 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Sensitive Exponential Actor Critic
Feb 06, 2026Model-free deep reinforcement learning (RL) algorithms have achieved tremendous success on a range of challenging tasks. However, safety concerns remain when these methods are deployed on real-world applications, necessitating risk-aware agents. A common utility for learning such risk-aware agents is the entropic risk measure, but current policy gradient methods optimizing this measure must perform high-variance and numerically unstable updates. As a result, existing risk-sensitive model-free approaches are limited to simple tasks and tabular settings. In this paper, we provide a comprehensive theoretical justification for policy gradient methods on the entropic risk measure, including on- and off-policy gradient theorems for the stochastic and deterministic policy settings. Motivated by theory, we propose risk-sensitive exponential actor-critic (rsEAC), an off-policy model-free approach that incorporates novel procedures to avoid the explicit representation of exponential value functions and their gradients, and optimizes its policy w.r.t the entropic risk measure. We show that rsEAC produces more numerically stable updates compared to existing approaches and reliably learns risk-sensitive policies in challenging risky variants of continuous tasks in MuJoCo.
An Interactive Framework for Implementing Privacy-Preserving Federated Learning: Experiments on Large Language Models
Feb 11, 2025
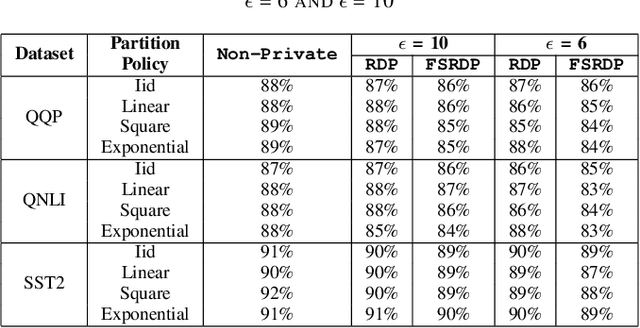


Federated learning (FL) enhances privacy by keeping user data on local devices. However, emerging attacks have demonstrated that the updates shared by users during training can reveal significant information about their data. This has greatly thwart the adoption of FL methods for training robust AI models in sensitive applications. Differential Privacy (DP) is considered the gold standard for safeguarding user data. However, DP guarantees are highly conservative, providing worst-case privacy guarantees. This can result in overestimating privacy needs, which may compromise the model's accuracy. Additionally, interpretations of these privacy guarantees have proven to be challenging in different contexts. This is further exacerbated when other factors, such as the number of training iterations, data distribution, and specific application requirements, can add further complexity to this problem. In this work, we proposed a framework that integrates a human entity as a privacy practitioner to determine an optimal trade-off between the model's privacy and utility. Our framework is the first to address the variable memory requirement of existing DP methods in FL settings, where resource-limited devices (e.g., cell phones) can participate. To support such settings, we adopt a recent DP method with fixed memory usage to ensure scalable private FL. We evaluated our proposed framework by fine-tuning a BERT-based LLM model using the GLUE dataset (a common approach in literature), leveraging the new accountant, and employing diverse data partitioning strategies to mimic real-world conditions. As a result, we achieved stable memory usage, with an average accuracy reduction of 1.33% for $\epsilon = 10$ and 1.9% for $\epsilon = 6$, when compared to the state-of-the-art DP accountant which does not support fixed memory usage.
