 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interactive Framework for Implementing Privacy-Preserving Federated Learning: Experiments on Large Language Models
Feb 11, 2025
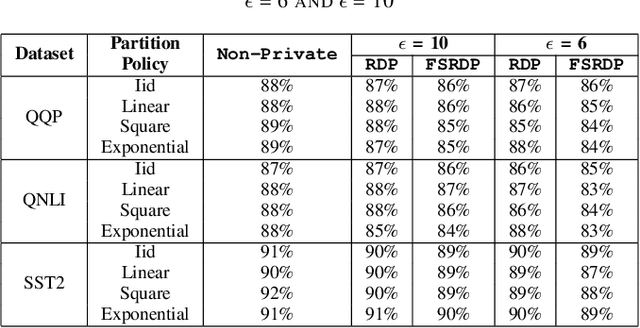


Federated learning (FL) enhances privacy by keeping user data on local devices. However, emerging attacks have demonstrated that the updates shared by users during training can reveal significant information about their data. This has greatly thwart the adoption of FL methods for training robust AI models in sensitive applications. Differential Privacy (DP) is considered the gold standard for safeguarding user data. However, DP guarantees are highly conservative, providing worst-case privacy guarantees. This can result in overestimating privacy needs, which may compromise the model's accuracy. Additionally, interpretations of these privacy guarantees have proven to be challenging in different contexts. This is further exacerbated when other factors, such as the number of training iterations, data distribution, and specific application requirements, can add further complexity to this problem. In this work, we proposed a framework that integrates a human entity as a privacy practitioner to determine an optimal trade-off between the model's privacy and utility. Our framework is the first to address the variable memory requirement of existing DP methods in FL settings, where resource-limited devices (e.g., cell phones) can participate. To support such settings, we adopt a recent DP method with fixed memory usage to ensure scalable private FL. We evaluated our proposed framework by fine-tuning a BERT-based LLM model using the GLUE dataset (a common approach in literature), leveraging the new accountant, and employing diverse data partitioning strategies to mimic real-world conditions. As a result, we achieved stable memory usage, with an average accuracy reduction of 1.33% for $\epsilon = 10$ and 1.9% for $\epsilon = 6$, when compared to the state-of-the-art DP accountant which does not support fixed memory usage.
From Machine Learning to Machine Unlearning: Complying with GDPR's Right to be Forgotten while Maintaining Business Value of Predictive Models
Nov 26, 2024Recent privacy regulations (e.g., GDPR) grant data subjects the `Right to Be Forgotten' (RTBF) and mandate companies to fulfill data erasure requests from data subjects. However, companies encounter great challenges in complying with the RTBF regulations, particularly when asked to erase specific training data from their well-trained predictive models. While researchers have introduced machine unlearning methods aimed at fast data erasure, these approaches often overlook maintaining model performance (e.g., accuracy), which can lead to financial losses and non-compliance with RTBF obligations. This work develops a holistic machine learning-to-unlearning framework, called Ensemble-based iTerative Information Distillation (ETID), to achieve efficient data erasure while preserving the business value of predictive models. ETID incorporates a new ensemble learning method to build an accurate predictive model that can facilitate handling data erasure requests. ETID also introduces an innovative distillation-based unlearning method tailored to the constructed ensemble model to enable efficient and effective data erasure. Extensive experiments demonstrate that ETID outperforms various state-of-the-art methods and can deliver high-quality unlearned models with efficiency. We also highlight ETID's potential as a crucial tool for fostering a legitimate and thriving market for data and predictive services.
