 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Submodular Maximization under Communication Delays: A Simultaneous Decision-Making Approach
Mar 29, 2026We provide a distributed online algorithm for multi-agent submodular maximization under communication delays. We are motivated by the future distributed information-gathering tasks in unknown and dynamic environments, where utility functions naturally exhibit the diminishing-returns property, i.e., submodularity. Existing approaches for online submodular maximization either rely on sequential multi-hop communication, resulting in prohibitive delays and restrictive connectivity assumptions, or restrict each agent's coordination to its one-hop neighborhood only, thereby limiting the coordination performance. To address the issue, we provide the Distributed Online Greedy (DOG) algorithm, which integrates tools from adversarial bandit learning with delayed feedback to enable simultaneous decision-making across arbitrary network topologies. We provide the approximation performance of DOG against an optimal solution, capturing the suboptimality cost due to decentralization as a function of the network structure. Our analyses further reveal a trade-off between coordination performance and convergence time, determined by the magnitude of communication delays. By this trade-off, DOG spans the spectrum between the state-of-the-art fully centralized online coordination approach [1] and fully decentralized one-hop coordination approach [2].
Self-Configurable Mesh-Networks for Scalable Distributed Submodular Bandit Optimization
Feb 22, 2026We study how to scale distributed bandit submodular coordination under realistic communication constraints in bandwidth, data rate, and connectivity. We are motivated by multi-agent tasks of active situational awareness in unknown, partially-observable, and resource-limited environments, where the agents must coordinate through agent-to-agent communication. Our approach enables scalability by (i) limiting information relays to only one-hop communication and (ii) keeping inter-agent messages small, having each agent transmit only its own action information. Despite these information-access restrictions, our approach enables near-optimal action coordination by optimizing the agents' communication neighborhoods over time, through distributed online bandit optimization, subject to the agents' bandwidth constraints. Particularly, our approach enjoys an anytime suboptimality bound that is also strictly positive for arbitrary network topologies, even disconnected. To prove the bound, we define the Value of Coordination (VoC), an information-theoretic metric that quantifies for each agent the benefit of information access to its neighbors. We validate in simulations the scalability and near-optimality of our approach: it is observed to converge faster, outperform benchmarks for bandit submodular coordination, and can even outperform benchmarks that are privileged with a priori knowledge of the environment.
