 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Deployment of a Hierarchical Uncertainty-Aware Collaborative Multiagent Planning System
Apr 26, 2024We would like to enable a collaborative multiagent team to navigate at long length scales and under uncertainty in real-world environments. In practice, planning complexity scales with the number of agents in the team, with the length scale of the environment, and with environmental uncertainty. Enabling tractable planning requires developing abstract models that can represent complex, high-quality plans. However, such models often abstract away information needed to generate directly-executable plans for real-world agents in real-world environments, as planning in such detail, especially in the presence of real-world uncertainty, would be computationally intractable. In this paper, we describe the deployment of a planning system that used a hierarchy of planners to execute collaborative multiagent navigation tasks in real-world, unknown environments. By developing a planning system that was robust to failures at every level of the planning hierarchy, we enabled the team to complete collaborative navigation tasks, even in the presence of imperfect planning abstractions and real-world uncertainty. We deployed our approach on a Clearpath Husky-Jackal team navigating in a structured outdoor environment, and demonstrated that the system enabled the agents to successfully execute collaborative plans.
The Holy Grail of Multi-Robot Planning: Learning to Generate Online-Scalable Solutions from Offline-Optimal Experts
Jul 26, 2021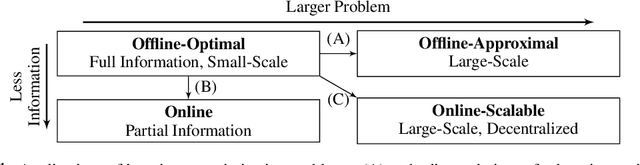
Many multi-robot planning problems are burdened by the curse of dimensionality, which compounds the difficulty of applying solutions to large-scale problem instances. The use of learning-based methods in multi-robot planning holds great promise as it enables us to offload the online computational burden of expensive, yet optimal solvers, to an offline learning procedure. Simply put, the idea is to train a policy to copy an optimal pattern generated by a small-scale system, and then transfer that policy to much larger systems, in the hope that the learned strategy scales, while maintaining near-optimal performance. Yet, a number of issues impede us from leveraging this idea to its full potential. This blue-sky paper elaborates some of the key challenges that remain.
Composable Learning with Sparse Kernel Representations
Mar 29, 2021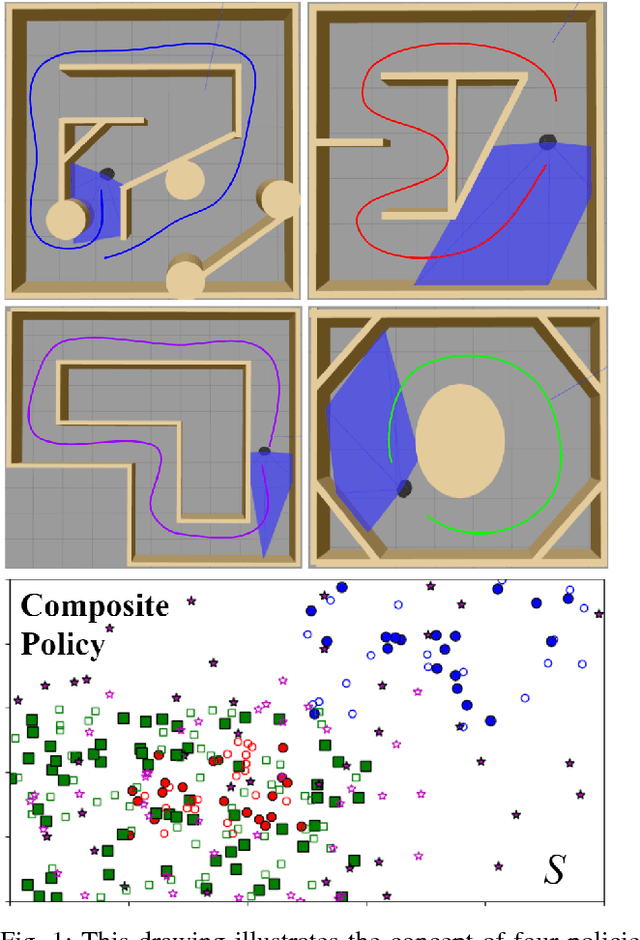



We present a reinforcement learning algorithm for learning sparse non-parametric controllers in a Reproducing Kernel Hilbert Space. We improve the sample complexity of this approach by imposing a structure of the state-action function through a normalized advantage function (NAF). This representation of the policy enables efficiently composing multiple learned models without additional training samples or interaction with the environment. We demonstrate the performance of this algorithm on learning obstacle-avoidance policies in multiple simulations of a robot equipped with a laser scanner while navigating in a 2D environment. We apply the composition operation to various policy combinations and test them to show that the composed policies retain the performance of their components. We also transfer the composed policy directly to a physical platform operating in an arena with obstacles in order to demonstrate a degree of generalization.
