 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Distributed Collaborative Unlabeled Motion Planning with Graph Policy Gradients
Feb 11, 2021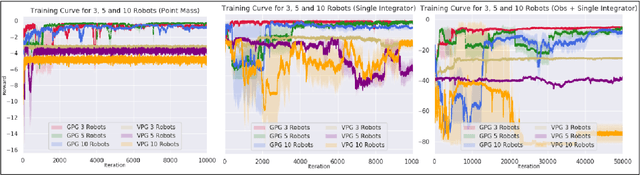
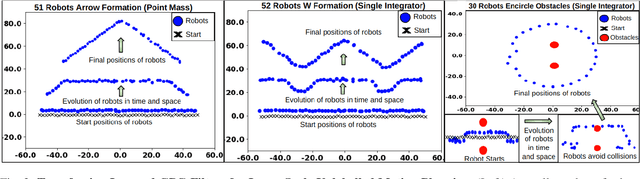
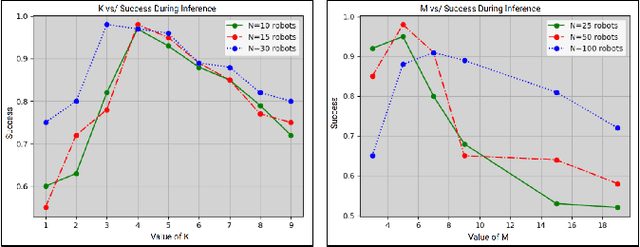
In this paper, we present a learning method to solve the unlabelled motion problem with motion constraints and space constraints in 2D space for a large number of robots. To solve the problem of arbitrary dynamics and constraints we propose formulating the problem as a multi-agent problem. We are able to demonstrate the scalability of our methods for a large number of robots by employing a graph neural network (GNN) to parameterize policies for the robots. The GNN reduces the dimensionality of the problem by learning filters that aggregate information among robots locally, similar to how a convolutional neural network is able to learn local features in an image. Additionally, by employing a GNN we are also able to overcome the computational overhead of training policies for a large number of robots by first training graph filters for a small number of robots followed by zero-shot policy transfer to a larger number of robots. We demonstrate the effectiveness of our framework through various simulations.
Graph Neural Networks for Motion Planning
Jun 11, 2020
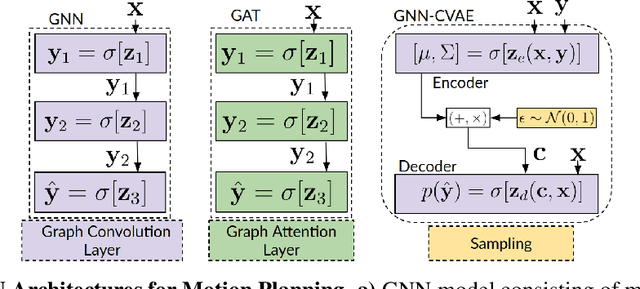
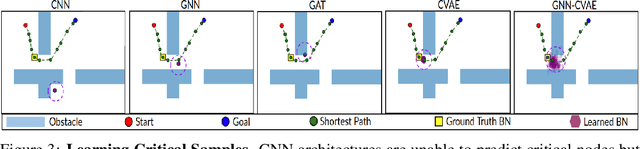
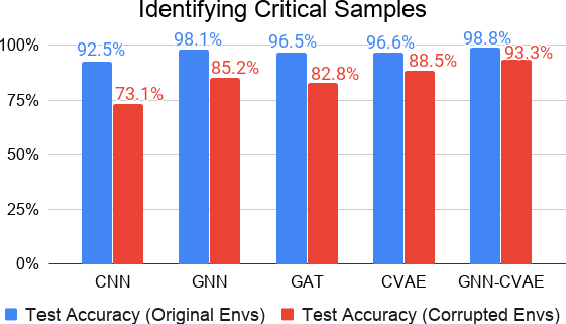
This paper investigates the feasibility of using Graph Neural Networks (GNNs) for classical motion planning problems. Planning algorithms that search through discrete spaces as well as continuous ones are studied. This paper proposes using GNNs to guide the search algorithm by exploiting the ability of GNNs to extract low level information about the topology of a planning space. We present two techniques, GNNs over dense fixed graphs for low-dimensional problems and sampling-based GNNs for high-dimensional problems. We examine the ability of a GNN to tackle planning problems that are heavily dependent on the topology of the space such as identifying critical nodes, learning a heuristic that guides exploration in $\text{A}^*$, and learning the sampling distribution in Rapidly-exploring Random Trees (RRT). We demonstrate that GNNs can offer better results when compared to traditional analytic methods as well as learning-based approaches that employ fully-connected networks or convolutional neural networks.
