 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Aware, Collision-Free Information Gathering for Heterogeneous Robot Teams
Jul 30, 2022
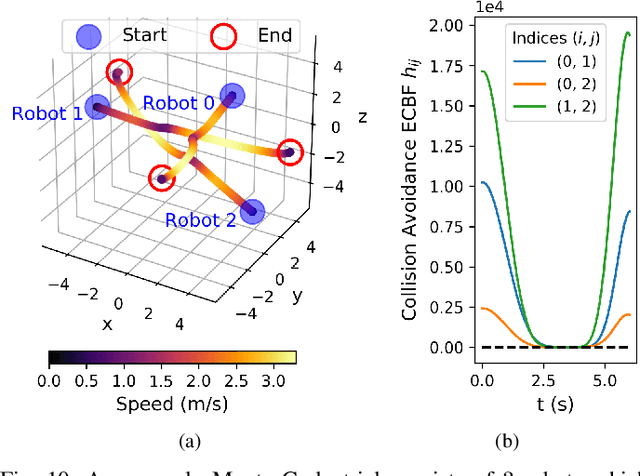
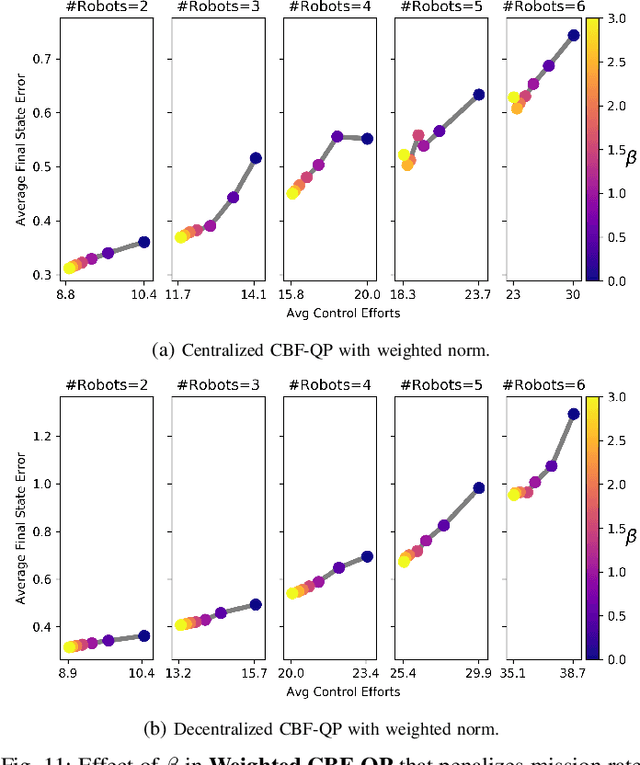
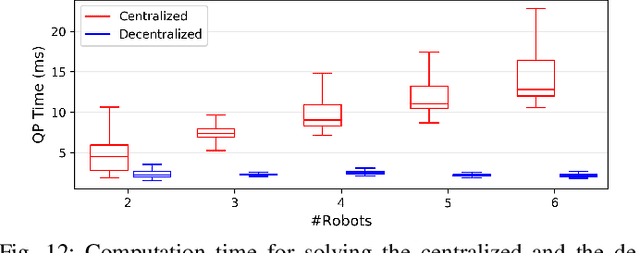
This paper considers the problem of safely coordinating a team of sensor-equipped robots to reduce uncertainty about a dynamical process, where the objective trades off information gain and energy cost. Optimizing this trade-off is desirable, but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planners based on coordinate descent lose their performance guarantees. Furthermore, methods that handle non-monotonicity lose their performance guarantees when subject to inter-robot collision avoidance constraints. As it is desirable to retain both the performance guarantee and safety guarantee, this work proposes a hierarchical approach with a distributed planner that uses local search with a worst-case performance guarantees and a decentralized controller based on control barrier functions that ensures safety and encourages timely arrival at sensing locations. Via extensive simulations, hardware-in-the-loop tests and hardware experiments, we demonstrate that the proposed approach achieves a better trade-off between sensing and energy cost than coordinate descent based algorithms.