Uncovering Attacks and Defenses in Secure Aggregation for Federated Deep Learning
Oct 13, 2024
Federated learning enables the collaborative learning of a global model on diverse data, preserving data locality and eliminating the need to transfer user data to a central server. However, data privacy remains vulnerable, as attacks can target user training data by exploiting the updates sent by users during each learning iteration. Secure aggregation protocols are designed to mask/encrypt user updates and enable a central server to aggregate the masked information. MicroSecAgg (PoPETS 2024) proposes a single server secure aggregation protocol that aims to mitigate the high communication complexity of the existing approaches by enabling a one-time setup of the secret to be re-used in multiple training iterations. In this paper, we identify a security flaw in the MicroSecAgg that undermines its privacy guarantees. We detail the security flaw and our attack, demonstrating how an adversary can exploit predictable masking values to compromise user privacy. Our findings highlight the critical need for enhanced security measures in secure aggregation protocols, particularly the implementation of dynamic and unpredictable masking strategies. We propose potential countermeasures to mitigate these vulnerabilities and ensure robust privacy protection in the secure aggregation frameworks.
Unsupervised Threat Hunting using Continuous Bag-of-Terms-and-Time (CBoTT)
Mar 15, 2024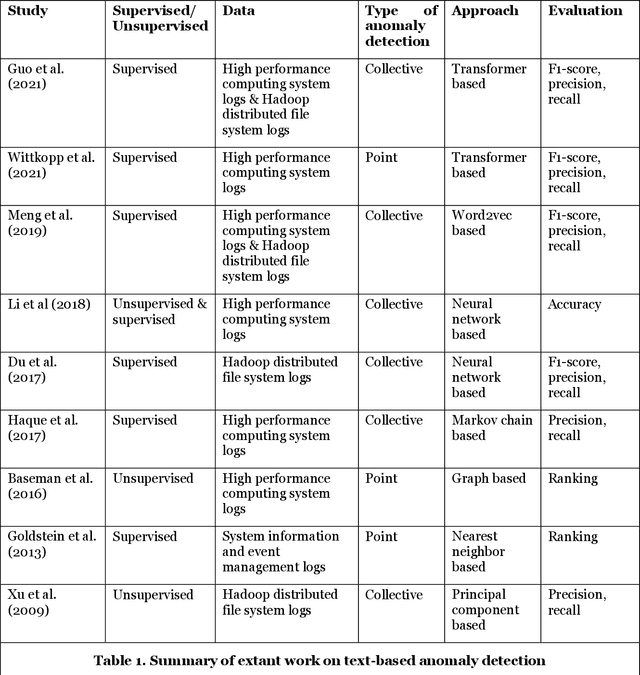
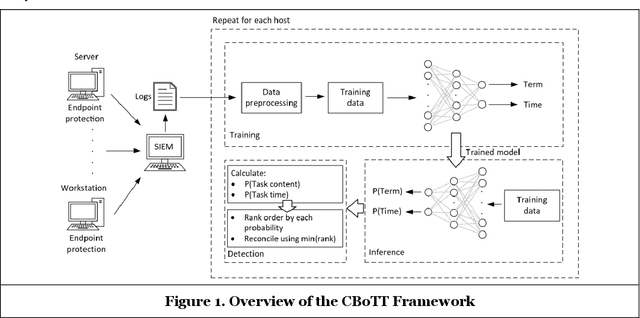
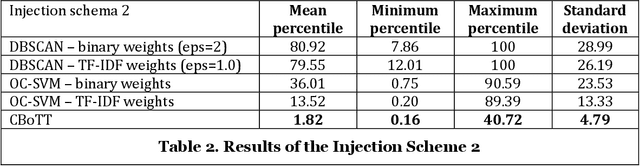
Threat hunting is sifting through system logs to detect malicious activities that might have bypassed existing security measures. It can be performed in several ways, one of which is based on detecting anomalies. We propose an unsupervised framework, called continuous bag-of-terms-and-time (CBoTT), and publish its application programming interface (API) to help researchers and cybersecurity analysts perform anomaly-based threat hunting among SIEM logs geared toward process auditing on endpoint devices. Analyses show that our framework consistently outperforms benchmark approaches. When logs are sorted by likelihood of being an anomaly (from most likely to least), our approach identifies anomalies at higher percentiles (between 1.82-6.46) while benchmark approaches identify the same anomalies at lower percentiles (between 3.25-80.92). This framework can be used by other researchers to conduct benchmark analyses and cybersecurity analysts to find anomalies in SIEM logs.
