 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Planning under Uncertainty in Spatiotemporal Environments in Expeditionary Science
Jun 03, 2022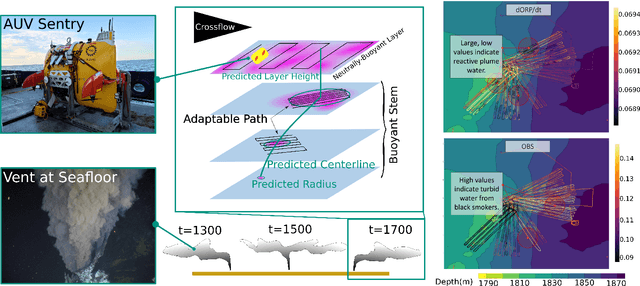
In the expeditionary sciences, spatiotemporally varying environments -- hydrothermal plumes, algal blooms, lava flows, or animal migrations -- are ubiquitous. Mobile robots are uniquely well-suited to study these dynamic, mesoscale natural environments. We formalize expeditionary science as a sequential decision-making problem, modeled using the language of partially-observable Markov decision processes (POMDPs). Solving the expeditionary science POMDP under real-world constraints requires efficient probabilistic modeling and decision-making in problems with complex dynamics and observational models. Previous work in informative path planning, adaptive sampling, and experimental design have shown compelling results, largely in static environments, using data-driven models and information-based rewards. However, these methodologies do not trivially extend to expeditionary science in spatiotemporal environments: they generally do not make use of scientific knowledge such as equations of state dynamics, they focus on information gathering as opposed to scientific task execution, and they make use of decision-making approaches that scale poorly to large, continuous problems with long planning horizons and real-time operational constraints. In this work, we discuss these and other challenges related to probabilistic modeling and decision-making in expeditionary science, and present some of our preliminary work that addresses these gaps. We ground our results in a real expeditionary science deployment of an autonomous underwater vehicle (AUV) in the deep ocean for hydrothermal vent discovery and characterization. Our concluding thoughts highlight remaining work to be done, and the challenges that merit consideration by the reinforcement learning and decision-making community.
CPU- and GPU-based Distributed Sampling in Dirichlet Process Mixtures for Large-scale Analysis
Apr 19, 2022



In the realm of unsupervised learning, Bayesian nonparametric mixture models, exemplified by the Dirichlet Process Mixture Model (DPMM), provide a principled approach for adapting the complexity of the model to the data. Such models are particularly useful in clustering tasks where the number of clusters is unknown. Despite their potential and mathematical elegance, however, DPMMs have yet to become a mainstream tool widely adopted by practitioners. This is arguably due to a misconception that these models scale poorly as well as the lack of high-performance (and user-friendly) software tools that can handle large datasets efficiently. In this paper we bridge this practical gap by proposing a new, easy-to-use, statistical software package for scalable DPMM inference. More concretely, we provide efficient and easily-modifiable implementations for high-performance distributed sampling-based inference in DPMMs where the user is free to choose between either a multiple-machine, multiple-core, CPU implementation (written in Julia) and a multiple-stream GPU implementation (written in CUDA/C++). Both the CPU and GPU implementations come with a common (and optional) python wrapper, providing the user with a single point of entry with the same interface. On the algorithmic side, our implementations leverage a leading DPMM sampler from (Chang and Fisher III, 2013). While Chang and Fisher III's implementation (written in MATLAB/C++) used only CPU and was designed for a single multi-core machine, the packages we proposed here distribute the computations efficiently across either multiple multi-core machines or across mutiple GPU streams. This leads to speedups, alleviates memory and storage limitations, and lets us fit DPMMs to significantly larger datasets and of higher dimensionality than was possible previously by either (Chang and Fisher III, 2013) or other DPMM methods.
