 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Merging on Loss Landscape: A Geometry Perspective
May 26, 2026Model merging offers a promising avenue for knowledge integration and parallel development without retraining. Yet, existing methods either ignore the geometry of the loss landscape or rely on intractable full-space Hessian approximations. We propose EpiMer, a framework that casts model merging as solving the Fréchet mean on a Riemannian manifold and restricts the computation to a low-rank subspace spanned by the task vectors. With the expected Hessian as the metric, we reveal a connection between local curvature and epistemic uncertainty of the parameters. Our theoretical analysis decomposes the merging error bound into the subspace Fréchet variance and the residual energy, and provides a closed-form characterization of when curvature-aware merging provably outperforms flat-geometry methods. In addition, our framework unifies both curvature-aware methods and recent spectral methods as special cases of the subspace Fréchet mean with different geometric metrics. Merging fine-tuned CLIP-ViT models on eight image classification tasks, Epistemic Merging strictly outperforms the baselines on all three CLIP-ViT backbones at matched rank, improving the across-task average accuracy and worst-task accuracy on every backbone.
Identifying Driver Interactions via Conditional Behavior Prediction
Apr 20, 2021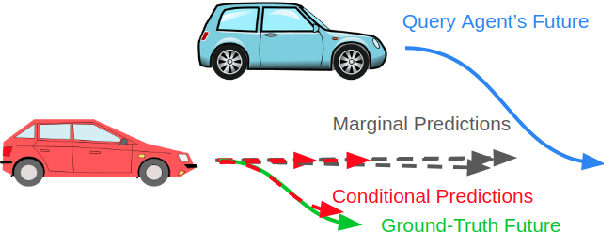
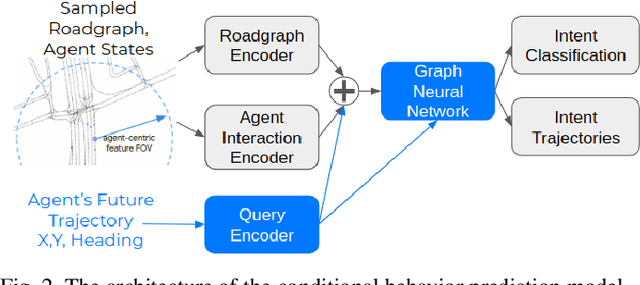
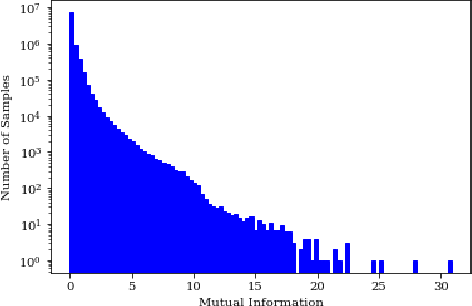
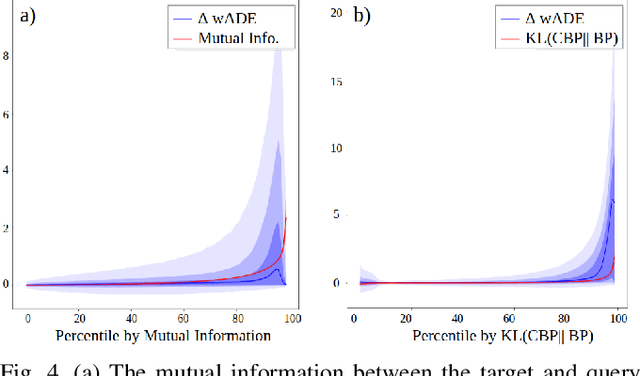
Interactive driving scenarios, such as lane changes, merges and unprotected turns, are some of the most challenging situations for autonomous driving. Planning in interactive scenarios requires accurately modeling the reactions of other agents to different future actions of the ego agent. We develop end-to-end models for conditional behavior prediction (CBP) that take as an input a query future trajectory for an ego-agent, and predict distributions over future trajectories for other agents conditioned on the query. Leveraging such a model, we develop a general-purpose agent interactivity score derived from probabilistic first principles. The interactivity score allows us to find interesting interactive scenarios for training and evaluating behavior prediction models. We further demonstrate that the proposed score is effective for agent prioritization under computational budget constraints.
