 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Learning POMDPs Beyond Full-Rank Actions and State Observability
Jan 26, 2026We are interested in enabling autonomous agents to learn and reason about systems with hidden states, such as furniture with hidden locking mechanisms. We cast this problem as learning the parameters of a discrete Partially Observable Markov Decision Process (POMDP). The agent begins with knowledge of the POMDP's actions and observation spaces, but not its state space, transitions, or observation models. These properties must be constructed from action-observation sequences. Spectral approaches to learning models of partially observable domains, such as learning Predictive State Representations (PSRs), are known to directly estimate the number of hidden states. These methods cannot, however, yield direct estimates of transition and observation likelihoods, which are important for many downstream reasoning tasks. Other approaches leverage tensor decompositions to estimate transition and observation likelihoods but often assume full state observability and full-rank transition matrices for all actions. To relax these assumptions, we study how PSRs learn transition and observation matrices up to a similarity transform, which may be estimated via tensor methods. Our method learns observation matrices and transition matrices up to a partition of states, where the states in a single partition have the same observation distributions corresponding to actions whose transition matrices are full-rank. Our experiments suggest that these partition-level transition models learned by our method, with a sufficient amount of data, meets the performance of PSRs as models to be used by standard sampling-based POMDP solvers. Furthermore, the explicit observation and transition likelihoods can be leveraged to specify planner behavior after the model has been learned.
Linear Memory SE(2) Invariant Attention
Jul 24, 2025Processing spatial data is a key component in many learning tasks for autonomous driving such as motion forecasting, multi-agent simulation, and planning. Prior works have demonstrated the value in using SE(2) invariant network architectures that consider only the relative poses between objects (e.g. other agents, scene features such as traffic lanes). However, these methods compute the relative poses for all pairs of objects explicitly, requiring quadratic memory. In this work, we propose a mechanism for SE(2) invariant scaled dot-product attention that requires linear memory relative to the number of objects in the scene. Our SE(2) invariant transformer architecture enjoys the same scaling properties that have benefited large language models in recent years. We demonstrate experimentally that our approach is practical to implement and improves performance compared to comparable non-invariant architectures.
Language-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Anomalies by Synthesis: Anomaly Detection using Generative Diffusion Models for Off-Road Navigation
May 28, 2025In order to navigate safely and reliably in off-road and unstructured environments, robots must detect anomalies that are out-of-distribution (OOD) with respect to the training data. We present an analysis-by-synthesis approach for pixel-wise anomaly detection without making any assumptions about the nature of OOD data. Given an input image, we use a generative diffusion model to synthesize an edited image that removes anomalies while keeping the remaining image unchanged. Then, we formulate anomaly detection as analyzing which image segments were modified by the diffusion model. We propose a novel inference approach for guided diffusion by analyzing the ideal guidance gradient and deriving a principled approximation that bootstraps the diffusion model to predict guidance gradients. Our editing technique is purely test-time that can be integrated into existing workflows without the need for retraining or fine-tuning. Finally, we use a combination of vision-language foundation models to compare pixels in a learned feature space and detect semantically meaningful edits, enabling accurate anomaly detection for off-road navigation. Project website: https://siddancha.github.io/anomalies-by-diffusion-synthesis/
Streaming Flow Policy: Simplifying diffusion$/$flow-matching policies by treating action trajectories as flow trajectories
May 28, 2025Recent advances in diffusion$/$flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories: a diffusion$/$flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion$/$flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. Project website: https://streaming-flow-policy.github.io/
Learning Attentive Neural Processes for Planning with Pushing Actions
Apr 24, 2025Our goal is to enable robots to plan sequences of tabletop actions to push a block with unknown physical properties to a desired goal pose on the table. We approach this problem by learning the constituent models of a Partially-Observable Markov Decision Process (POMDP), where the robot can observe the outcome of a push, but the physical properties of the block that govern the dynamics remain unknown. The pushing problem is a difficult POMDP to solve due to the challenge of state estimation. The physical properties have a nonlinear relationship with the outcomes, requiring computationally expensive methods, such as particle filters, to represent beliefs. Leveraging the Attentive Neural Process architecture, we propose to replace the particle filter with a neural network that learns the inference computation over the physical properties given a history of actions. This Neural Process is integrated into planning as the Neural Process Tree with Double Progressive Widening (NPT-DPW). Simulation results indicate that NPT-DPW generates more effective plans faster than traditional particle filter methods, even in complex pushing scenarios.