Lightweight Data Fusion with Conjugate Mappings
Nov 20, 2020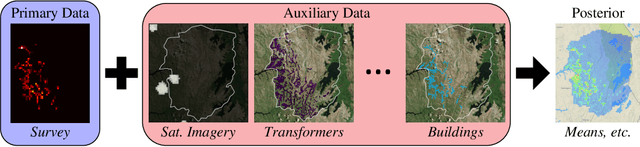
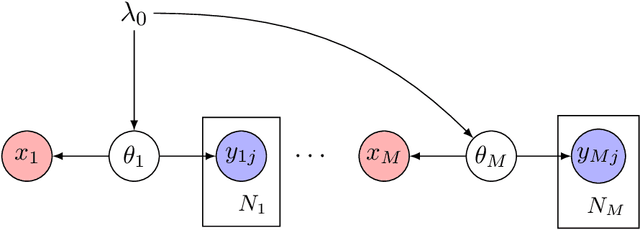

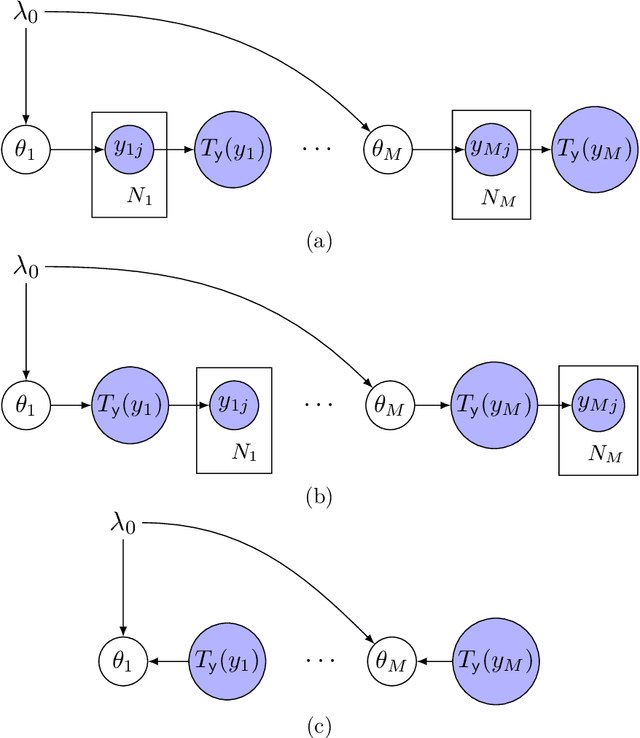
We present an approach to data fusion that combines the interpretability of structured probabilistic graphical models with the flexibility of neural networks. The proposed method, lightweight data fusion (LDF), emphasizes posterior analysis over latent variables using two types of information: primary data, which are well-characterized but with limited availability, and auxiliary data, readily available but lacking a well-characterized statistical relationship to the latent quantity of interest. The lack of a forward model for the auxiliary data precludes the use of standard data fusion approaches, while the inability to acquire latent variable observations severely limits direct application of most supervised learning methods. LDF addresses these issues by utilizing neural networks as conjugate mappings of the auxiliary data: nonlinear transformations into sufficient statistics with respect to the latent variables. This facilitates efficient inference by preserving the conjugacy properties of the primary data and leads to compact representations of the latent variable posterior distributions. We demonstrate the LDF methodology on two challenging inference problems: (1) learning electrification rates in Rwanda from satellite imagery, high-level grid infrastructure, and other sources; and (2) inferring county-level homicide rates in the USA by integrating socio-economic data using a mixture model of multiple conjugate mappings.