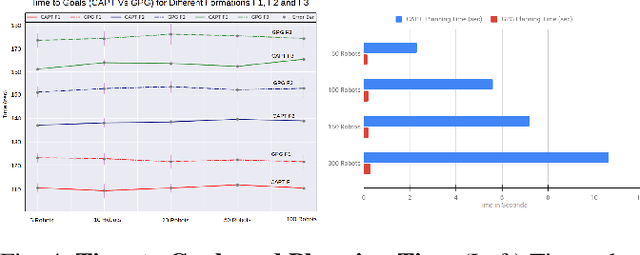
Graph Policy Gradients for Large Scale Unlabeled Motion Planning with Constraints
Sep 24, 2019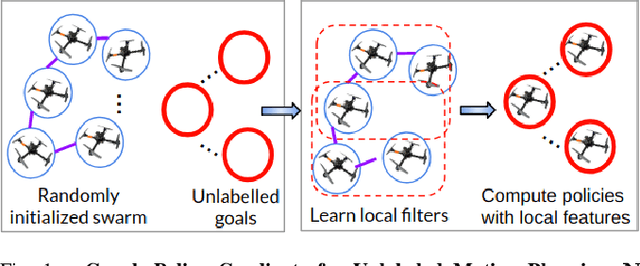

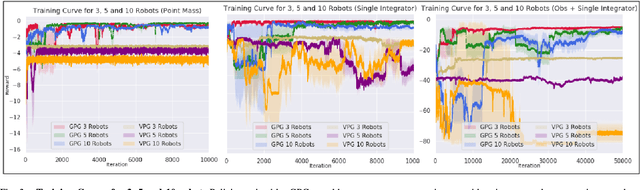
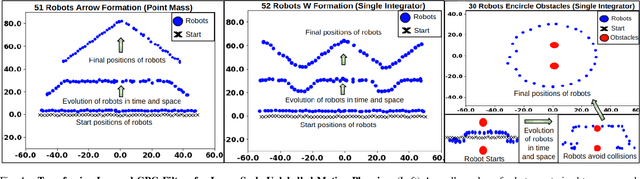
In this paper, we present a learning method to solve the unlabelled motion problem with motion constraints and space constraints in 2D space for a large number of robots. To solve the problem of arbitrary dynamics and constraints we propose formulating the problem as a multi-agent problem. In contrast to previous works that propose using learning solutions for unlabelled motion planning with constraints, we are able to demonstrate the scalability of our methods for a large number of robots. The curse of dimensionality one encounters when working with a large number of robots is mitigated by employing a graph convolutional neural (GCN) network to parametrize policies for the robots. The GCN reduces the dimensionality of the problem by learning filters that aggregate information among robots locally, similar to how a convolutional neural network is able to learn local features in an image. Additionally, by employing a GCN we are also able to overcome the computational overhead of training policies for a large number of robots by first training graph filters for a small number of robots followed by zero-shot policy transfer to a larger number of robots. We demonstrate the effectiveness of our framework through various simulations.
