 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficiently Accurate Model Learning for Planning
Feb 11, 2021
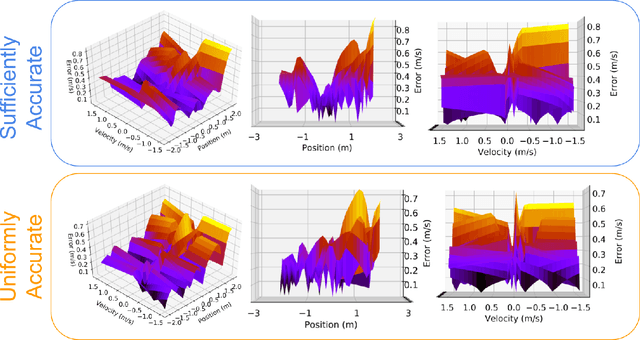
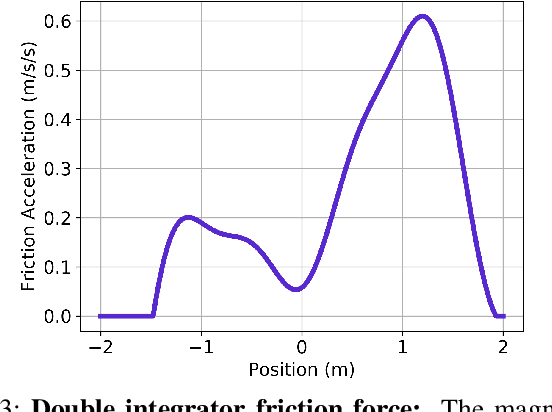
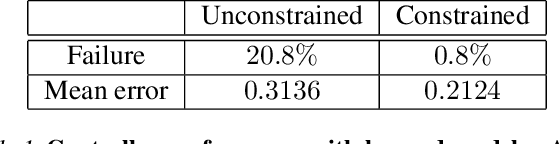
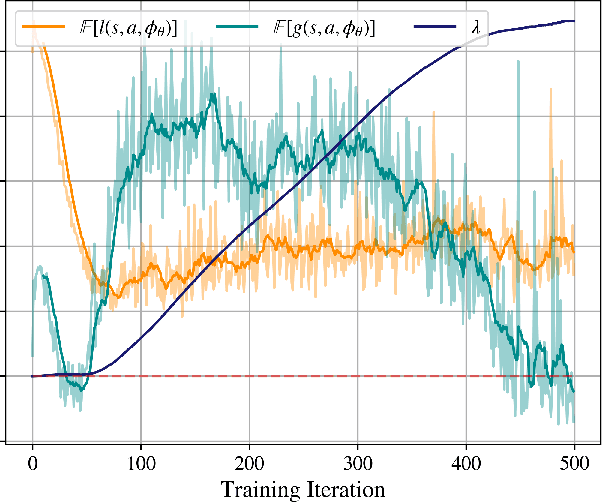
Data driven models of dynamical systems help planners and controllers to provide more precise and accurate motions. Most model learning algorithms will try to minimize a loss function between the observed data and the model's predictions. This can be improved using prior knowledge about the task at hand, which can be encoded in the form of constraints. This turns the unconstrained model learning problem into a constrained one. These constraints allow models with finite capacity to focus their expressive power on important aspects of the system. This can lead to models that are better suited for certain tasks. This paper introduces the constrained Sufficiently Accurate model learning approach, provides examples of such problems, and presents a theorem on how close some approximate solutions can be. The approximate solution quality will depend on the function parameterization, loss and constraint function smoothness, and the number of samples in model learning.