Belief Roadmaps with Uncertain Landmark Evanescence
Jan 29, 2025



We would like a robot to navigate to a goal location while minimizing state uncertainty. To aid the robot in this endeavor, maps provide a prior belief over the location of objects and regions of interest. To localize itself within the map, a robot identifies mapped landmarks using its sensors. However, as the time between map creation and robot deployment increases, portions of the map can become stale, and landmarks, once believed to be permanent, may disappear. We refer to the propensity of a landmark to disappear as landmark evanescence. Reasoning about landmark evanescence during path planning, and the associated impact on localization accuracy, requires analyzing the presence or absence of each landmark, leading to an exponential number of possible outcomes of a given motion plan. To address this complexity, we develop BRULE, an extension of the Belief Roadmap. During planning, we replace the belief over future robot poses with a Gaussian mixture which is able to capture the effects of landmark evanescence. Furthermore, we show that belief updates can be made efficient, and that maintaining a random subset of mixture components is sufficient to find high quality solutions. We demonstrate performance in simulated and real-world experiments. Software is available at https://bit.ly/BRULE.
Semi-Supervised Neural Processes for Articulated Object Interactions
Nov 28, 2024



The scarcity of labeled action data poses a considerable challenge for developing machine learning algorithms for robotic object manipulation. It is expensive and often infeasible for a robot to interact with many objects. Conversely, visual data of objects, without interaction, is abundantly available and can be leveraged for pretraining and feature extraction. However, current methods that rely on image data for pretraining do not easily adapt to task-specific predictions, since the learned features are not guaranteed to be relevant. This paper introduces the Semi-Supervised Neural Process (SSNP): an adaptive reward-prediction model designed for scenarios in which only a small subset of objects have labeled interaction data. In addition to predicting reward labels, the latent-space of the SSNP is jointly trained with an autoencoding objective using passive data from a much larger set of objects. Jointly training with both types of data allows the model to focus more effectively on generalizable features and minimizes the need for extensive retraining, thereby reducing computational demands. The efficacy of SSNP is demonstrated through a door-opening task, leading to better performance than other semi-supervised methods, and only using a fraction of the data compared to other adaptive models.
PIETRA: Physics-Informed Evidential Learning for Traversing Out-of-Distribution Terrain
Sep 04, 2024
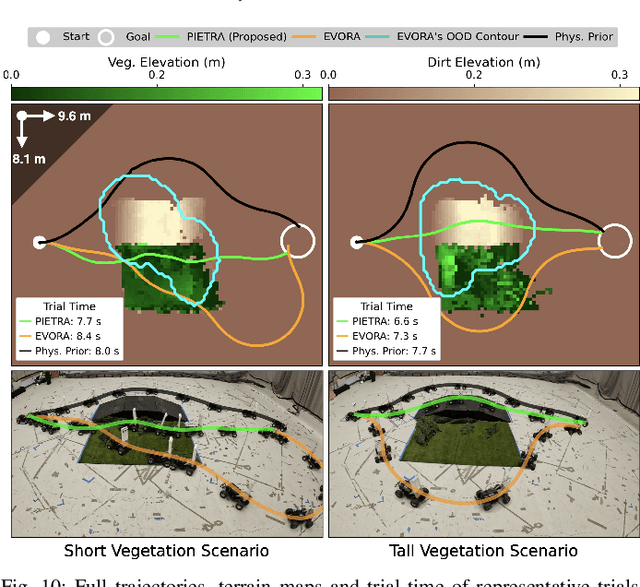
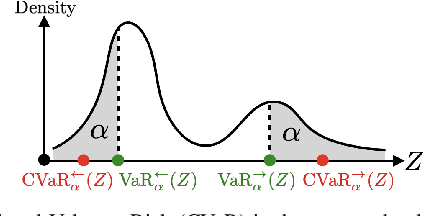
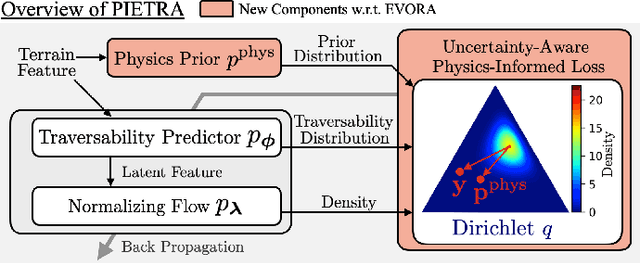
Self-supervised learning is a powerful approach for developing traversability models for off-road navigation, but these models often struggle with inputs unseen during training. Existing methods utilize techniques like evidential deep learning to quantify model uncertainty, helping to identify and avoid out-of-distribution terrain. However, always avoiding out-of-distribution terrain can be overly conservative, e.g., when novel terrain can be effectively analyzed using a physics-based model. To overcome this challenge, we introduce Physics-Informed Evidential Traversability (PIETRA), a self-supervised learning framework that integrates physics priors directly into the mathematical formulation of evidential neural networks and introduces physics knowledge implicitly through an uncertainty-aware, physics-informed training loss. Our evidential network seamlessly transitions between learned and physics-based predictions for out-of-distribution inputs. Additionally, the physics-informed loss regularizes the learned model, ensuring better alignment with the physics model. Extensive simulations and hardware experiments demonstrate that PIETRA improves both learning accuracy and navigation performance in environments with significant distribution shifts.