Efficient Data Association and Uncertainty Quantification for Multi-Object Tracking
Nov 13, 2020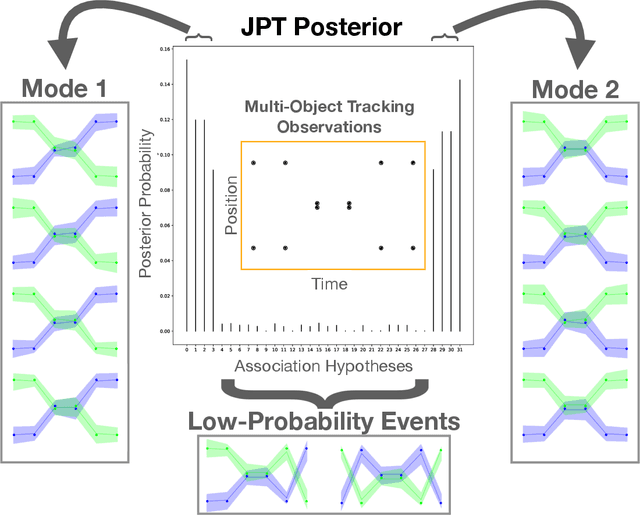

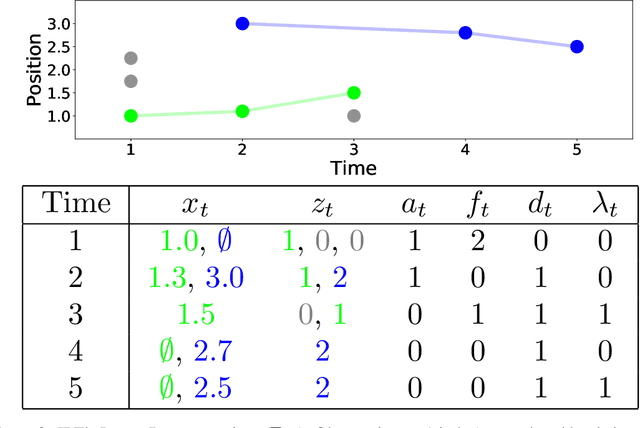
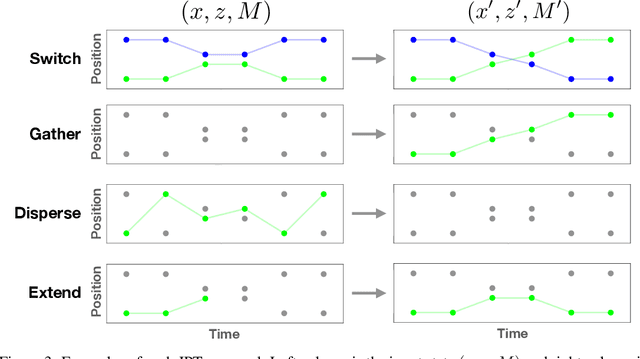
Robust data association is critical for analysis of long-term motion trajectories in complex scenes. In its absence, trajectory precision suffers due to periods of kinematic ambiguity degrading the quality of follow-on analysis. Common optimization-based approaches often neglect uncertainty quantification arising from these events. Consequently, we propose the Joint Posterior Tracker (JPT), a Bayesian multi-object tracking algorithm that robustly reasons over the posterior of associations and trajectories. Novel, permutation-based proposals are crafted for exploration of posterior modes that correspond to plausible association hypotheses. JPT exhibits more accurate uncertainty representation of data associations with superior performance on standard metrics when compared to existing baselines. We also show the utility of JPT applied to automatic scheduling of user-in-the-loop annotations for improved trajectory quality.
Bayesian Nonparametric Modeling of Driver Behavior using HDP Split-Merge Sampling Algorithm
Jan 27, 2018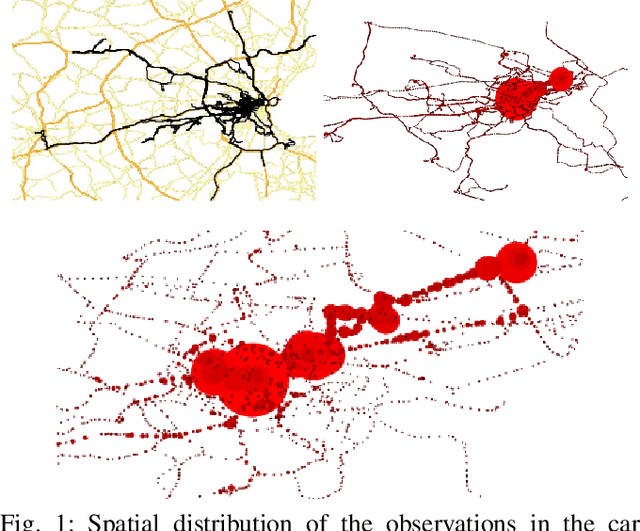
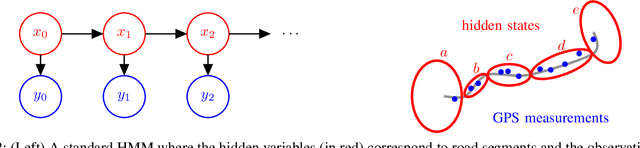
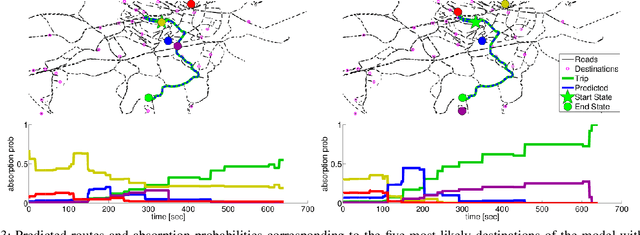
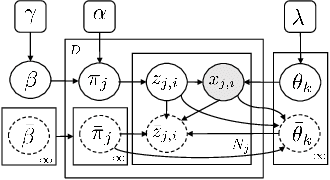