MorphEUS: Morphable Omnidirectional Unmanned System
May 23, 2025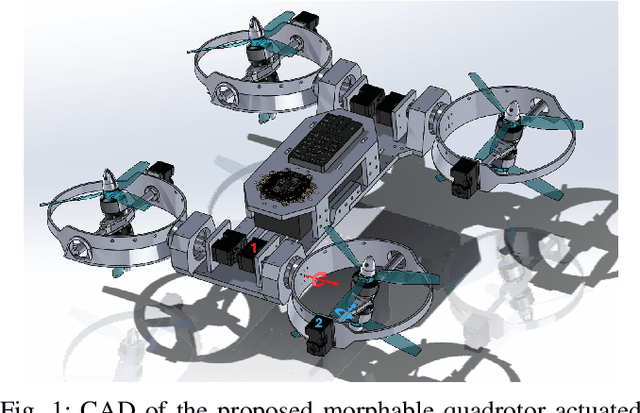
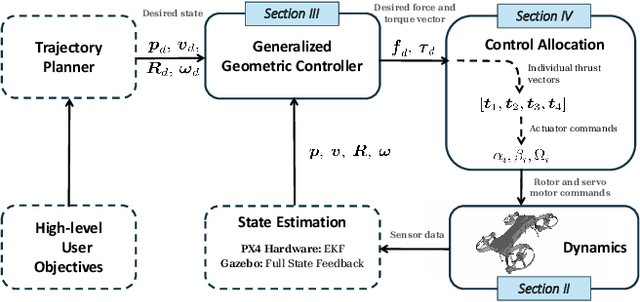
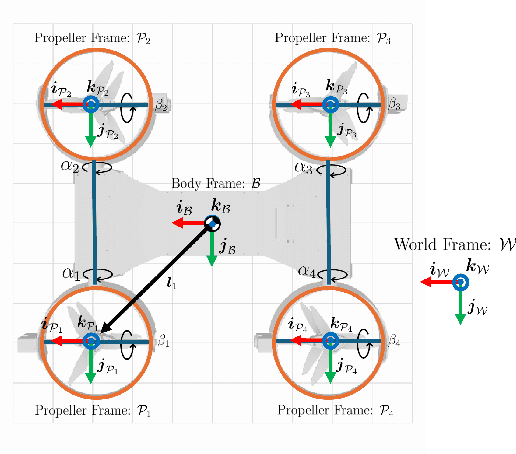
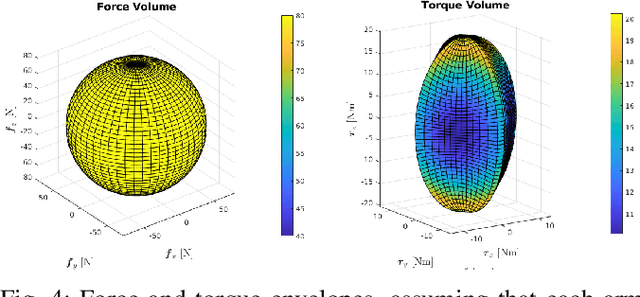
Omnidirectional aerial vehicles (OMAVs) have opened up a wide range of possibilities for inspection, navigation, and manipulation applications using drones. In this paper, we introduce MorphEUS, a morphable co-axial quadrotor that can control position and orientation independently with high efficiency. It uses a paired servo motor mechanism for each rotor arm, capable of pointing the vectored-thrust in any arbitrary direction. As compared to the \textit{state-of-the-art} OMAVs, we achieve higher and more uniform force/torque reachability with a smaller footprint and minimum thrust cancellations. The overactuated nature of the system also results in resiliency to rotor or servo-motor failures. The capabilities of this quadrotor are particularly well-suited for contact-based infrastructure inspection and close-proximity imaging of complex geometries. In the accompanying control pipeline, we present theoretical results for full controllability, almost-everywhere exponential stability, and thrust-energy optimality. We evaluate our design and controller on high-fidelity simulations showcasing the trajectory-tracking capabilities of the vehicle during various tasks. Supplementary details and experimental videos are available on the project webpage.
End-to-End Learning Framework for Solving Non-Markovian Optimal Control
Feb 07, 2025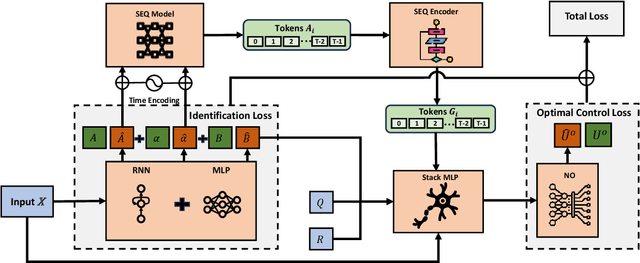
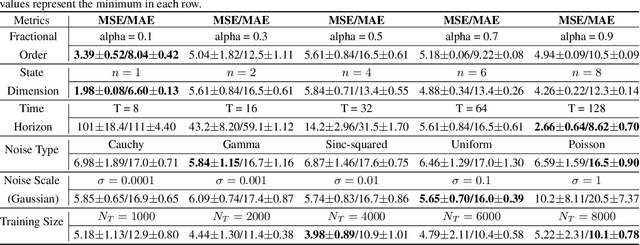
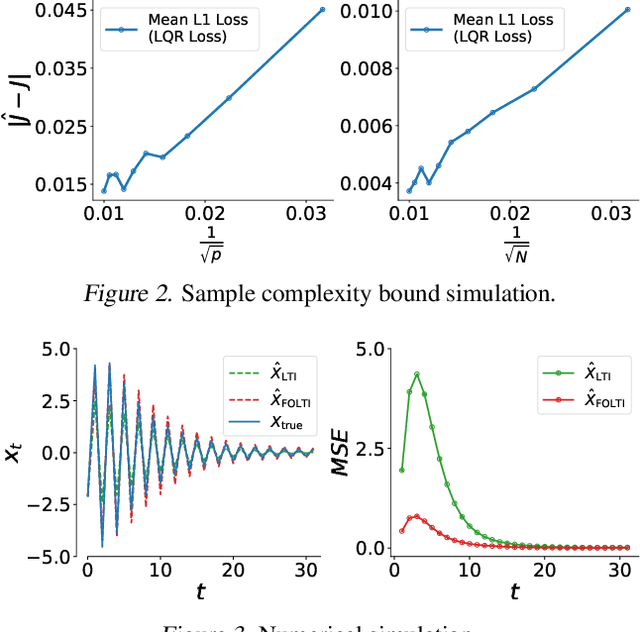

Integer-order calculus often falls short in capturing the long-range dependencies and memory effects found in many real-world processes. Fractional calculus addresses these gaps via fractional-order integrals and derivatives, but fractional-order dynamical systems pose substantial challenges in system identification and optimal control due to the lack of standard control methodologies. In this paper, we theoretically derive the optimal control via \textit{linear quadratic regulator} (LQR) for \textit{fractional-order linear time-invariant }(FOLTI) systems and develop an end-to-end deep learning framework based on this theoretical foundation. Our approach establishes a rigorous mathematical model, derives analytical solutions, and incorporates deep learning to achieve data-driven optimal control of FOLTI