Learning Safe Unlabeled Multi-Robot Planning with Motion Constraints
Jul 11, 2019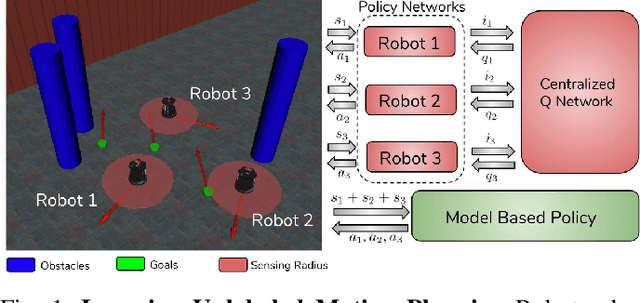
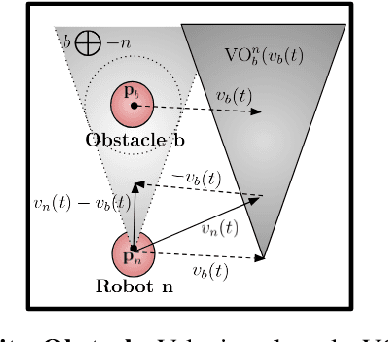
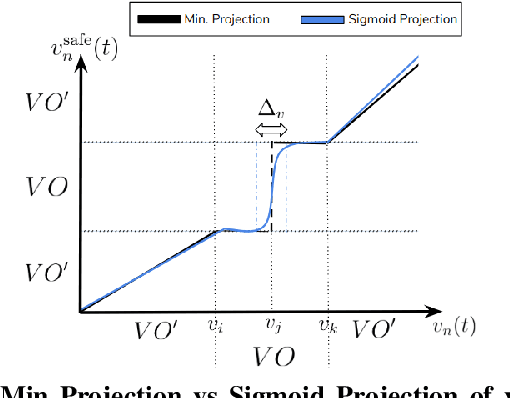
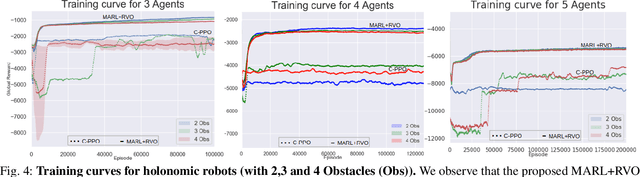
In this paper, we present a learning approach to goal assignment and trajectory planning for unlabeled robots operating in 2D, obstacle-filled workspaces. More specifically, we tackle the unlabeled multi-robot motion planning problem with motion constraints as a multi-agent reinforcement learning problem with some sparse global reward. In contrast with previous works, which formulate an entirely new hand-crafted optimization cost or trajectory generation algorithm for a different robot dynamic model, our framework is a general approach that is applicable to arbitrary robot models. Further, by using the velocity obstacle, we devise a smooth projection that guarantees collision free trajectories for all robots with respect to their neighbors and obstacles. The efficacy of our algorithm is demonstrated through varied simulations.
Graph Policy Gradients for Large Scale Robot Control
Jul 11, 2019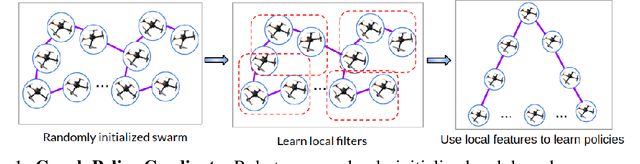



In this paper, we consider the problem of learning policies to control a large number of homogeneous robots. To this end, we propose a new algorithm we call Graph Policy Gradients (GPG) that exploits the underlying graph symmetry among the robots. The curse of dimensionality one encounters when working with a large number of robots is mitigated by employing a graph convolutional neural (GCN) network to parametrize policies for the robots. The GCN reduces the dimensionality of the problem by learning filters that aggregate information among robots locally, similar to how a convolutional neural network is able to learn local features in an image. Through experiments on formation flying, we show that our proposed method is able to scale better than existing reinforcement methods that employ fully connected networks. More importantly, we show that by using our locally learned filters we are able to zero-shot transfer policies trained on just three robots to over hundred robots.
