 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI-Driven High-Fidelity Human Motion Simulation
Jul 18, 2025



Human motion simulation (HMS) supports cost-effective evaluation of worker behavior, safety, and productivity in industrial tasks. However, existing methods often suffer from low motion fidelity. This study introduces Generative-AI-Enabled HMS (G-AI-HMS), which integrates text-to-text and text-to-motion models to enhance simulation quality for physical tasks. G-AI-HMS tackles two key challenges: (1) translating task descriptions into motion-aware language using Large Language Models aligned with MotionGPT's training vocabulary, and (2) validating AI-enhanced motions against real human movements using computer vision. Posture estimation algorithms are applied to real-time videos to extract joint landmarks, and motion similarity metrics are used to compare them with AI-enhanced sequences. In a case study involving eight tasks, the AI-enhanced motions showed lower error than human created descriptions in most scenarios, performing better in six tasks based on spatial accuracy, four tasks based on alignment after pose normalization, and seven tasks based on overall temporal similarity. Statistical analysis showed that AI-enhanced prompts significantly (p $<$ 0.0001) reduced joint error and temporal misalignment while retaining comparable posture accuracy.
Computer-Vision-Enabled Worker Video Analysis for Motion Amount Quantification
May 22, 2024The performance of physical workers is significantly influenced by the quantity of their motions. However, monitoring and assessing these motions is challenging due to the complexities of motion sensing, tracking, and quantification. Recent advancements have utilized in-situ video analysis for real-time observation of worker behaviors, enabling data-driven quantification of motion amounts. Nevertheless, there are limitations to monitoring worker movements using video data. This paper introduces a novel framework based on computer vision to track and quantify the motion of workers' upper and lower limbs, issuing alerts when the motion reaches critical thresholds. Using joint position data from posture estimation, the framework employs Hotelling's T$^2$ statistic to quantify and monitor motion amounts, integrating computer vision tools to address challenges in automated worker training and enhance exploratory research in this field. We collected data of participants performing lifting and moving tasks with large boxes and small wooden cubes, to simulate macro and micro assembly tasks respectively. It was found that the correlation between workers' joint motion amount and the Hotelling's T$^2$ statistic was approximately 35% greater for micro tasks compared to macro tasks, highlighting the framework's ability to identify fine-grained motion differences. This study demonstrates the effectiveness of the proposed system in real-time applications across various industry settings. It provides a tool for enhancing worker safety and productivity through precision motion analysis and proactive ergonomic adjustments.
Effect of Human Involvement on Work Performance and Fluency in Human-Robot Collaboration for Recycling
Jan 20, 2022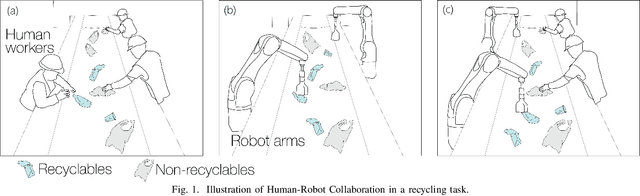


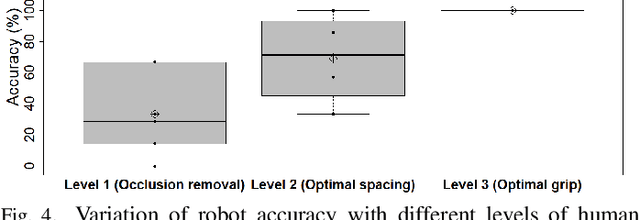
Human-robot collaboration has significant potential in recycling due to the wide variation in the composition of recyclable products. Six participants performed a recyclable item sorting task collaborating with a robot arm equipped with a vision system. The effect of three different levels of human involvement or assistance to the robot (Level 1- occlusion removal; Level 2- optimal spacing; Level 3- optimal grip) on performance metrics such as robot accuracy, task time and subjective fluency were assessed. Results showed that human involvement had a remarkable impact on the robot's accuracy, which increased with human involvement level. Mean accuracy values were 33.3% for Level 1, 69% for Level 2 and 100% for Level 3. The results imply that for sorting processes involving diverse materials that vary in size, shape, and composition, human assistance could improve the robot's accuracy to a significant extent while also being cost-effective.