Grounding Natural Language Commands to StarCraft II Game States for Narration-Guided Reinforcement Learning
Apr 24, 2019While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of {\em reward sparsity}. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we investigate to what extent we can contextualize these narrations by grounding them to the goal-specific states. We present a mutual-embedding model using a multi-input deep-neural network that projects a sequence of natural language commands into the same high-dimensional representation space as corresponding goal states. We show that using this model we can learn an embedding space with separable and distinct clusters that accurately maps natural-language commands to corresponding game states . We also discuss how this model can allow for the use of narrations as a robust form of reward shaping to improve RL performance and efficiency.
Intelligent Autonomous Things on the Battlefield
Feb 26, 2019


Numerous, artificially intelligent, networked things will populate the battlefield of the future, operating in close collaboration with human warfighters, and fighting as teams in highly adversarial environments. This chapter explores the characteristics, capabilities and intelli-gence required of such a network of intelligent things and humans - Internet of Battle Things (IOBT). The IOBT will experience unique challenges that are not yet well addressed by the current generation of AI and machine learning.
* This is a much expanded version of an earlier conference paper available at arXiv:803.11256
Nonparametric Stochastic Compositional Gradient Descent for Q-Learning in Continuous Markov Decision Problems
Apr 19, 2018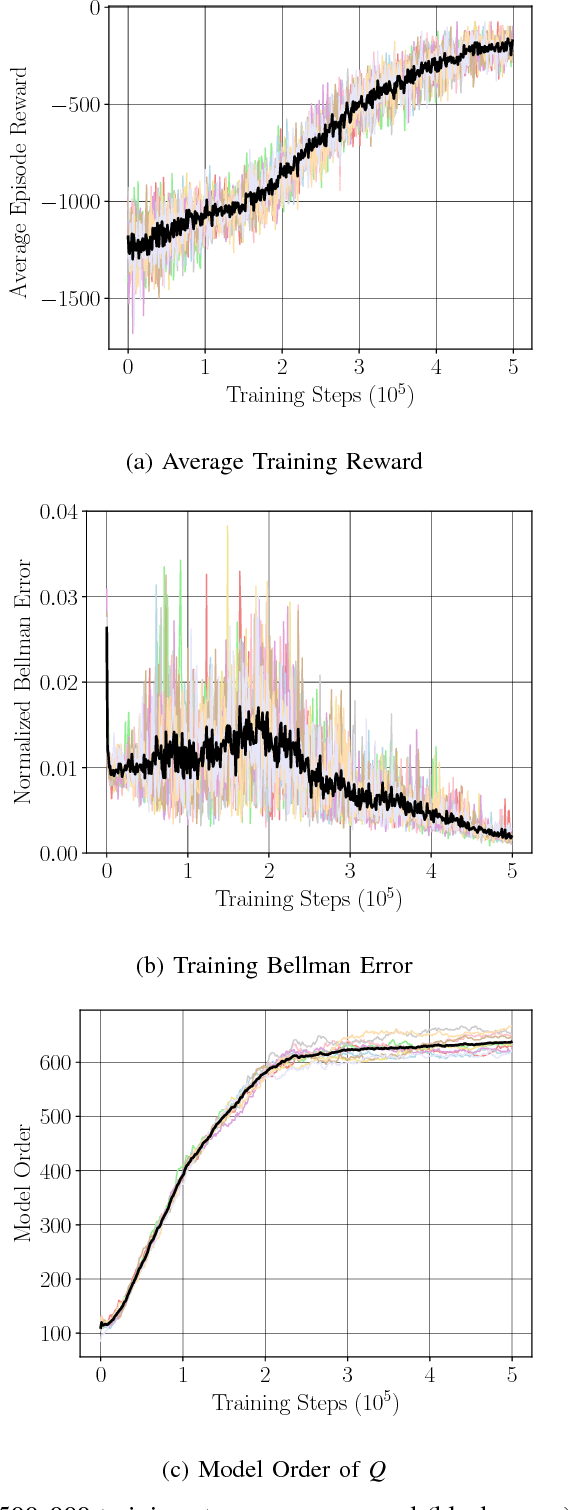