EW-Tune: A Framework for Privately Fine-Tuning Large Language Models with Differential Privacy
Oct 26, 2022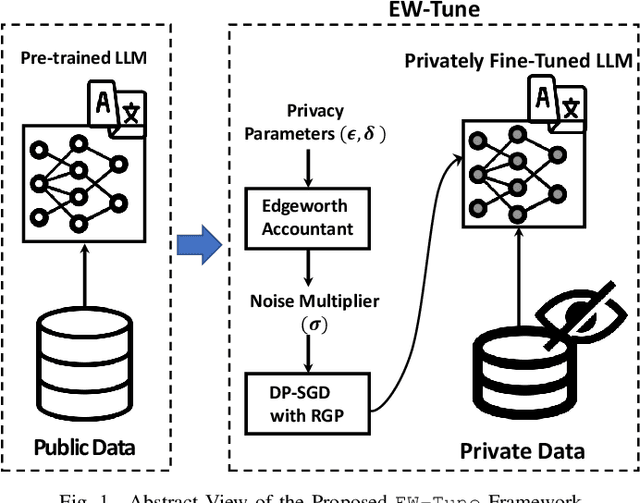
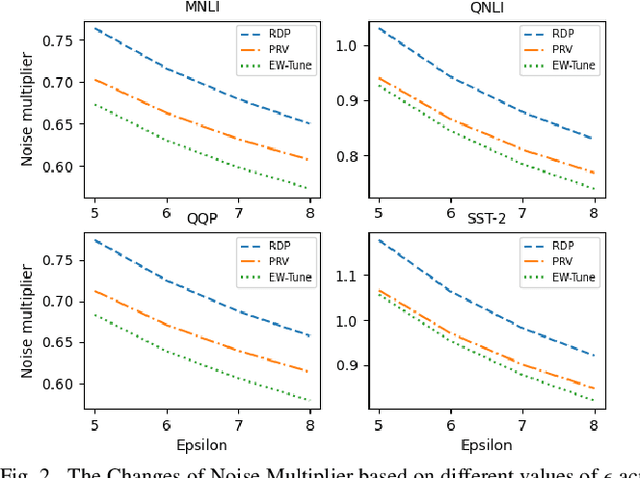

Pre-trained Large Language Models (LLMs) are an integral part of modern AI that have led to breakthrough performances in complex AI tasks. Major AI companies with expensive infrastructures are able to develop and train these large models with billions and millions of parameters from scratch. Third parties, researchers, and practitioners are increasingly adopting these pre-trained models and fine-tuning them on their private data to accomplish their downstream AI tasks. However, it has been shown that an adversary can extract/reconstruct the exact training samples from these LLMs, which can lead to revealing personally identifiable information. The issue has raised deep concerns about the privacy of LLMs. Differential privacy (DP) provides a rigorous framework that allows adding noise in the process of training or fine-tuning LLMs such that extracting the training data becomes infeasible (i.e., with a cryptographically small success probability). While the theoretical privacy guarantees offered in most extant studies assume learning models from scratch through many training iterations in an asymptotic setting, this assumption does not hold in fine-tuning scenarios in which the number of training iterations is significantly smaller. To address the gap, we present \ewtune, a DP framework for fine-tuning LLMs based on Edgeworth accountant with finite-sample privacy guarantees. Our results across four well-established natural language understanding (NLU) tasks show that while \ewtune~adds privacy guarantees to LLM fine-tuning process, it directly contributes to decreasing the induced noise to up to 5.6\% and improves the state-of-the-art LLMs performance by up to 1.1\% across all NLU tasks. We have open-sourced our implementations for wide adoption and public testing purposes.