Scalable Reinforcement Learning Policies for Multi-Agent Control
Nov 16, 2020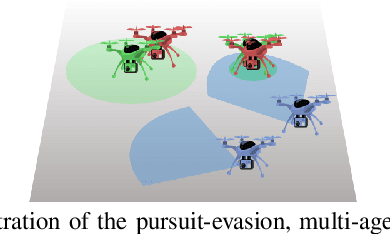
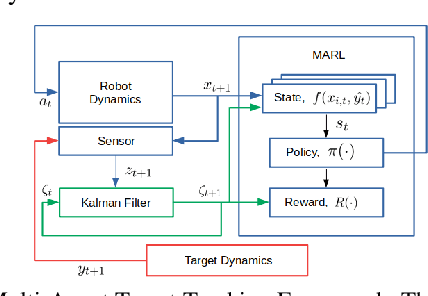
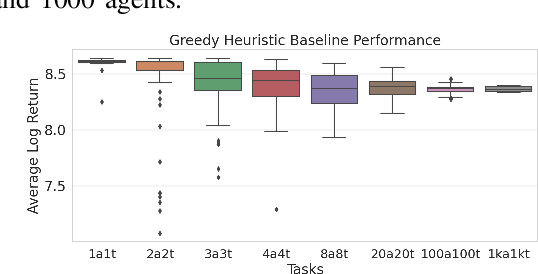
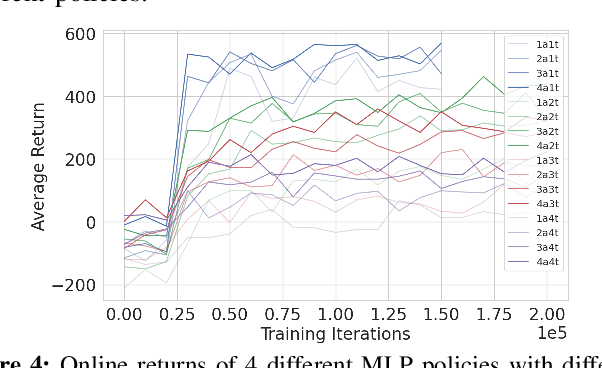
This paper develops a stochastic Multi-Agent Reinforcement Learning (MARL) method to learn control policies that can handle an arbitrary number of external agents; our policies can be executed for tasks consisting of 1000 pursuers and 1000 evaders. We model pursuers as agents with limited on-board sensing and formulate the problem as a decentralized, partially-observable Markov Decision Process. An attention mechanism is used to build a permutation and input-size invariant embedding of the observations for learning a stochastic policy and value function using techniques in entropy-regularized off-policy methods. Simulation experiments on a large number of problems show that our control policies are dramatically scalable and display cooperative behavior in spite of being executed in a decentralized fashion; our methods offer a simple solution to classical multi-agent problems using techniques in reinforcement learning.
Learning to Track Dynamic Targets in Partially Known Environments
Jun 17, 2020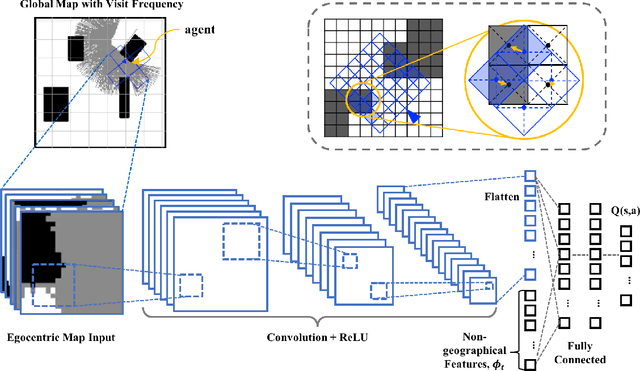

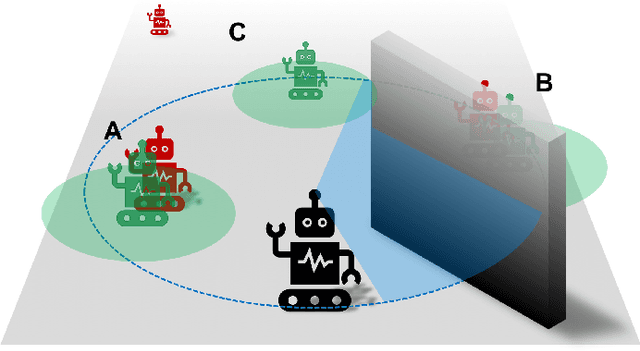
We solve active target tracking, one of the essential tasks in autonomous systems, using a deep reinforcement learning (RL) approach. In this problem, an autonomous agent is tasked with acquiring information about targets of interests using its onboard sensors. The classical challenges in this problem are system model dependence and the difficulty of computing information-theoretic cost functions for a long planning horizon. RL provides solutions for these challenges as the length of its effective planning horizon does not affect the computational complexity, and it drops the strong dependency of an algorithm on system models. In particular, we introduce Active Tracking Target Network (ATTN), a unified RL policy that is capable of solving major sub-tasks of active target tracking -- in-sight tracking, navigation, and exploration. The policy shows robust behavior for tracking agile and anomalous targets with a partially known target model. Additionally, the same policy is able to navigate in obstacle environments to reach distant targets as well as explore the environment when targets are positioned in unexpected locations.