Learning Task Agnostic Sufficiently Accurate Models
Feb 19, 2019
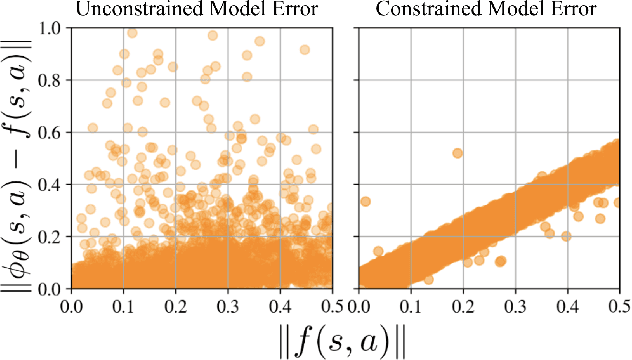
For complex real-world systems, designing controllers are a difficult task. With the advent of neural networks as a proxy for complex function approximators, it has become popular to learn the controller directly. However, these controllers are specific to a given task and need to be relearned for a new task. Alternatively, one can learn just the model of the dynamical system and compose it with external controllers. Such a model is task (and controller) agnostic and must generalize well across the state space. This paper proposes learning a "sufficiently accurate" model of the dynamics that explicitly enforces small residual error on pre-defined parts of the state-space. We formulate task agnostic controller design for this learned model as an optimization problem with state and control constraints that is solved in an online fashion. We validate this approach in simulation using a challenging contact-based Ball-Paddle system.
Assumed Density Filtering Q-learning
Oct 05, 2018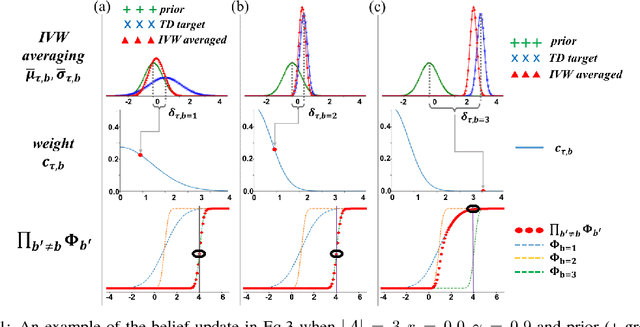

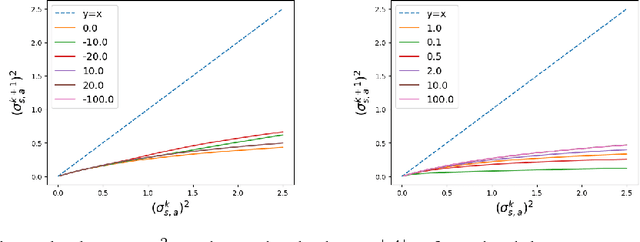
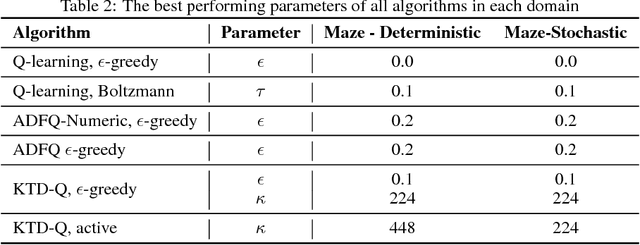
While off-policy temporal difference (TD) methods have widely been used in reinforcement learning due to their efficiency and simple implementation, their Bayesian counterparts have not been utilized as frequently. One reason is that the non-linear max operation in the Bellman optimality equation makes it difficult to define conjugate distributions over the value functions. In this paper, we introduce a novel Bayesian approach to off-policy TD methods, called as ADFQ, which updates beliefs on state-action values, Q, through an online Bayesian inference method known as Assumed Density Filtering. In order to formulate a closed-form update, we approximately estimate analytic parameters of the posterior of the Q-beliefs. Uncertainty measures in the beliefs not only are used in exploration but also provide a natural regularization for learning. We show that ADFQ converges to Q-learning as the uncertainty measures of the Q-beliefs decrease. ADFQ improves common drawbacks of other Bayesian RL algorithms such as computational complexity. We also extend ADFQ with a neural network. Our empirical results demonstrate that the proposed ADFQ algorithm outperforms comparable algorithms on various domains including continuous state domains and games from the Arcade Learning Environment.