Network-level Safety Metrics for Overall Traffic Safety Assessment: A Case Study
Jan 27, 2022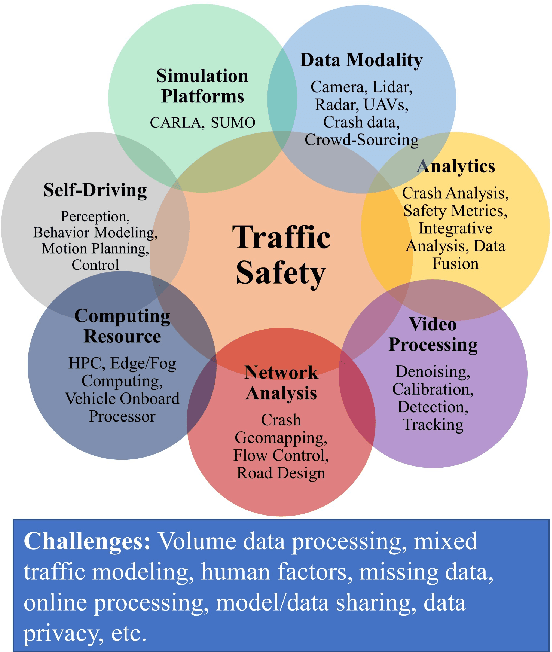
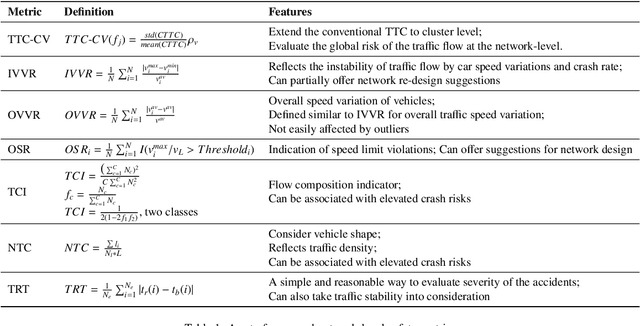
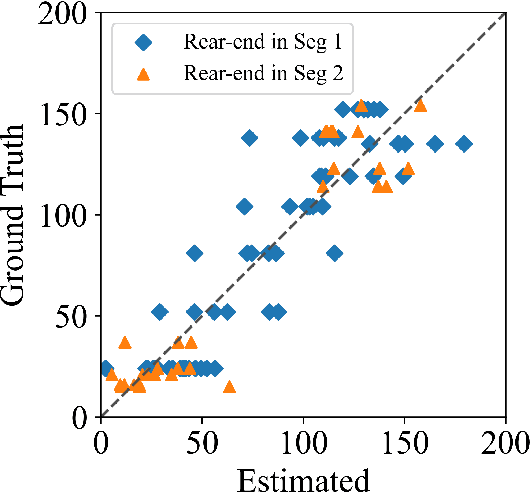
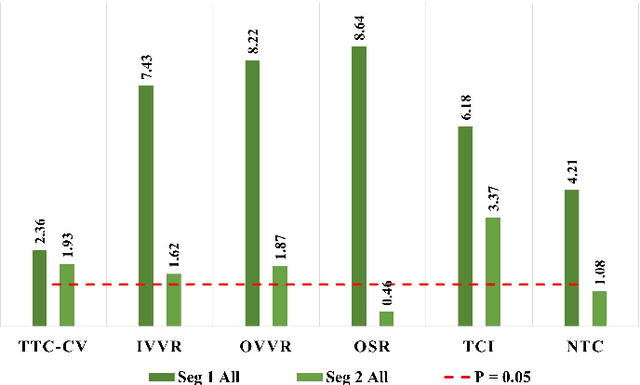
Driving safety analysis has recently witnessed unprecedented results due to advances in computation frameworks, connected vehicle technology, new generation sensors, and artificial intelligence (AI). Particularly, the recent advances performance of deep learning (DL) methods realized higher levels of safety for autonomous vehicles and empowered volume imagery processing for driving safety analysis. An important application of DL methods is extracting driving safety metrics from traffic imagery. However, the majority of current methods use safety metrics for micro-scale analysis of individual crash incidents or near-crash events, which does not provide insightful guidelines for the overall network-level traffic management. On the other hand, large-scale safety assessment efforts mainly emphasize spatial and temporal distributions of crashes, while not always revealing the safety violations that cause crashes. To bridge these two perspectives, we define a new set of network-level safety metrics for the overall safety assessment of traffic flow by processing imagery taken by roadside infrastructure sensors. An integrative analysis of the safety metrics and crash data reveals the insightful temporal and spatial correlation between the representative network-level safety metrics and the crash frequency. The analysis is performed using two video cameras in the state of Arizona along with a 5-year crash report obtained from the Arizona Department of Transportation. The results confirm that network-level safety metrics can be used by the traffic management teams to equip traffic monitoring systems with advanced AI-based risk analysis, and timely traffic flow control decisions.