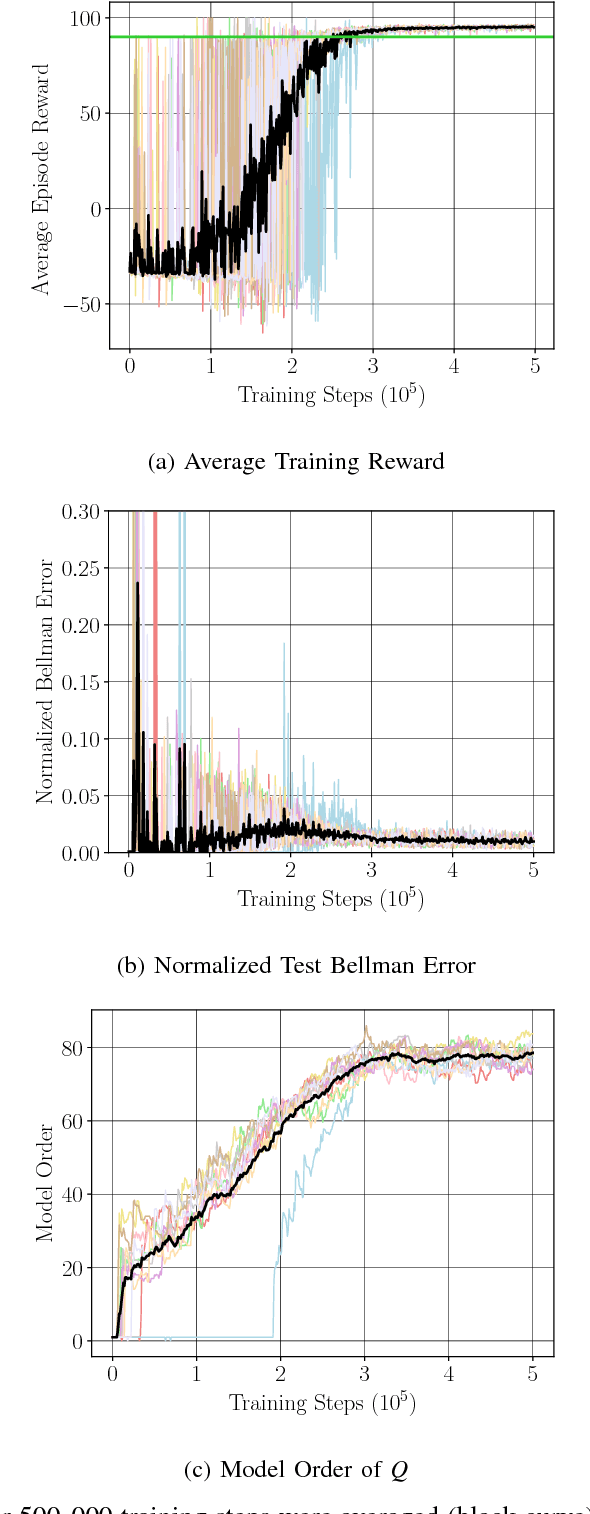
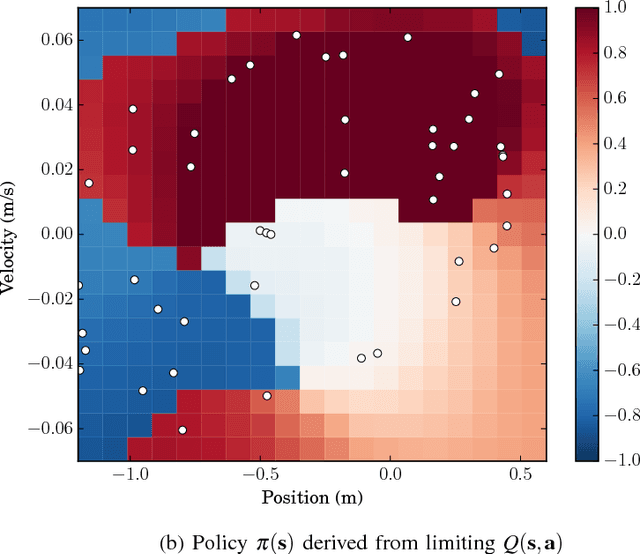
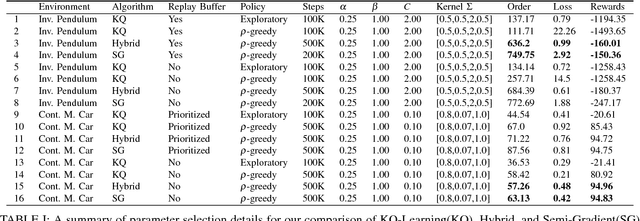
We consider Markov Decision Problems defined over continuous state and action spaces, where an autonomous agent seeks to learn a map from its states to actions so as to maximize its long-term discounted accumulation of rewards. We address this problem by considering Bellman's optimality equation defined over action-value functions, which we reformulate into a nested non-convex stochastic optimization problem defined over a Reproducing Kernel Hilbert Space (RKHS). We develop a functional generalization of stochastic quasi-gradient method to solve it, which, owing to the structure of the RKHS, admits a parameterization in terms of scalar weights and past state-action pairs which grows proportionately with the algorithm iteration index. To ameliorate this complexity explosion, we apply Kernel Orthogonal Matching Pursuit to the sequence of kernel weights and dictionaries, which yields a controllable error in the descent direction of the underlying optimization method. We prove that the resulting algorithm, called KQ-Learning, converges with probability 1 to a stationary point of this problem, yielding a fixed point of the Bellman optimality operator under the hypothesis that it belongs to the RKHS. Under constant learning rates, we further obtain convergence to a small Bellman error that depends on the chosen learning rates. Numerical evaluation on the Continuous Mountain Car and Inverted Pendulum tasks yields convergent parsimonious learned action-value functions, policies that are competitive with the state of the art, and exhibit reliable, reproducible learning behavior.