Learning Optimal Resource Allocations in Wireless Systems
Jul 21, 2018
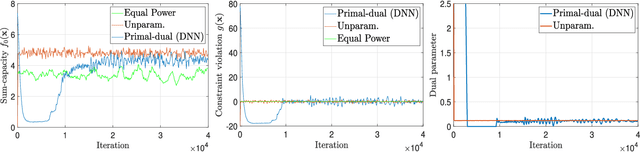
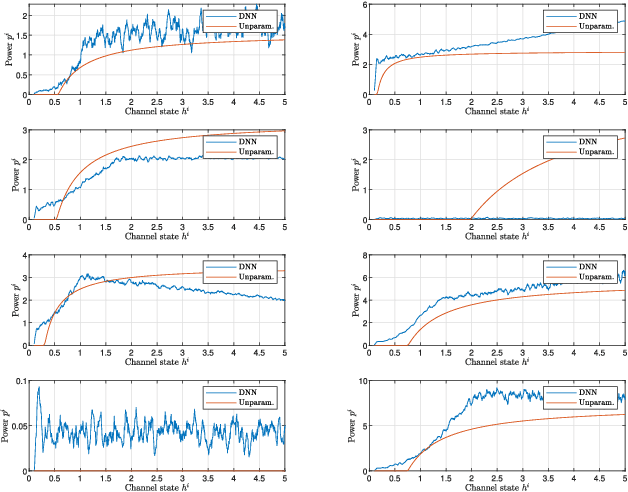
This paper considers the design of optimal resource allocation policies in wireless communication systems which are generically modeled as a functional optimization problems with stochastic constraints. These optimization problems have the structure of a learning problem in which the statistical loss appears as a constraint motivating the development of learning methodologies to attempt their solution. To handle stochastic constraints, training is undertaken in the dual domain. It is shown that this can be done with small loss of optimality when using near-universal learning parameterizations. In particular, since deep neural networks (DNN) are near-universal their use is advocated and explored. DNNs are trained here with a model-free primal-dual method that simultaneously learns a DNN parametrization of the resource allocation policy and optimizes the primal and dual variables. Numerical simulations demonstrate the strong performance of the proposed approach on a number of common wireless resource allocation problems.
Learning Implicit Sampling Distributions for Motion Planning
Jun 06, 2018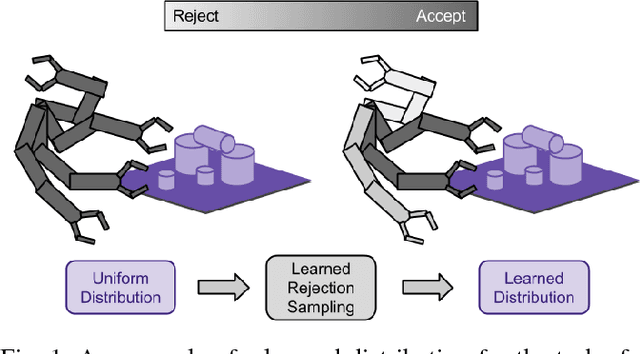

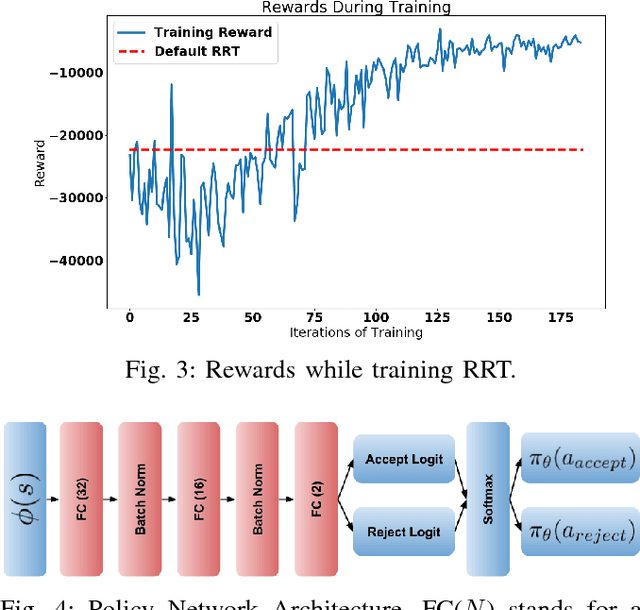
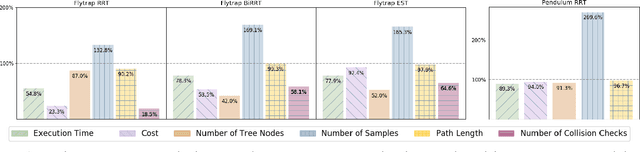
Sampling-based motion planners have experienced much success due to their ability to efficiently and evenly explore the state space. However, for many tasks, it may be more efficient to not uniformly explore the state space, especially when there is prior information about its structure. Previous methods have attempted to modify the sampling distribution using hand selected heuristics that can work well for specific environments but not universally. In this paper, a policy- search based method is presented as an adaptive way to learn implicit sampling distributions for different environments. It utilizes information from past searches in similar environments to generate better distributions in novel environments, thus reducing overall computational cost. Our method can be incor- porated with a variety of sampling-based planners to improve performance. Our approach is validated on a number of tasks, including a 7DOF robot arm, showing marked improvement in number of collision checks as well as number of nodes expanded compared with baseline methods.