Composable Learning with Sparse Kernel Representations
Mar 29, 2021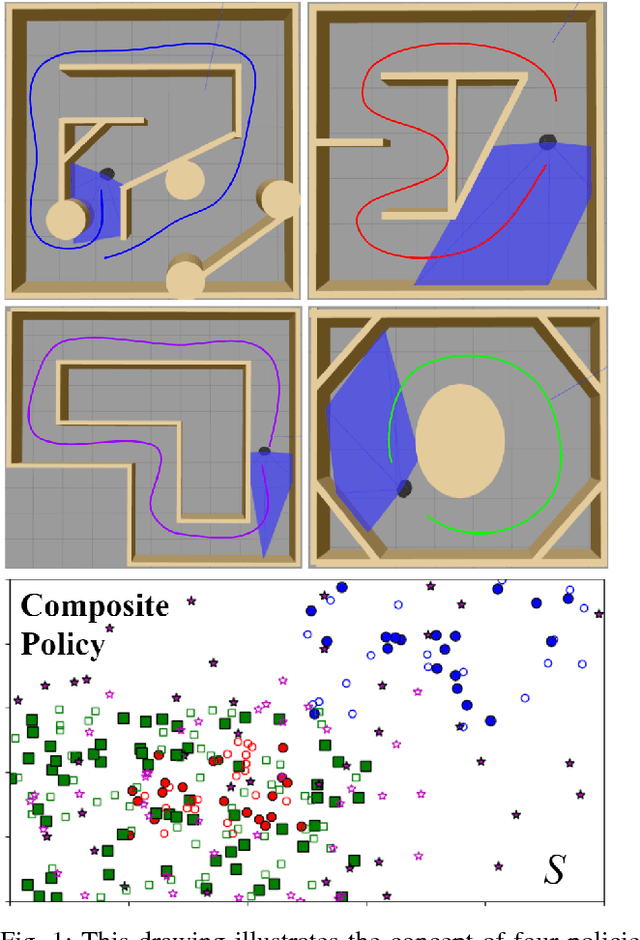



We present a reinforcement learning algorithm for learning sparse non-parametric controllers in a Reproducing Kernel Hilbert Space. We improve the sample complexity of this approach by imposing a structure of the state-action function through a normalized advantage function (NAF). This representation of the policy enables efficiently composing multiple learned models without additional training samples or interaction with the environment. We demonstrate the performance of this algorithm on learning obstacle-avoidance policies in multiple simulations of a robot equipped with a laser scanner while navigating in a 2D environment. We apply the composition operation to various policy combinations and test them to show that the composed policies retain the performance of their components. We also transfer the composed policy directly to a physical platform operating in an arena with obstacles in order to demonstrate a degree of generalization.