Modern vehicles are equipped with increasingly complex sensors. These sensors generate large volumes of data that provide opportunities for modeling and analysis. Here, we are interested in exploiting this data to learn aspects of behaviors and the road network associated with individual drivers. Our dataset is collected on a standard vehicle used to commute to work and for personal trips. A Hidden Markov Model (HMM) trained on the GPS position and orientation data is utilized to compress the large amount of position information into a small amount of road segment states. Each state has a set of observations, i.e. car signals, associated with it that are quantized and modeled as draws from a Hierarchical Dirichlet Process (HDP). The inference for the topic distributions is carried out using HDP split-merge sampling algorithm. The topic distributions over joint quantized car signals characterize the driving situation in the respective road state. In a novel manner, we demonstrate how the sparsity of the personal road network of a driver in conjunction with a hierarchical topic model allows data driven predictions about destinations as well as likely road conditions.
Adaptive Scan Gibbs Sampler for Large Scale Inference Problems
Jan 27, 2018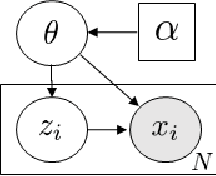
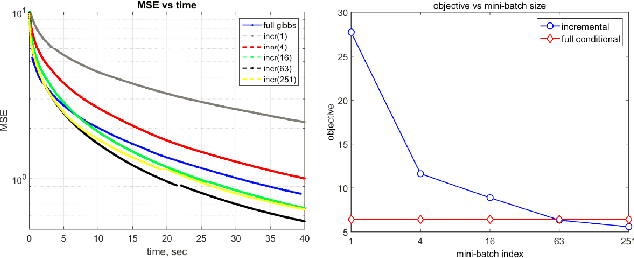