Scalable Centralized Deep Multi-Agent Reinforcement Learning via Policy Gradients
May 22, 2018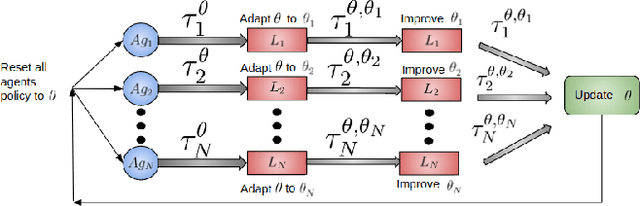


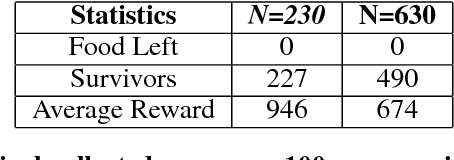
In this paper, we explore using deep reinforcement learning for problems with multiple agents. Most existing methods for deep multi-agent reinforcement learning consider only a small number of agents. When the number of agents increases, the dimensionality of the input and control spaces increase as well, and these methods do not scale well. To address this, we propose casting the multi-agent reinforcement learning problem as a distributed optimization problem. Our algorithm assumes that for multi-agent settings, policies of individual agents in a given population live close to each other in parameter space and can be approximated by a single policy. With this simple assumption, we show our algorithm to be extremely effective for reinforcement learning in multi-agent settings. We demonstrate its effectiveness against existing comparable approaches on co-operative and competitive tasks.
Memory Augmented Control Networks
Feb 14, 2018


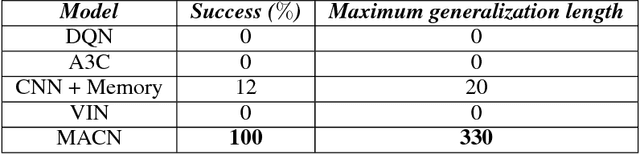
Planning problems in partially observable environments cannot be solved directly with convolutional networks and require some form of memory. But, even memory networks with sophisticated addressing schemes are unable to learn intelligent reasoning satisfactorily due to the complexity of simultaneously learning to access memory and plan. To mitigate these challenges we introduce the Memory Augmented Control Network (MACN). The proposed network architecture consists of three main parts. The first part uses convolutions to extract features and the second part uses a neural network-based planning module to pre-plan in the environment. The third part uses a network controller that learns to store those specific instances of past information that are necessary for planning. The performance of the network is evaluated in discrete grid world environments for path planning in the presence of simple and complex obstacles. We show that our network learns to plan and can generalize to new environments.