Resilient Active Information Acquisition with Teams of Robots
Mar 17, 2021
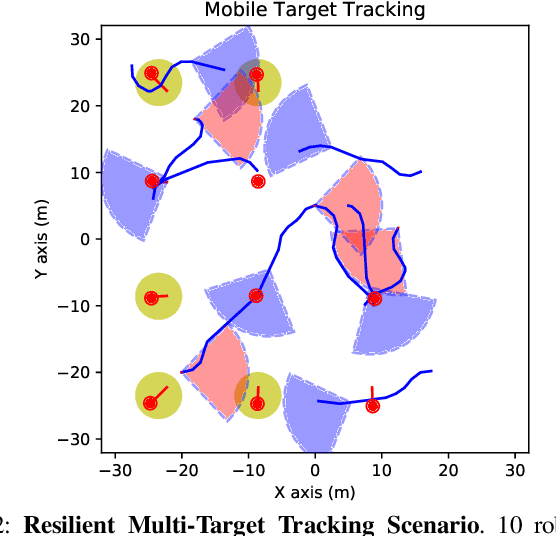
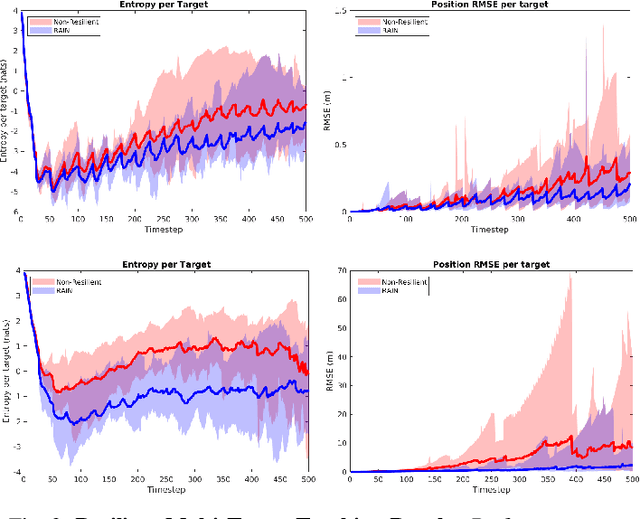
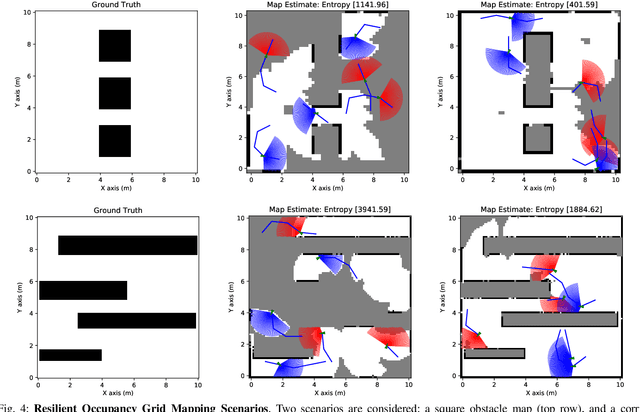
Emerging applications of collaborative autonomy, such as Multi-Target Tracking, Unknown Map Exploration, and Persistent Surveillance, require robots plan paths to navigate an environment while maximizing the information collected via on-board sensors. In this paper, we consider such information acquisition tasks but in adversarial environments, where attacks may temporarily disable the robots' sensors. We propose the first receding horizon algorithm, aiming for robust and adaptive multi-robot planning against any number of attacks, which we call Resilient Active Information acquisitioN (RAIN). RAIN calls, in an online fashion, a Robust Trajectory Planning (RTP) subroutine which plans attack-robust control inputs over a look-ahead planning horizon. We quantify RTP's performance by bounding its suboptimality. We base our theoretical analysis on notions of curvature introduced in combinatorial optimization. We evaluate RAIN in three information acquisition scenarios: Multi-Target Tracking, Occupancy Grid Mapping, and Persistent Surveillance. The scenarios are simulated in C++ and a Unity-based simulator. In all simulations, RAIN runs in real-time, and exhibits superior performance against a state-of-the-art baseline information acquisition algorithm, even in the presence of a high number of attacks. We also demonstrate RAIN's robustness and effectiveness against varying models of attacks (worst-case and random), as well as, varying replanning rates.