Learning Connectivity for Data Distribution in Robot Teams
Mar 08, 2021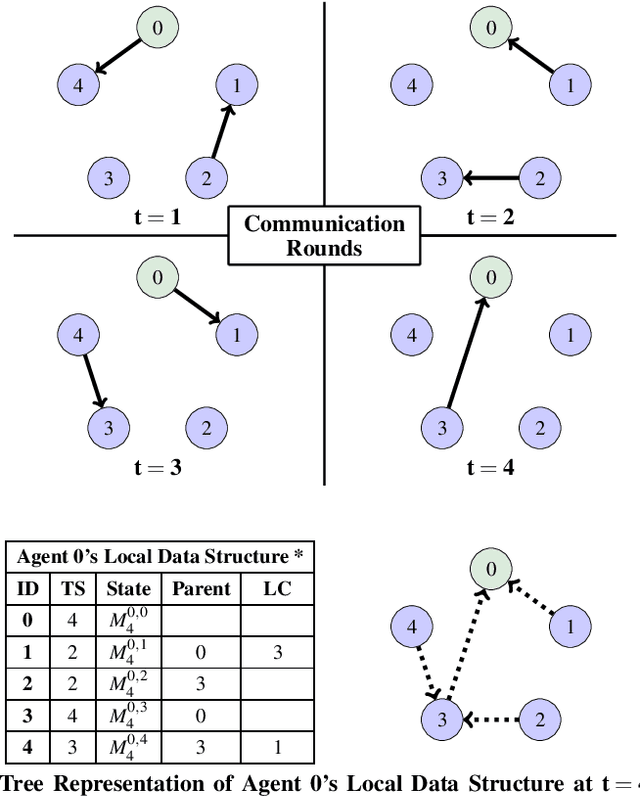

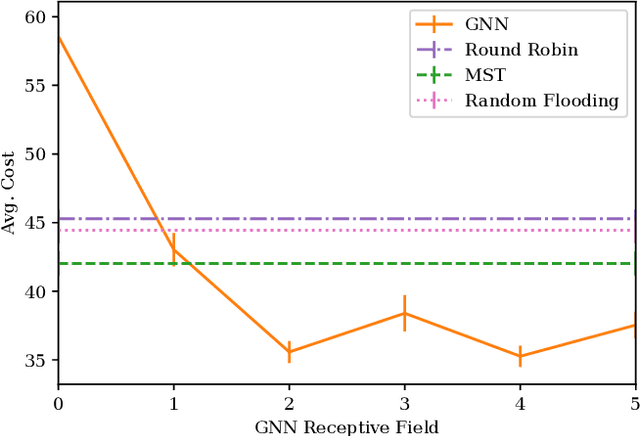
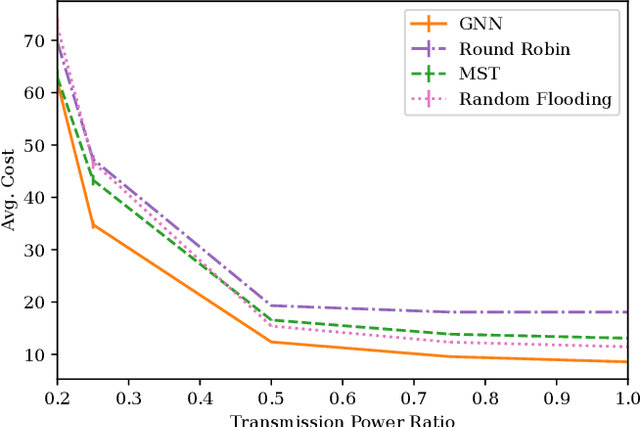
Many algorithms for control of multi-robot teams operate under the assumption that low-latency, global state information necessary to coordinate agent actions can readily be disseminated among the team. However, in harsh environments with no existing communication infrastructure, robots must form ad-hoc networks, forcing the team to operate in a distributed fashion. To overcome this challenge, we propose a task-agnostic, decentralized, low-latency method for data distribution in ad-hoc networks using Graph Neural Networks (GNN). Our approach enables multi-agent algorithms based on global state information to function by ensuring it is available at each robot. To do this, agents glean information about the topology of the network from packet transmissions and feed it to a GNN running locally which instructs the agent when and where to transmit the latest state information. We train the distributed GNN communication policies via reinforcement learning using the average Age of Information as the reward function and show that it improves training stability compared to task-specific reward functions. Our approach performs favorably compared to industry-standard methods for data distribution such as random flooding and round robin. We also show that the trained policies generalize to larger teams of both static and mobile agents.