Learning Task Agnostic Sufficiently Accurate Models
Feb 19, 2019
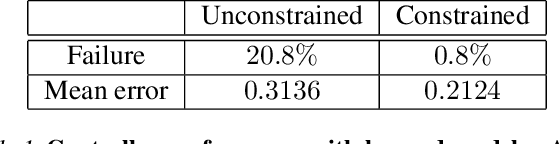
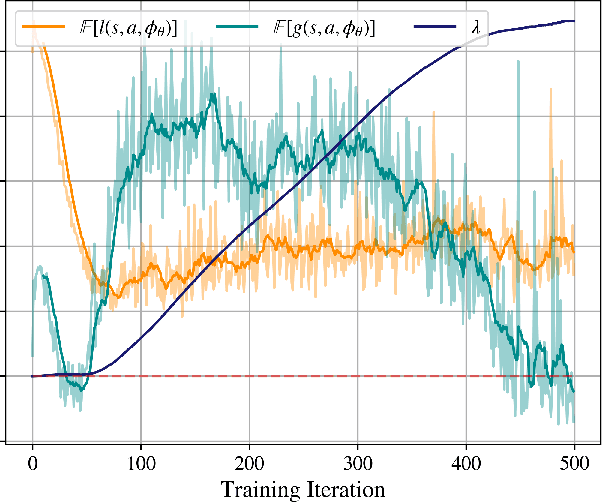
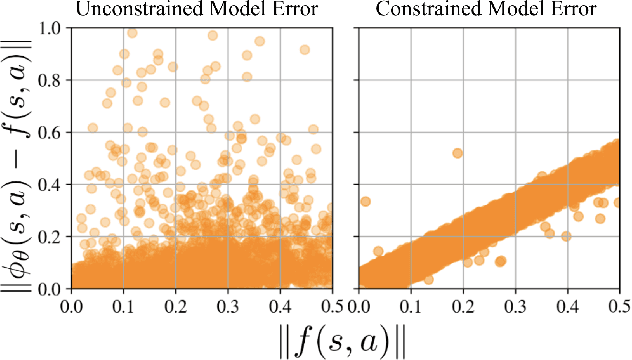
For complex real-world systems, designing controllers are a difficult task. With the advent of neural networks as a proxy for complex function approximators, it has become popular to learn the controller directly. However, these controllers are specific to a given task and need to be relearned for a new task. Alternatively, one can learn just the model of the dynamical system and compose it with external controllers. Such a model is task (and controller) agnostic and must generalize well across the state space. This paper proposes learning a "sufficiently accurate" model of the dynamics that explicitly enforces small residual error on pre-defined parts of the state-space. We formulate task agnostic controller design for this learned model as an optimization problem with state and control constraints that is solved in an online fashion. We validate this approach in simulation using a challenging contact-based Ball-Paddle system.
Scalable Centralized Deep Multi-Agent Reinforcement Learning via Policy Gradients
May 22, 2018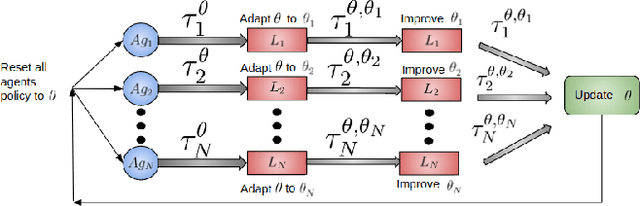


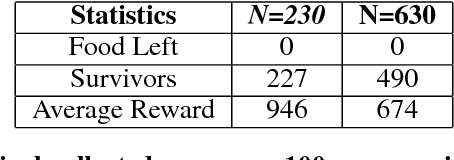
In this paper, we explore using deep reinforcement learning for problems with multiple agents. Most existing methods for deep multi-agent reinforcement learning consider only a small number of agents. When the number of agents increases, the dimensionality of the input and control spaces increase as well, and these methods do not scale well. To address this, we propose casting the multi-agent reinforcement learning problem as a distributed optimization problem. Our algorithm assumes that for multi-agent settings, policies of individual agents in a given population live close to each other in parameter space and can be approximated by a single policy. With this simple assumption, we show our algorithm to be extremely effective for reinforcement learning in multi-agent settings. We demonstrate its effectiveness against existing comparable approaches on co-operative and competitive tasks.