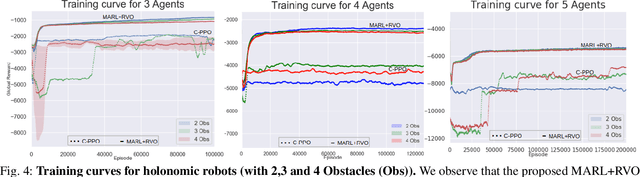
Non-Monotone Energy-Aware Information Gathering for Heterogeneous Robot Teams
Jan 26, 2021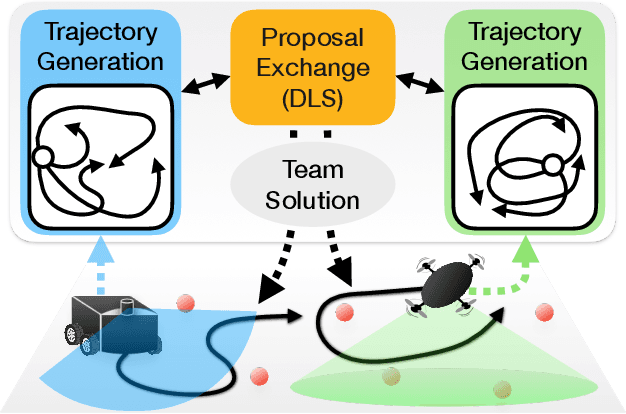
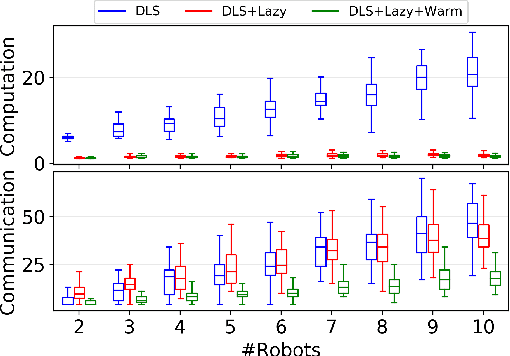
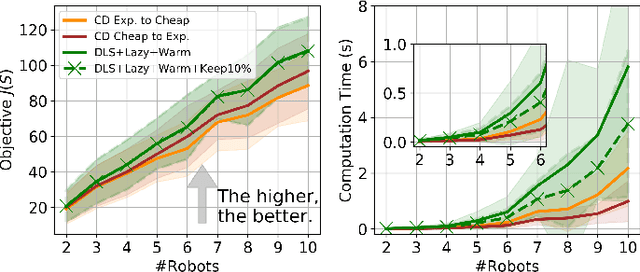
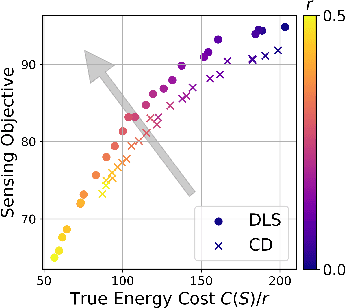
This paper considers the problem of planning trajectories for a team of sensor-equipped robots to reduce uncertainty about a dynamical process. Optimizing the trade-off between information gain and energy cost (e.g., control effort, energy expenditure, distance travelled) is desirable but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planning algorithms based on techniques such as coordinate descent lose their performance guarantees. Methods based on local search provide performance guarantees for optimizing a non-monotone submodular function, but require access to all robots' trajectories, making it not suitable for distributed execution. This work proposes a distributed planning approach based on local search, and shows how to reduce its computation and communication requirements without sacrificing algorithm performance. We demonstrate the efficacy of our proposed method by coordinating robot teams composed of both ground and aerial vehicles with different sensing and control profiles, and evaluate the algorithm's performance in two target tracking scenarios. Our results show up to 60% communication reduction and 80-92% computation reduction on average when coordinating up to 10 robots, while outperforming the coordinate descent based algorithm in achieving a desirable trade-off between sensing and energy expenditure.