Decentralized Control with Graph Neural Networks
Dec 29, 2020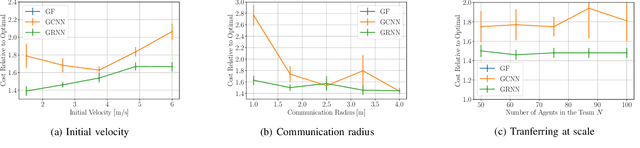
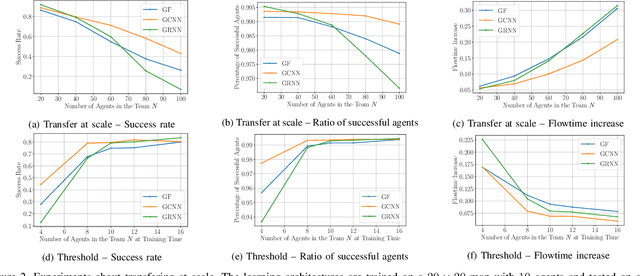
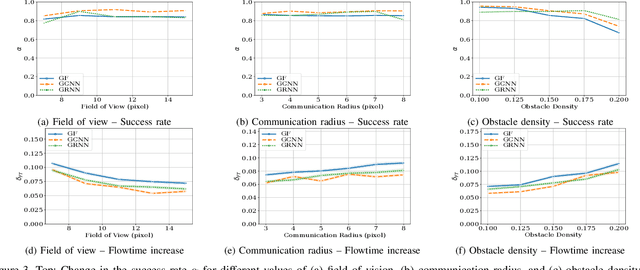

Dynamical systems consisting of a set of autonomous agents face the challenge of having to accomplish a global task, relying only on local information. While centralized controllers are readily available, they face limitations in terms of scalability and implementation, as they do not respect the distributed information structure imposed by the network system of agents. Given the difficulties in finding optimal decentralized controllers, we propose a novel framework using graph neural networks (GNNs) to learn these controllers. GNNs are well-suited for the task since they are naturally distributed architectures and exhibit good scalability and transferability properties. The problems of flocking and multi-agent path planning are explored to illustrate the potential of GNNs in learning decentralized controllers.
Multi-Robot Coverage and Exploration using Spatial Graph Neural Networks
Nov 02, 2020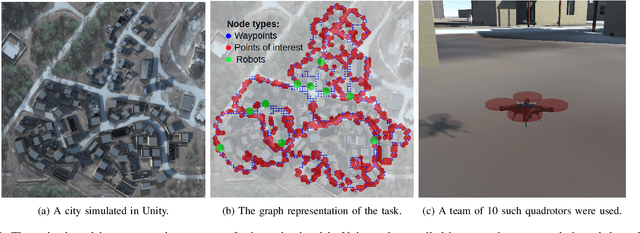
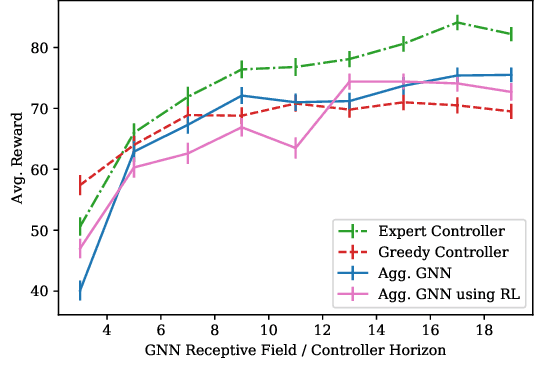
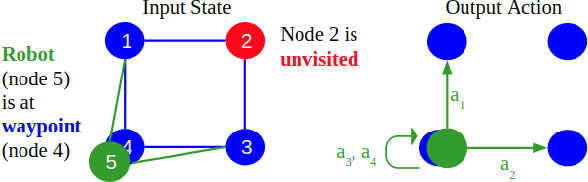
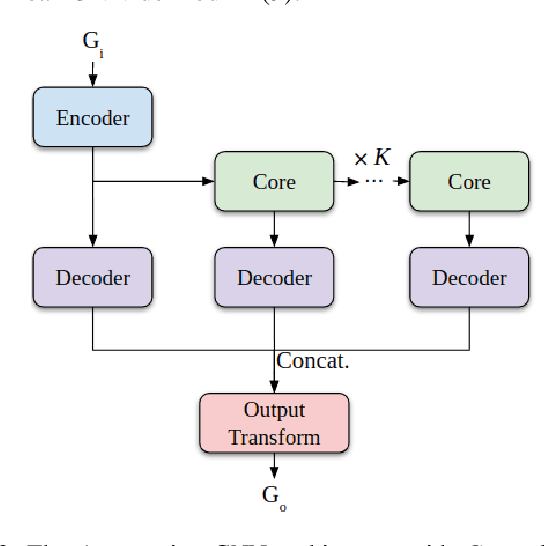
The multi-robot coverage problem is an essential building block for systems that perform tasks like inspection or search and rescue. We discretize the coverage problem to induce a spatial graph of locations and represent robots as nodes in the graph. Then, we train a Graph Neural Network controller that leverages the spatial equivariance of the task to imitate an expert open-loop routing solution. This approach generalizes well to much larger maps and larger teams that are intractable for the expert. In particular, the model generalizes effectively to a simulation of ten quadrotors and dozens of buildings. We also demonstrate the GNN controller can surpass planning-based approaches in an exploration task.
Graph Neural Networks for Decentralized Controllers