Learning Sample-Efficient Target Reaching for Mobile Robots
Mar 05, 2018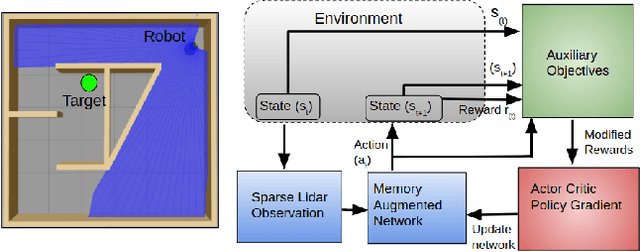

In this paper, we propose a novel architecture and a self-supervised policy gradient algorithm, which employs unsupervised auxiliary tasks to enable a mobile robot to learn how to navigate to a given goal. The dependency on the global information is eliminated by providing only sparse range-finder measurements to the robot. The partially observable planning problem is addressed by splitting it into a hierarchical process. We use convolutional networks to plan locally, and a differentiable memory to provide information about past time steps in the trajectory. These modules, combined in our network architecture, produce globally consistent plans. The sparse reward problem is mitigated by our modified policy gradient algorithm. We model the robots uncertainty with unsupervised tasks to force exploration. The novel architecture we propose with the modified version of the policy gradient algorithm allows our robot to reach the goal in a sample efficient manner, which is orders of magnitude faster than the current state of the art policy gradient algorithm. Simulation and experimental results are provided to validate the proposed approach.
Memory Augmented Control Networks
Feb 14, 2018


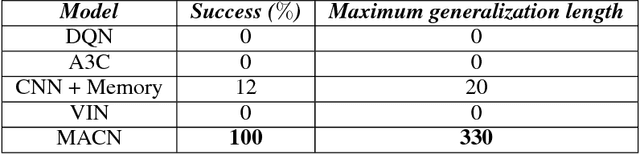
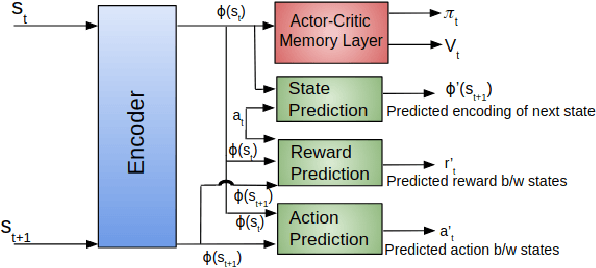
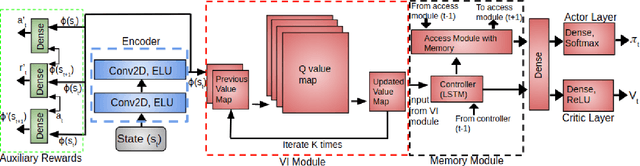
Planning problems in partially observable environments cannot be solved directly with convolutional networks and require some form of memory. But, even memory networks with sophisticated addressing schemes are unable to learn intelligent reasoning satisfactorily due to the complexity of simultaneously learning to access memory and plan. To mitigate these challenges we introduce the Memory Augmented Control Network (MACN). The proposed network architecture consists of three main parts. The first part uses convolutions to extract features and the second part uses a neural network-based planning module to pre-plan in the environment. The third part uses a network controller that learns to store those specific instances of past information that are necessary for planning. The performance of the network is evaluated in discrete grid world environments for path planning in the presence of simple and complex obstacles. We show that our network learns to plan and can generalize to new environments.
