices, we confirm that they indeed have a substantial impact on design decisions, potentially leading to concerns related to privacy, integrity, availability, and interoperability.
Transfer Learning for Security: Challenges and Future Directions
Mar 01, 2024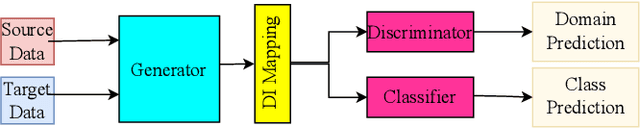

Many machine learning and data mining algorithms rely on the assumption that the training and testing data share the same feature space and distribution. However, this assumption may not always hold. For instance, there are situations where we need to classify data in one domain, but we only have sufficient training data available from a different domain. The latter data may follow a distinct distribution. In such cases, successfully transferring knowledge across domains can significantly improve learning performance and reduce the need for extensive data labeling efforts. Transfer learning (TL) has thus emerged as a promising framework to tackle this challenge, particularly in security-related tasks. This paper aims to review the current advancements in utilizing TL techniques for security. The paper includes a discussion of the existing research gaps in applying TL in the security domain, as well as exploring potential future research directions and issues that arise in the context of TL-assisted security solutions.
Prometheus: Infrastructure Security Posture Analysis with AI-generated Attack Graphs
Dec 20, 2023



The rampant occurrence of cybersecurity breaches imposes substantial limitations on the progress of network infrastructures, leading to compromised data, financial losses, potential harm to individuals, and disruptions in essential services. The current security landscape demands the urgent development of a holistic security assessment solution that encompasses vulnerability analysis and investigates the potential exploitation of these vulnerabilities as attack paths. In this paper, we propose Prometheus, an advanced system designed to provide a detailed analysis of the security posture of computing infrastructures. Using user-provided information, such as device details and software versions, Prometheus performs a comprehensive security assessment. This assessment includes identifying associated vulnerabilities and constructing potential attack graphs that adversaries can exploit. Furthermore, Prometheus evaluates the exploitability of these attack paths and quantifies the overall security posture through a scoring mechanism. The system takes a holistic approach by analyzing security layers encompassing hardware, system, network, and cryptography. Furthermore, Prometheus delves into the interconnections between these layers, exploring how vulnerabilities in one layer can be leveraged to exploit vulnerabilities in others. In this paper, we present the end-to-end pipeline implemented in Prometheus, showcasing the systematic approach adopted for conducting this thorough security analysis.
FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge
Dec 15, 2023

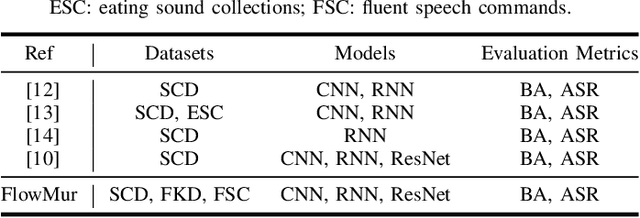

Speech recognition systems driven by DNNs have revolutionized human-computer interaction through voice interfaces, which significantly facilitate our daily lives. However, the growing popularity of these systems also raises special concerns on their security, particularly regarding backdoor attacks. A backdoor attack inserts one or more hidden backdoors into a DNN model during its training process, such that it does not affect the model's performance on benign inputs, but forces the model to produce an adversary-desired output if a specific trigger is present in the model input. Despite the initial success of current audio backdoor attacks, they suffer from the following limitations: (i) Most of them require sufficient knowledge, which limits their widespread adoption. (ii) They are not stealthy enough, thus easy to be detected by humans. (iii) Most of them cannot attack live speech, reducing their practicality. To address these problems, in this paper, we propose FlowMur, a stealthy and practical audio backdoor attack that can be launched with limited knowledge. FlowMur constructs an auxiliary dataset and a surrogate model to augment adversary knowledge. To achieve dynamicity, it formulates trigger generation as an optimization problem and optimizes the trigger over different attachment positions. To enhance stealthiness, we propose an adaptive data poisoning method according to Signal-to-Noise Ratio (SNR). Furthermore, ambient noise is incorporated into the process of trigger generation and data poisoning to make FlowMur robust to ambient noise and improve its practicality. Extensive experiments conducted on two datasets demonstrate that FlowMur achieves high attack performance in both digital and physical settings while remaining resilient to state-of-the-art defenses. In particular, a human study confirms that triggers generated by FlowMur are not easily detected by participants.