Mar 23, 2020
Dynamical systems comprised of autonomous agents arise in many relevant problems such as multi-agent robotics, smart grids, or smart cities. Controlling these systems is of paramount importance to guarantee a successful deployment. Optimal centralized controllers are readily available but face limitations in terms of scalability and practical implementation. Optimal decentralized controllers, on the other hand, are difficult to find. In this paper, we use graph neural networks (GNNs) to learn decentralized controllers from data. GNNs are well-suited for the task since they are naturally distributed architectures. Furthermore, they are equivariant and stable, leading to good scalability and transferability properties. The problem of flocking is explored to illustrate the power of GNNs in learning decentralized controllers.
Graph Policy Gradients for Large Scale Robot Control
Jul 11, 2019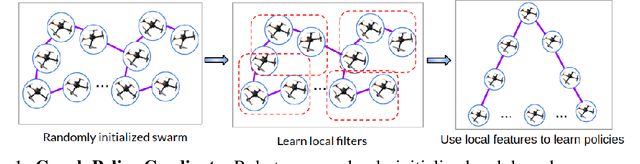



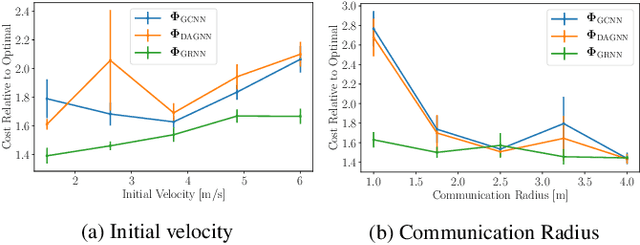
In this paper, we consider the problem of learning policies to control a large number of homogeneous robots. To this end, we propose a new algorithm we call Graph Policy Gradients (GPG) that exploits the underlying graph symmetry among the robots. The curse of dimensionality one encounters when working with a large number of robots is mitigated by employing a graph convolutional neural (GCN) network to parametrize policies for the robots. The GCN reduces the dimensionality of the problem by learning filters that aggregate information among robots locally, similar to how a convolutional neural network is able to learn local features in an image. Through experiments on formation flying, we show that our proposed method is able to scale better than existing reinforcement methods that employ fully connected networks. More importantly, we show that by using our locally learned filters we are able to zero-shot transfer policies trained on just three robots to over hundred robots.