Lightweight Data Fusion with Conjugate Mappings
Nov 20, 2020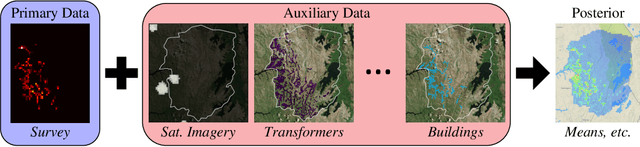
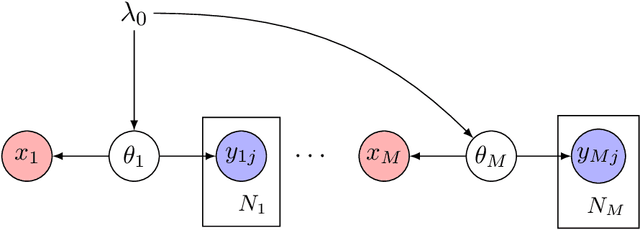

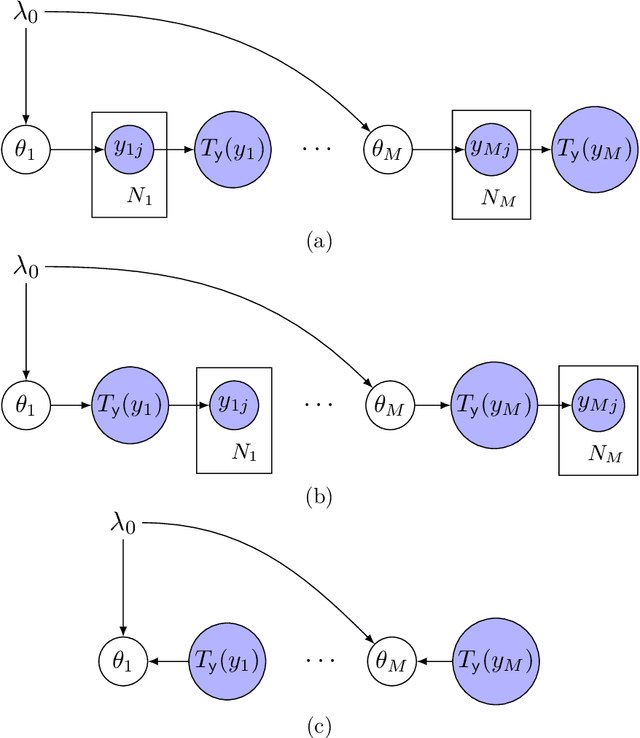
We present an approach to data fusion that combines the interpretability of structured probabilistic graphical models with the flexibility of neural networks. The proposed method, lightweight data fusion (LDF), emphasizes posterior analysis over latent variables using two types of information: primary data, which are well-characterized but with limited availability, and auxiliary data, readily available but lacking a well-characterized statistical relationship to the latent quantity of interest. The lack of a forward model for the auxiliary data precludes the use of standard data fusion approaches, while the inability to acquire latent variable observations severely limits direct application of most supervised learning methods. LDF addresses these issues by utilizing neural networks as conjugate mappings of the auxiliary data: nonlinear transformations into sufficient statistics with respect to the latent variables. This facilitates efficient inference by preserving the conjugacy properties of the primary data and leads to compact representations of the latent variable posterior distributions. We demonstrate the LDF methodology on two challenging inference problems: (1) learning electrification rates in Rwanda from satellite imagery, high-level grid infrastructure, and other sources; and (2) inferring county-level homicide rates in the USA by integrating socio-economic data using a mixture model of multiple conjugate mappings.