For large scale on-line inference problems the update strategy is critical for performance. We derive an adaptive scan Gibbs sampler that optimizes the update frequency by selecting an optimum mini-batch size. We demonstrate performance of our adaptive batch-size Gibbs sampler by comparing it against the collapsed Gibbs sampler for Bayesian Lasso, Dirichlet Process Mixture Models (DPMM) and Latent Dirichlet Allocation (LDA) graphical models.
Direction-Aware Semi-Dense SLAM
Sep 18, 2017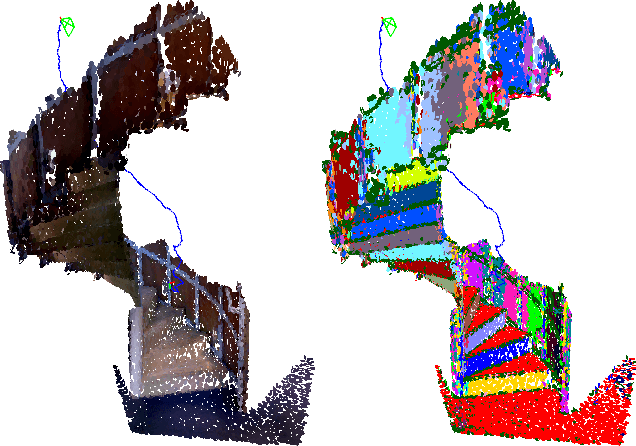
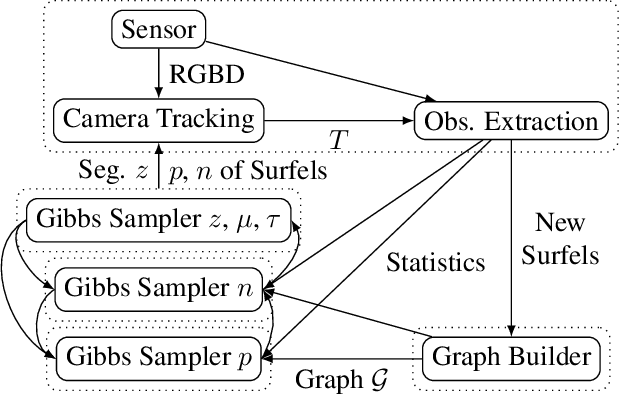
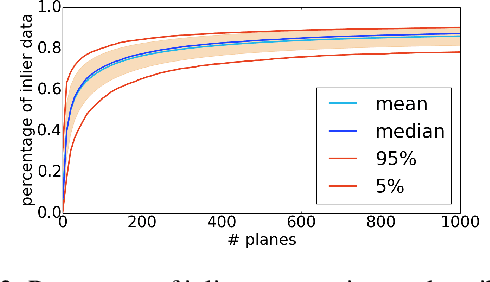
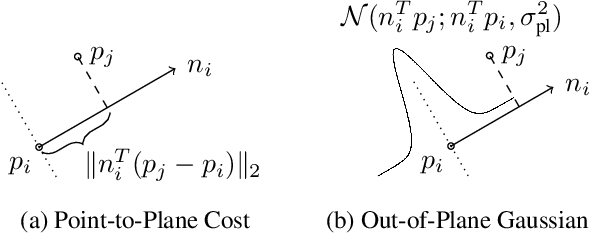
To aide simultaneous localization and mapping (SLAM), future perception systems will incorporate forms of scene understanding. In a step towards fully integrated probabilistic geometric scene understanding, localization and mapping we propose the first direction-aware semi-dense SLAM system. It jointly infers the directional Stata Center World (SCW) segmentation and a surfel-based semi-dense map while performing real-time camera tracking. The joint SCW map model connects a scene-wide Bayesian nonparametric Dirichlet Process von-Mises-Fisher mixture model (DP-vMF) prior on surfel orientations with the local surfel locations via a conditional random field (CRF). Camera tracking leverages the SCW segmentation to improve efficiency via guided observation selection. Results demonstrate improved SLAM accuracy and tracking efficiency at state of the art performance.