Learning Decentralized Controllers for Robot Swarms with Graph Neural Networks
Mar 25, 2019

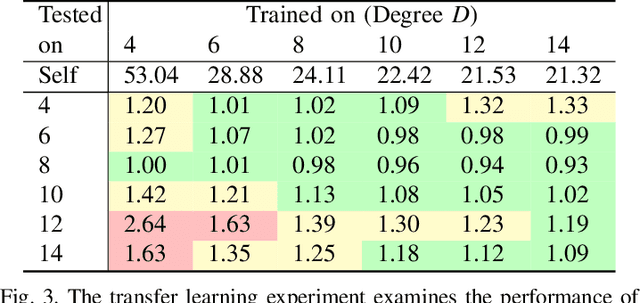

We consider the problem of finding distributed controllers for large networks of mobile robots with interacting dynamics and sparsely available communications. Our approach is to learn local controllers which require only local information and local communications at test time by imitating the policy of centralized controllers using global information at training time. By extending aggregation graph neural networks to time varying signals and time varying network support, we learn a single common local controller which exploits information from distant teammates using only local communication interchanges. We apply this approach to a decentralized linear quadratic regulator problem and observe how faster communication rates and smaller network degree increase the value of multi-hop information. Separate experiments learning a decentralized flocking controller demonstrate performance on communication graphs that change as the robots move.
Inverse Optimal Planning for Air Traffic Control
Mar 25, 2019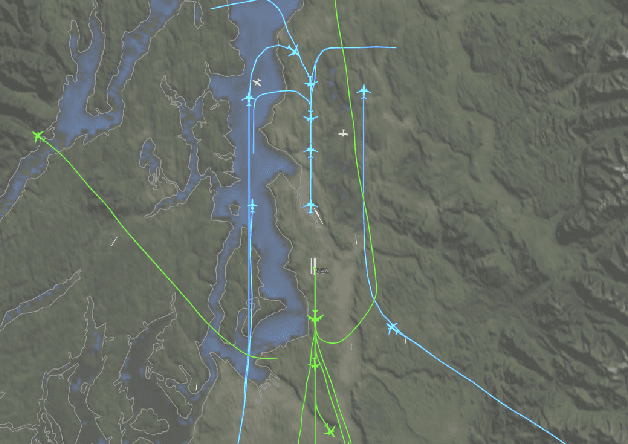

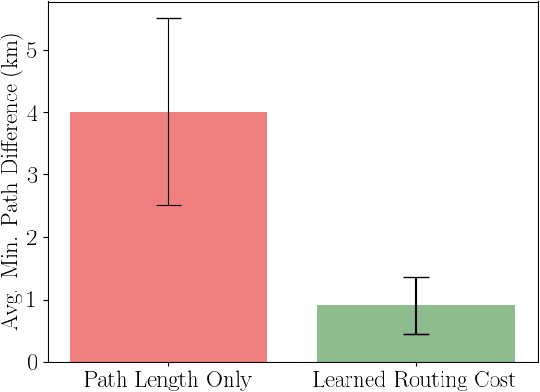
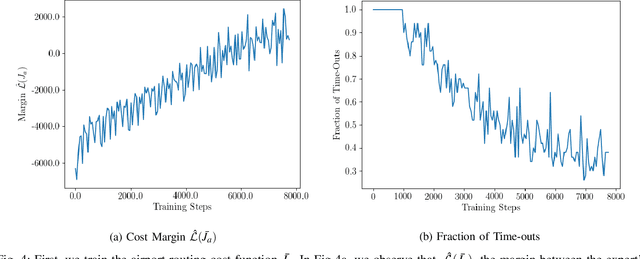
We envision a system that concisely describes the rules of air traffic control, assists human operators and supports dense autonomous air traffic around commercial airports. We develop a method to learn the rules of air traffic control from real data as a cost function via maximum entropy inverse reinforcement learning. This cost function is used as a penalty for a search-based motion planning method that discretizes both the control and the state space. We illustrate the methodology by showing that our approach can learn to imitate the airport arrival routes and separation rules of dense commercial air traffic. The resulting trajectories are shown to be safe, feasible, and efficient.