Stochastic Motion Planning under Partial Observability for Mobile Robots with Continuous Range Measurements
Dec 02, 2020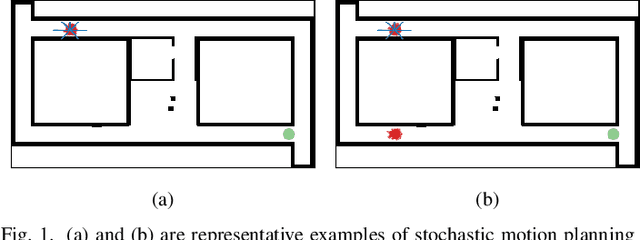
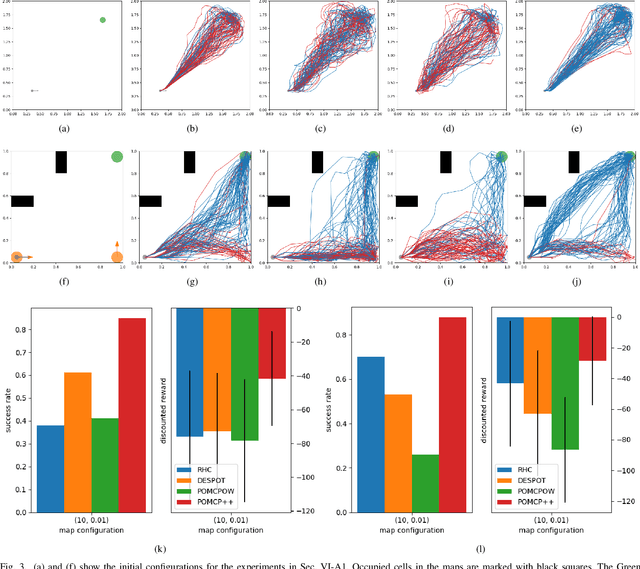
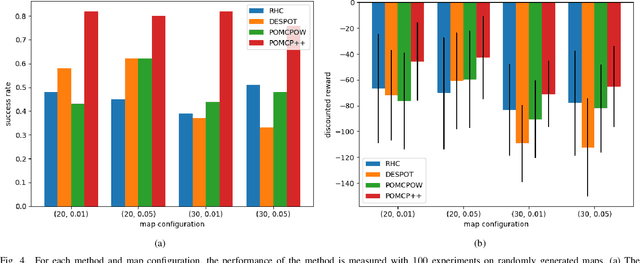
In this paper, we address the problem of stochastic motion planning under partial observability, more specifically, how to navigate a mobile robot equipped with continuous range sensors such as LIDAR. In contrast to many existing robotic motion planning methods, we explicitly consider the uncertainty of the robot state by modeling the system as a POMDP. Recent work on general purpose POMDP solvers is typically limited to discrete observation spaces, and does not readily apply to the proposed problem due to the continuous measurements from LIDAR. In this work, we build upon an existing Monte Carlo Tree Search method, POMCP, and propose a new algorithm POMCP++. Our algorithm can handle continuous observation spaces with a novel measurement selection strategy. The POMCP++ algorithm overcomes over-optimism in the value estimation of a rollout policy by removing the implicit perfect state assumption at the rollout phase. We validate POMCP++ in theory by proving it is a Monte Carlo Tree Search algorithm. Through comparisons with other methods that can also be applied to the proposed problem, we show that POMCP++ yields significantly higher success rate and total reward.