A Nonparametric Model for Multimodal Collaborative Activities Summarization
Sep 04, 2017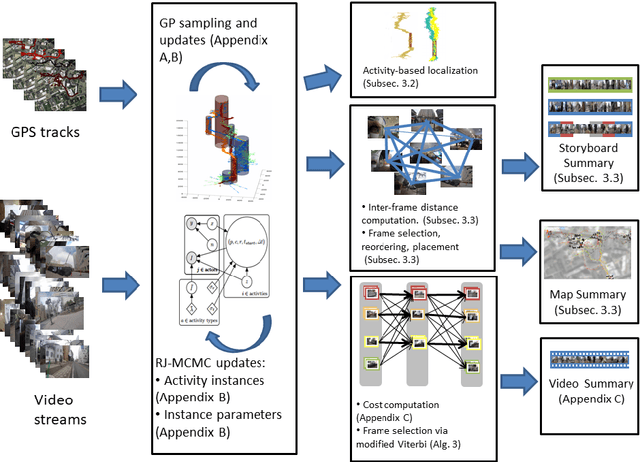
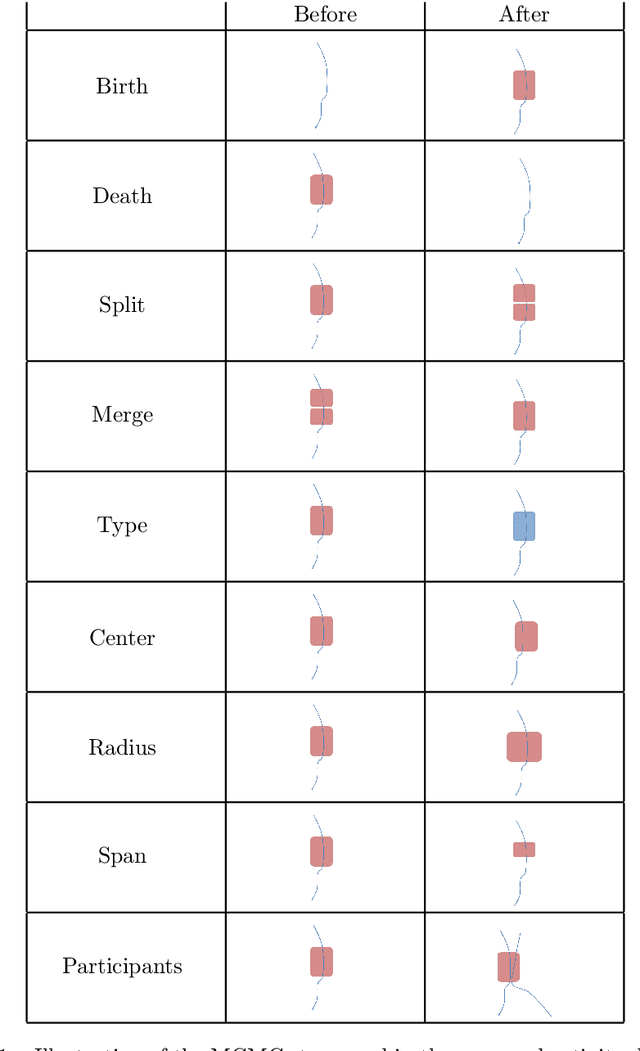
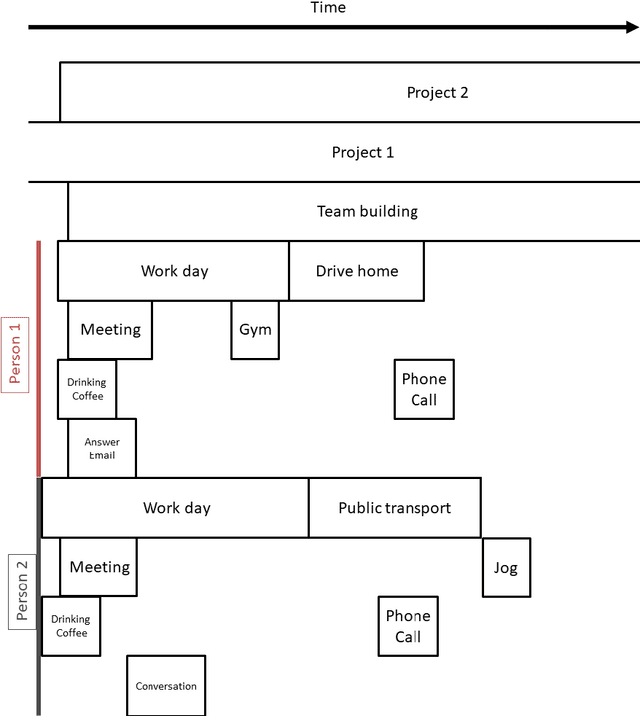
Ego-centric data streams provide a unique opportunity to reason about joint behavior by pooling data across individuals. This is especially evident in urban environments teeming with human activities, but which suffer from incomplete and noisy data. Collaborative human activities exhibit common spatial, temporal, and visual characteristics facilitating inference across individuals from multiple sensory modalities as we explore in this paper from the perspective of meetings. We propose a new Bayesian nonparametric model that enables us to efficiently pool video and GPS data towards collaborative activities analysis from multiple individuals. We demonstrate the utility of this model for inference tasks such as activity detection, classification, and summarization. We further demonstrate how spatio-temporal structure embedded in our model enables better understanding of partial and noisy observations such as localization and face detections based on social interactions. We show results on both synthetic experiments and a new dataset of egocentric video and noisy GPS data from multiple individuals.