Learning Q-network for Active Information Acquisition
Oct 23, 2019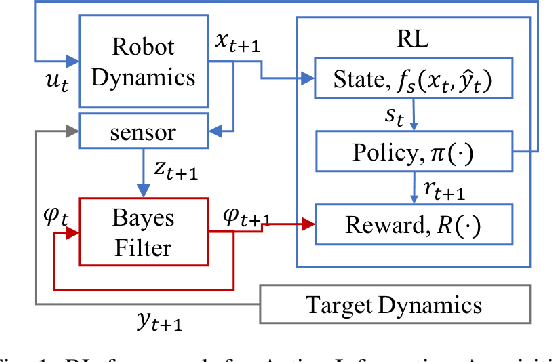
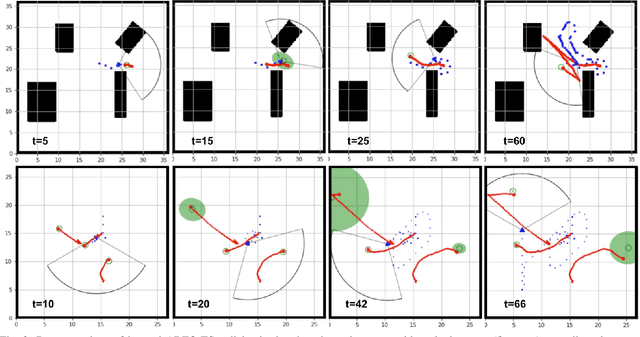
In this paper, we propose a novel Reinforcement Learning approach for solving the Active Information Acquisition problem, which requires an agent to choose a sequence of actions in order to acquire information about a process of interest using on-board sensors. The classic challenges in the information acquisition problem are the dependence of a planning algorithm on known models and the difficulty of computing information-theoretic cost functions over arbitrary distributions. In contrast, the proposed framework of reinforcement learning does not require any knowledge on models and alleviates the problems during an extended training stage. It results in policies that are efficient to execute online and applicable for real-time control of robotic systems. Furthermore, the state-of-the-art planning methods are typically restricted to short horizons, which may become problematic with local minima. Reinforcement learning naturally handles the issue of planning horizon in information problems as it maximizes a discounted sum of rewards over a long finite or infinite time horizon. We discuss the potential benefits of the proposed framework and compare the performance of the novel algorithm to an existing information acquisition method for multi-target tracking scenarios.
* IROS 2019, Video https://youtu.be/0ZFyOWJ2ulo
Assumed Density Filtering Q-learning
Oct 05, 2018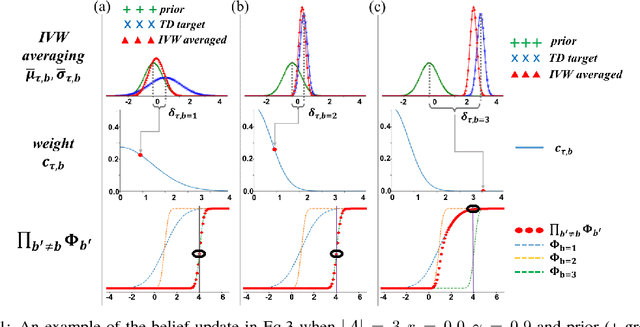

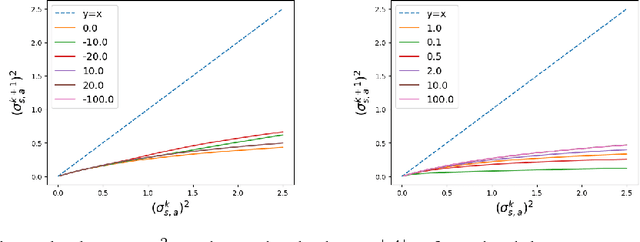
While off-policy temporal difference (TD) methods have widely been used in reinforcement learning due to their efficiency and simple implementation, their Bayesian counterparts have not been utilized as frequently. One reason is that the non-linear max operation in the Bellman optimality equation makes it difficult to define conjugate distributions over the value functions. In this paper, we introduce a novel Bayesian approach to off-policy TD methods, called as ADFQ, which updates beliefs on state-action values, Q, through an online Bayesian inference method known as Assumed Density Filtering. In order to formulate a closed-form update, we approximately estimate analytic parameters of the posterior of the Q-beliefs. Uncertainty measures in the beliefs not only are used in exploration but also provide a natural regularization for learning. We show that ADFQ converges to Q-learning as the uncertainty measures of the Q-beliefs decrease. ADFQ improves common drawbacks of other Bayesian RL algorithms such as computational complexity. We also extend ADFQ with a neural network. Our empirical results demonstrate that the proposed ADFQ algorithm outperforms comparable algorithms on various domains including continuous state domains and games from the Arcade Learning Environment.