End-to-End Navigation in Unknown Environments using Neural Networks
Jul 24, 2017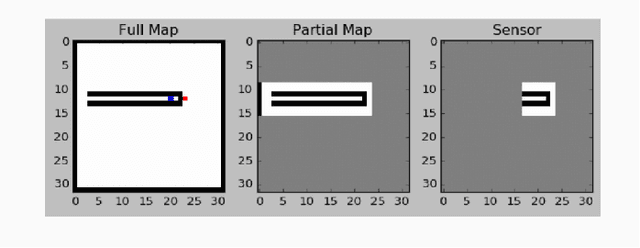
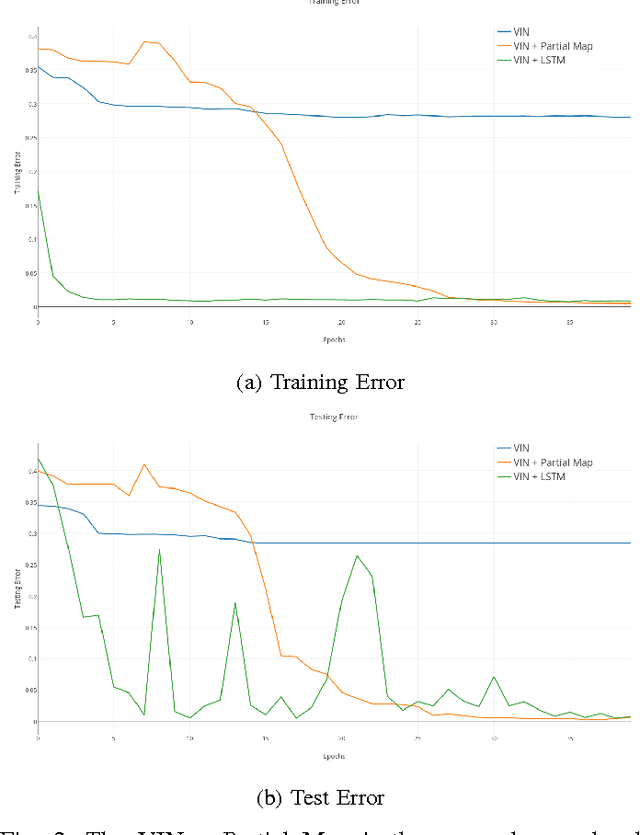
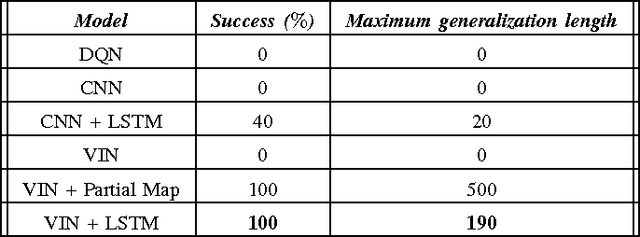
We investigate how a neural network can learn perception actions loops for navigation in unknown environments. Specifically, we consider how to learn to navigate in environments populated with cul-de-sacs that represent convex local minima that the robot could fall into instead of finding a set of feasible actions that take it to the goal. Traditional methods rely on maintaining a global map to solve the problem of over coming a long cul-de-sac. However, due to errors induced from local and global drift, it is highly challenging to maintain such a map for long periods of time. One way to mitigate this problem is by using learning techniques that do not rely on hand engineered map representations and instead output appropriate control policies directly from their sensory input. We first demonstrate that such a problem cannot be solved directly by deep reinforcement learning due to the sparse reward structure of the environment. Further, we demonstrate that deep supervised learning also cannot be used directly to solve this problem. We then investigate network models that offer a combination of reinforcement learning and supervised learning and highlight the significance of adding fully differentiable memory units to such networks. We evaluate our networks on their ability to generalize to new environments and show that adding memory to such networks offers huge jumps in performance