End-to-End Navigation in Unknown Environments using Neural Networks
Jul 24, 2017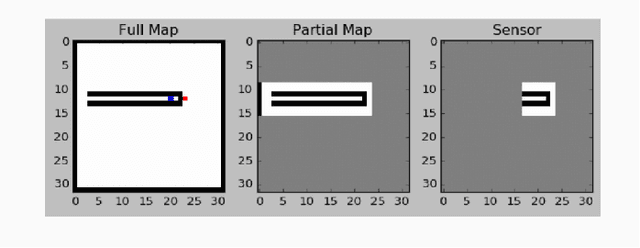
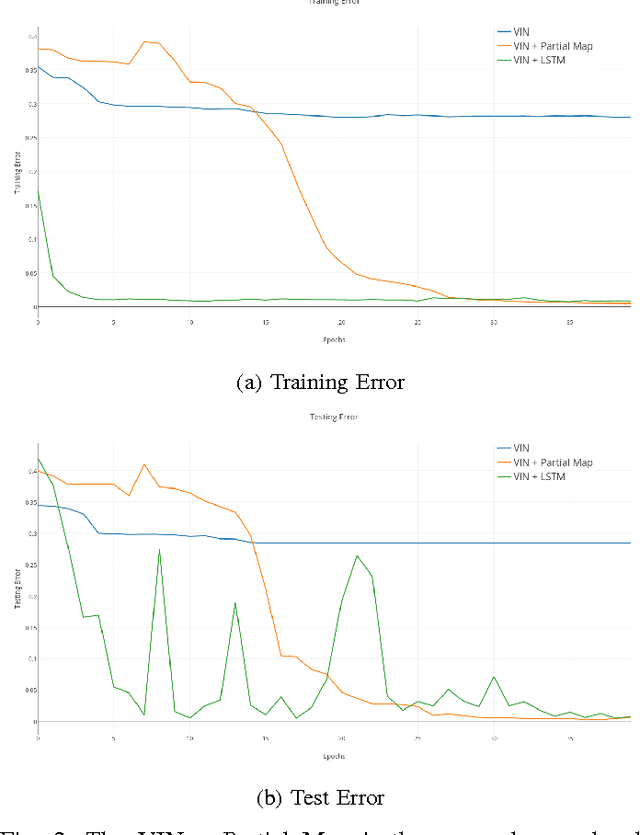
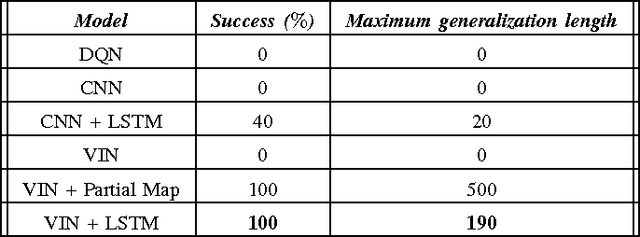
We investigate how a neural network can learn perception actions loops for navigation in unknown environments. Specifically, we consider how to learn to navigate in environments populated with cul-de-sacs that represent convex local minima that the robot could fall into instead of finding a set of feasible actions that take it to the goal. Traditional methods rely on maintaining a global map to solve the problem of over coming a long cul-de-sac. However, due to errors induced from local and global drift, it is highly challenging to maintain such a map for long periods of time. One way to mitigate this problem is by using learning techniques that do not rely on hand engineered map representations and instead output appropriate control policies directly from their sensory input. We first demonstrate that such a problem cannot be solved directly by deep reinforcement learning due to the sparse reward structure of the environment. Further, we demonstrate that deep supervised learning also cannot be used directly to solve this problem. We then investigate network models that offer a combination of reinforcement learning and supervised learning and highlight the significance of adding fully differentiable memory units to such networks. We evaluate our networks on their ability to generalize to new environments and show that adding memory to such networks offers huge jumps in performance