Feedback Enhanced Motion Planning for Autonomous Vehicles
Jul 11, 2020

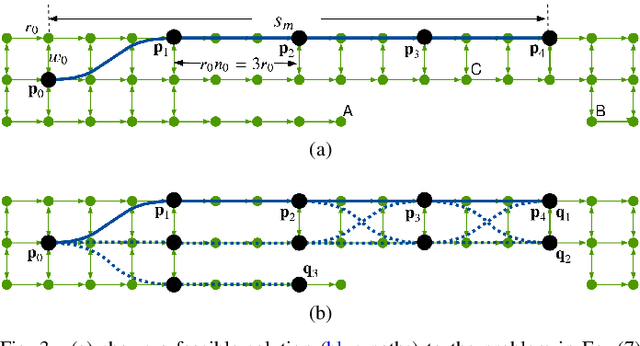
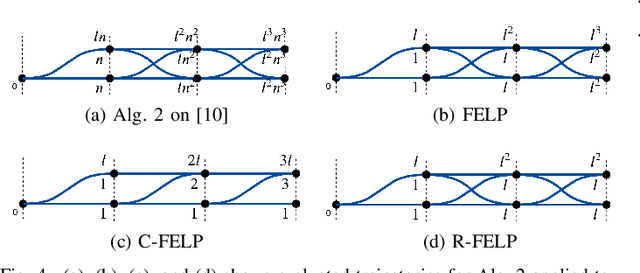
In this work, we address the motion planning problem for autonomous vehicles through a new lattice planning approach, called Feedback Enhanced Lattice Planner (FELP). Existing lattice planners have two major limitations, namely the high dimensionality of the lattice and the lack of modeling of agent vehicle behaviors. We propose to apply the Intelligent Driver Model (IDM) as a speed feedback policy to address both of these limitations. IDM both enables the responsive behavior of the agents, and uniquely determines the acceleration and speed profile of the ego vehicle on a given path. Therefore, only a spatial lattice is needed, while discretization of higher order dimensions is no longer required. Additionally, we propose a directed-graph map representation to support the implementation and execution of lattice planners. The map can reflect local geometric structure, embed the traffic rules adhering to the road, and is efficient to construct and update. We show that FELP is more efficient compared to other existing lattice planners through runtime complexity analysis, and we propose two variants of FELP to further reduce the complexity to polynomial time. We demonstrate the improvement by comparing FELP with an existing spatiotemporal lattice planner using simulations of a merging scenario and continuous highway traffic. We also study the performance of FELP under different traffic densities.
Learning Q-network for Active Information Acquisition
Oct 23, 2019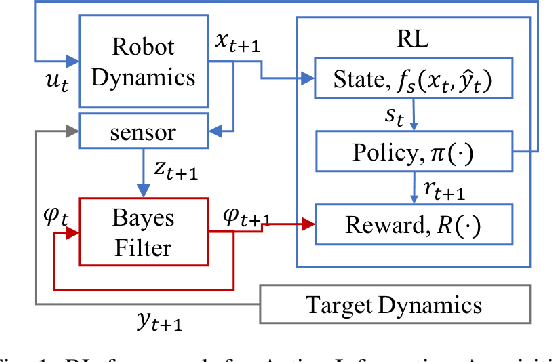
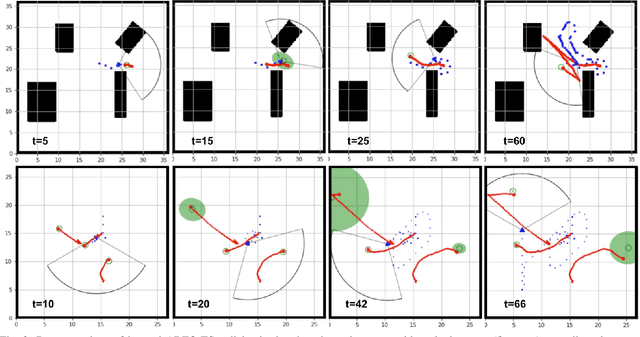
In this paper, we propose a novel Reinforcement Learning approach for solving the Active Information Acquisition problem, which requires an agent to choose a sequence of actions in order to acquire information about a process of interest using on-board sensors. The classic challenges in the information acquisition problem are the dependence of a planning algorithm on known models and the difficulty of computing information-theoretic cost functions over arbitrary distributions. In contrast, the proposed framework of reinforcement learning does not require any knowledge on models and alleviates the problems during an extended training stage. It results in policies that are efficient to execute online and applicable for real-time control of robotic systems. Furthermore, the state-of-the-art planning methods are typically restricted to short horizons, which may become problematic with local minima. Reinforcement learning naturally handles the issue of planning horizon in information problems as it maximizes a discounted sum of rewards over a long finite or infinite time horizon. We discuss the potential benefits of the proposed framework and compare the performance of the novel algorithm to an existing information acquisition method for multi-target tracking scenarios.