EW-Tune: A Framework for Privately Fine-Tuning Large Language Models with Differential Privacy
Oct 26, 2022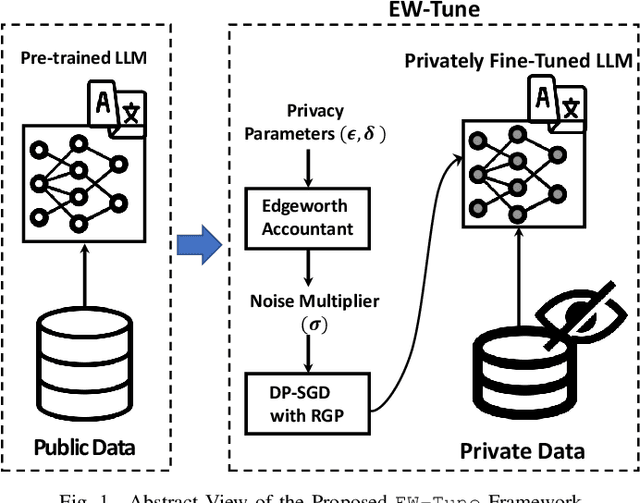
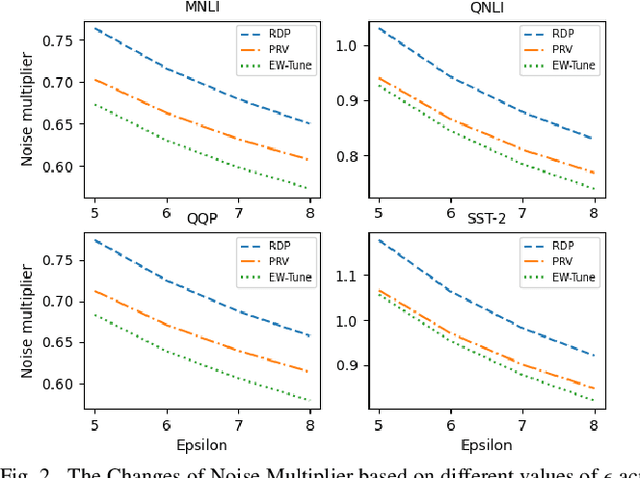

Pre-trained Large Language Models (LLMs) are an integral part of modern AI that have led to breakthrough performances in complex AI tasks. Major AI companies with expensive infrastructures are able to develop and train these large models with billions and millions of parameters from scratch. Third parties, researchers, and practitioners are increasingly adopting these pre-trained models and fine-tuning them on their private data to accomplish their downstream AI tasks. However, it has been shown that an adversary can extract/reconstruct the exact training samples from these LLMs, which can lead to revealing personally identifiable information. The issue has raised deep concerns about the privacy of LLMs. Differential privacy (DP) provides a rigorous framework that allows adding noise in the process of training or fine-tuning LLMs such that extracting the training data becomes infeasible (i.e., with a cryptographically small success probability). While the theoretical privacy guarantees offered in most extant studies assume learning models from scratch through many training iterations in an asymptotic setting, this assumption does not hold in fine-tuning scenarios in which the number of training iterations is significantly smaller. To address the gap, we present \ewtune, a DP framework for fine-tuning LLMs based on Edgeworth accountant with finite-sample privacy guarantees. Our results across four well-established natural language understanding (NLU) tasks show that while \ewtune~adds privacy guarantees to LLM fine-tuning process, it directly contributes to decreasing the induced noise to up to 5.6\% and improves the state-of-the-art LLMs performance by up to 1.1\% across all NLU tasks. We have open-sourced our implementations for wide adoption and public testing purposes.