Efficient Global Point Cloud Alignment using Bayesian Nonparametric Mixtures
Nov 22, 2016
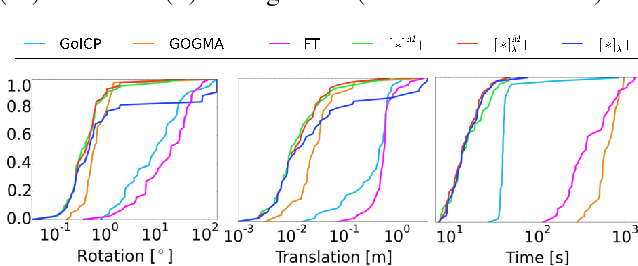
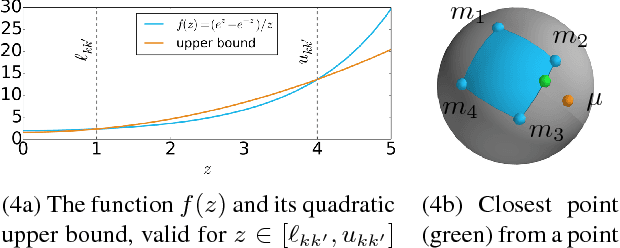
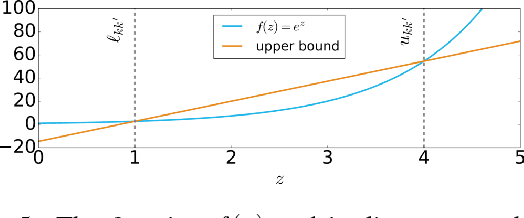
Point cloud alignment is a common problem in computer vision and robotics, with applications ranging from 3D object recognition to reconstruction. We propose a novel approach to the alignment problem that utilizes Bayesian nonparametrics to describe the point cloud and surface normal densities, and branch and bound (BB) optimization to recover the relative transformation. BB uses a novel, refinable, near-uniform tessellation of rotation space using 4D tetrahedra, leading to more efficient optimization compared to the common axis-angle tessellation. We provide objective function bounds for pruning given the proposed tessellation, and prove that BB converges to the optimum of the cost function along with providing its computational complexity. Finally, we empirically demonstrate the efficiency of the proposed approach as well as its robustness to real-world conditions such as missing data and partial overlap.
Small-Variance Nonparametric Clustering on the Hypersphere
Jul 21, 2016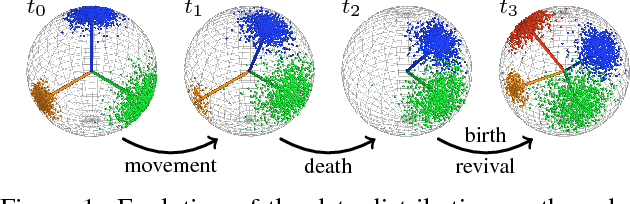
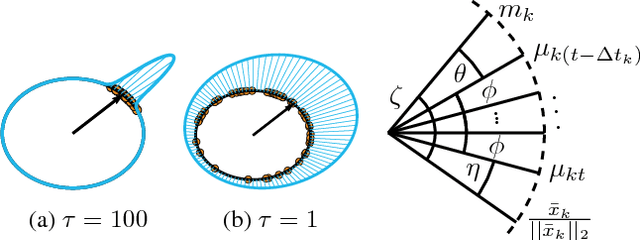
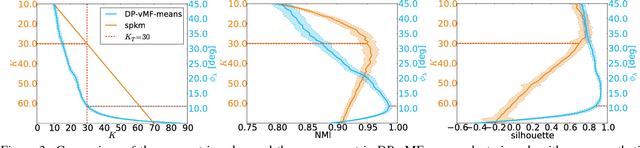
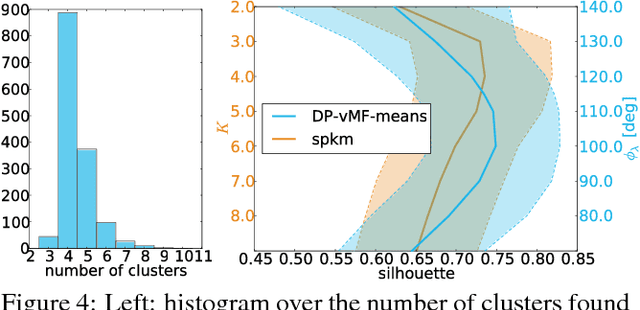
Structural regularities in man-made environments reflect in the distribution of their surface normals. Describing these surface normal distributions is important in many computer vision applications, such as scene understanding, plane segmentation, and regularization of 3D reconstructions. Based on the small-variance limit of Bayesian nonparametric von-Mises-Fisher (vMF) mixture distributions, we propose two new flexible and efficient k-means-like clustering algorithms for directional data such as surface normals. The first, DP-vMF-means, is a batch clustering algorithm derived from the Dirichlet process (DP) vMF mixture. Recognizing the sequential nature of data collection in many applications, we extend this algorithm to DDP-vMF-means, which infers temporally evolving cluster structure from streaming data. Both algorithms naturally respect the geometry of directional data, which lies on the unit sphere. We demonstrate their performance on synthetic directional data and real 3D surface normals from RGB-D sensors. While our experiments focus on 3D data, both algorithms generalize to high dimensional directional data such as protein backbone configurations and semantic word vectors.