* IROS 2019, Video https://youtu.be/0ZFyOWJ2ulo
Optimal Algorithms for Submodular Maximization with Distributed Constraints
Sep 30, 2019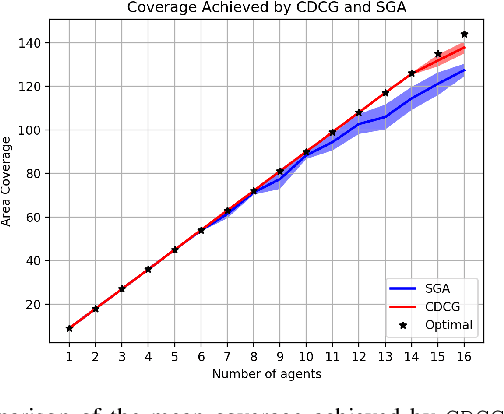
We consider a class of discrete optimization problems that aim to maximize a submodular objective function subject to a distributed partition matroid constraint. More precisely, we consider a networked scenario in which multiple agents choose actions from local strategy sets with the goal of maximizing a submodular objective function defined over the set of all possible actions. Given this distributed setting, we develop Constraint-Distributed Continuous Greedy (CDCG), a message passing algorithm that converges to the tight $(1-1/e)$ approximation factor of the optimum global solution using only local computation and communication. It is known that a sequential greedy algorithm can only achieve a $1/2$ multiplicative approximation of the optimal solution for this class of problems in the distributed setting. Our framework relies on lifting the discrete problem to a continuous domain and developing a consensus algorithm that achieves the tight $(1-1/e)$ approximation guarantee of the global discrete solution once a proper rounding scheme is applied. We also offer empirical results from a multi-agent area coverage problem to show that the proposed method significantly outperforms the state-of-the-art sequential greedy method.
Learning Safe Unlabeled Multi-Robot Planning with Motion Constraints
Jul 11, 2019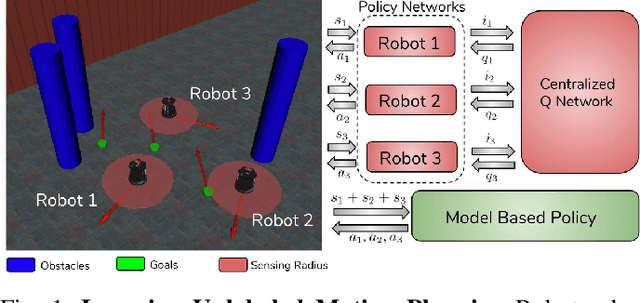
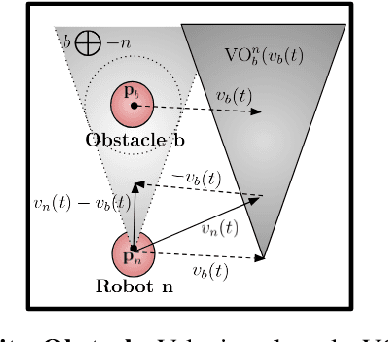
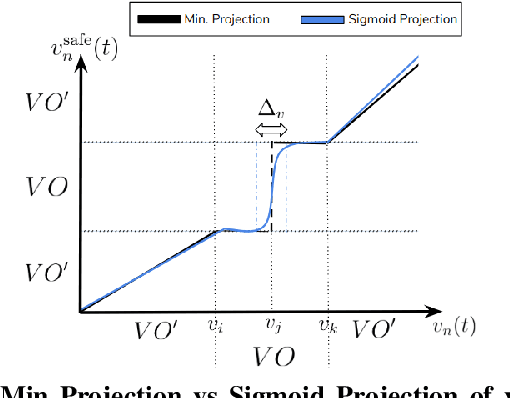
In this paper, we present a learning approach to goal assignment and trajectory planning for unlabeled robots operating in 2D, obstacle-filled workspaces. More specifically, we tackle the unlabeled multi-robot motion planning problem with motion constraints as a multi-agent reinforcement learning problem with some sparse global reward. In contrast with previous works, which formulate an entirely new hand-crafted optimization cost or trajectory generation algorithm for a different robot dynamic model, our framework is a general approach that is applicable to arbitrary robot models. Further, by using the velocity obstacle, we devise a smooth projection that guarantees collision free trajectories for all robots with respect to their neighbors and obstacles. The efficacy of our algorithm is demonstrated through varied simulations.