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
Aug 08, 2024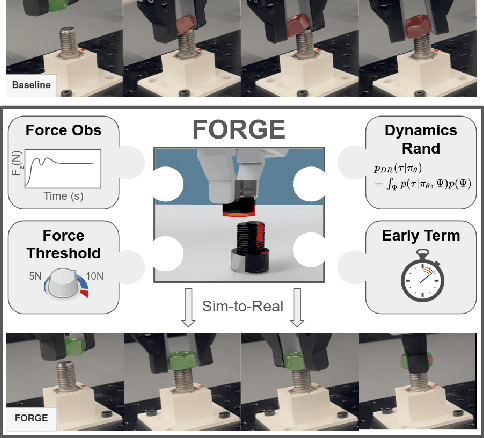

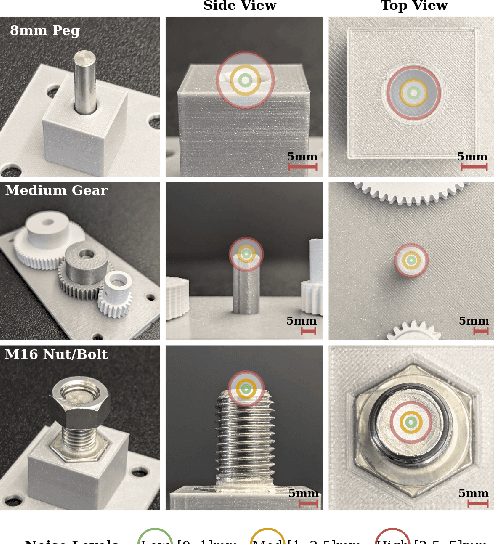
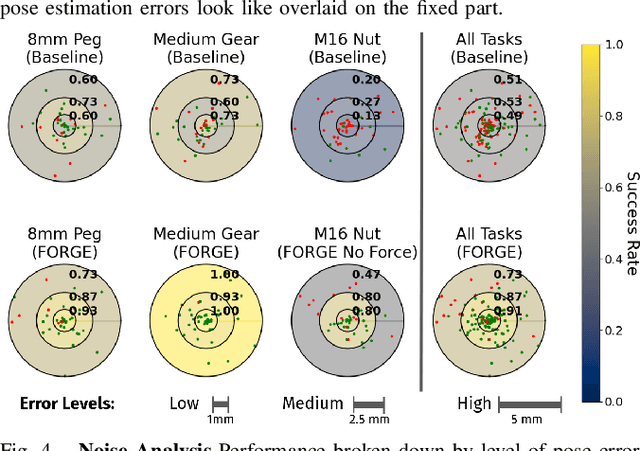
We present FORGE, a method that enables sim-to-real transfer of contact-rich manipulation policies in the presence of significant pose uncertainty. FORGE combines a force threshold mechanism with a dynamics randomization scheme during policy learning in simulation, to enable the robust transfer of the learned policies to the real robot. At deployment, FORGE policies, conditioned on a maximum allowable force, adaptively perform contact-rich tasks while respecting the specified force threshold, regardless of the controller gains. Additionally, FORGE autonomously predicts a termination action once the task has succeeded. We demonstrate that FORGE can be used to learn a variety of robust contact-rich policies, enabling multi-stage assembly of a planetary gear system, which requires success across three assembly tasks: nut-threading, insertion, and gear meshing. Project website can be accessed at https://noseworm.github.io/forge/.