Parsimonious Online Learning with Kernels via Sparse Projections in Function Space
Dec 13, 2016

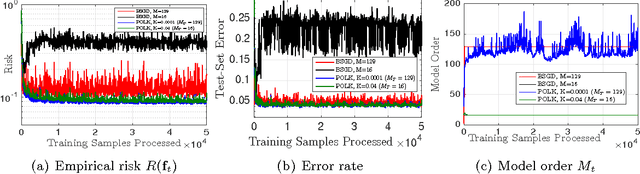

Despite their attractiveness, popular perception is that techniques for nonparametric function approximation do not scale to streaming data due to an intractable growth in the amount of storage they require. To solve this problem in a memory-affordable way, we propose an online technique based on functional stochastic gradient descent in tandem with supervised sparsification based on greedy function subspace projections. The method, called parsimonious online learning with kernels (POLK), provides a controllable tradeoff? between its solution accuracy and the amount of memory it requires. We derive conditions under which the generated function sequence converges almost surely to the optimal function, and we establish that the memory requirement remains finite. We evaluate POLK for kernel multi-class logistic regression and kernel hinge-loss classification on three canonical data sets: a synthetic Gaussian mixture model, the MNIST hand-written digits, and the Brodatz texture database. On all three tasks, we observe a favorable tradeoff of objective function evaluation, classification performance, and complexity of the nonparametric regressor extracted the proposed method.
Decentralized Dynamic Discriminative Dictionary Learning
May 03, 2016

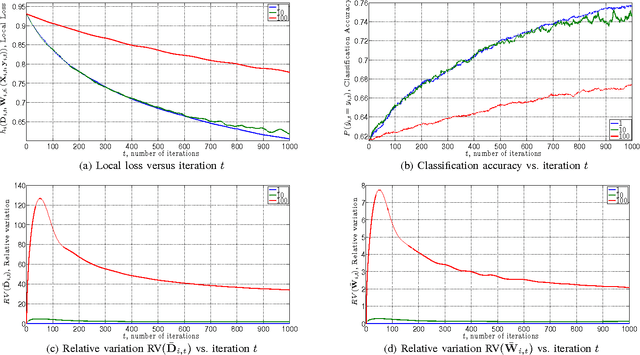
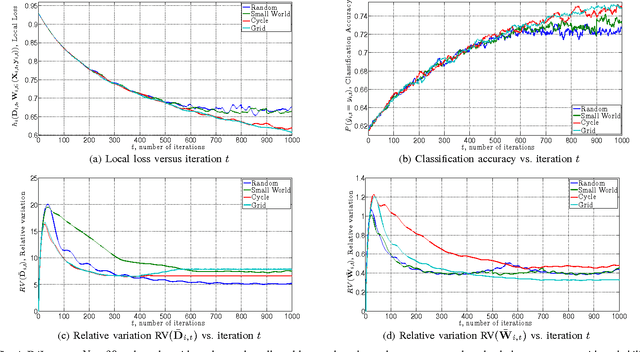
We consider discriminative dictionary learning in a distributed online setting, where a network of agents aims to learn a common set of dictionary elements of a feature space and model parameters while sequentially receiving observations. We formulate this problem as a distributed stochastic program with a non-convex objective and present a block variant of the Arrow-Hurwicz saddle point algorithm to solve it. Using Lagrange multipliers to penalize the discrepancy between them, only neighboring nodes exchange model information. We show that decisions made with this saddle point algorithm asymptotically achieve a first-order stationarity condition on average.