Resilient Active Information Gathering with Mobile Robots
Sep 02, 2018
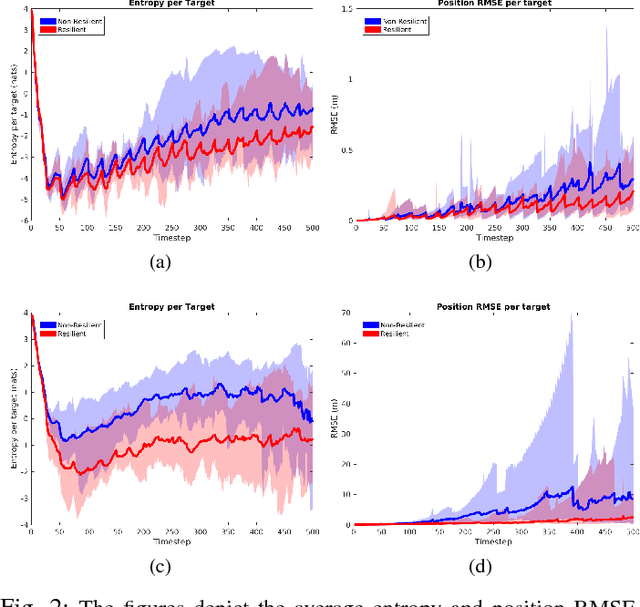

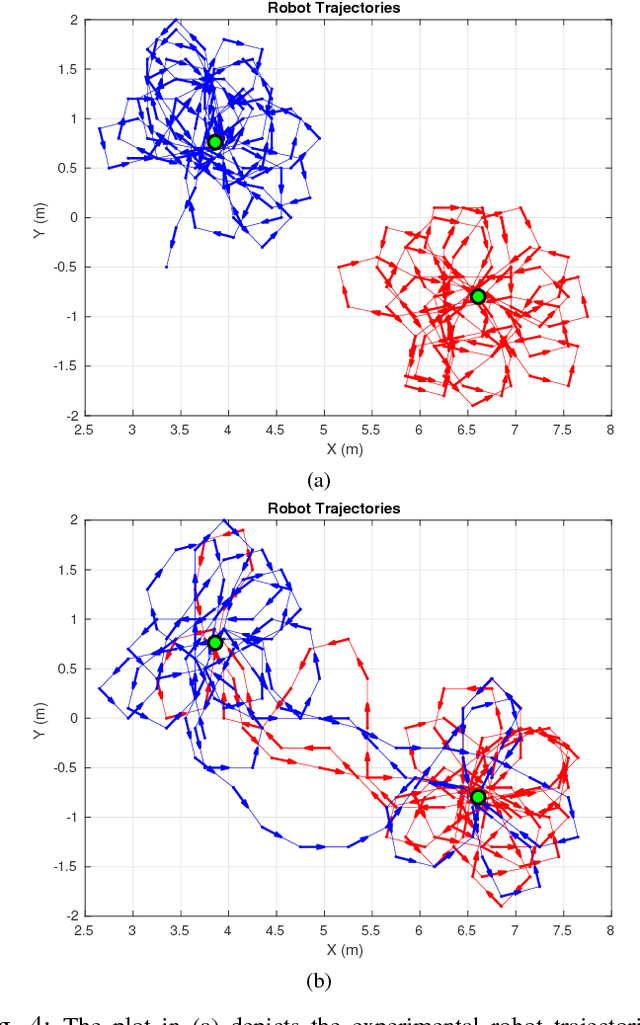
Applications of safety, security, and rescue in robotics, such as multi-robot target tracking, involve the execution of information acquisition tasks by teams of mobile robots. However, in failure-prone or adversarial environments, robots get attacked, their communication channels get jammed, and their sensors may fail, resulting in the withdrawal of robots from the collective task, and consequently the inability of the remaining active robots to coordinate with each other. As a result, traditional design paradigms become insufficient and, in contrast, resilient designs against system-wide failures and attacks become important. In general, resilient design problems are hard, and even though they often involve objective functions that are monotone or submodular, scalable approximation algorithms for their solution have been hitherto unknown. In this paper, we provide the first algorithm, enabling the following capabilities: minimal communication, i.e., the algorithm is executed by the robots based only on minimal communication between them; system-wide resiliency, i.e., the algorithm is valid for any number of denial-of-service attacks and failures; and provable approximation performance, i.e., the algorithm ensures for all monotone (and not necessarily submodular) objective functions a solution that is finitely close to the optimal. We quantify our algorithm's approximation performance using a notion of curvature for monotone set functions. We support our theoretical analyses with simulated and real-world experiments, by considering an active information gathering scenario, namely, multi-robot target tracking.