systems. Our key contributions include: (i) proposing an innovative system identification method control strategy for FOLTI systems, (ii) developing the first end-to-end data-driven learning framework, \textbf{F}ractional-\textbf{O}rder \textbf{L}earning for \textbf{O}ptimal \textbf{C}ontrol (FOLOC), that learns control policies from observed trajectories, and (iii) deriving a theoretical analysis of sample complexity to quantify the number of samples required for accurate optimal control in complex real-world problems. Experimental results indicate that our method accurately approximates fractional-order system behaviors without relying on Gaussian noise assumptions, pointing to promising avenues for advanced optimal control.
Performance-Aware Self-Configurable Multi-Agent Networks: A Distributed Submodular Approach for Simultaneous Coordination and Network Design
Sep 02, 2024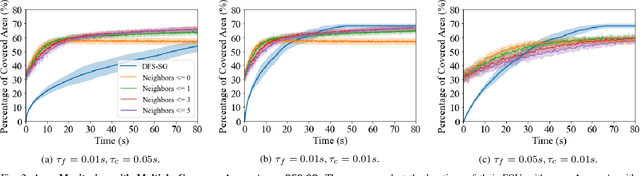
We introduce the first, to our knowledge, rigorous approach that enables multi-agent networks to self-configure their communication topology to balance the trade-off between scalability and optimality during multi-agent planning. We are motivated by the future of ubiquitous collaborative autonomy where numerous distributed agents will be coordinating via agent-to-agent communication to execute complex tasks such as traffic monitoring, event detection, and environmental exploration. But the explosion of information in such large-scale networks currently curtails their deployment due to impractical decision times induced by the computational and communication requirements of the existing near-optimal coordination algorithms. To overcome this challenge, we present the AlterNAting COordination and Network-Design Algorithm (Anaconda), a scalable algorithm that also enjoys near-optimality guarantees. Subject to the agents' bandwidth constraints, Anaconda enables the agents to optimize their local communication neighborhoods such that the action-coordination approximation performance of the network is maximized. Compared to the state of the art, Anaconda is an anytime self-configurable algorithm that quantifies its suboptimality guarantee for any type of network, from fully disconnected to fully centralized, and that, for sparse networks, is one order faster in terms of decision speed. To develop the algorithm, we quantify the suboptimality cost due to decentralization, i.e., due to communication-minimal distributed coordination. We also employ tools inspired by the literature on multi-armed bandits and submodular maximization subject to cardinality constraints. We demonstrate Anaconda in simulated scenarios of area monitoring and compare it with a state-of-the-art algorithm.
Communication- and Computation-Efficient Distributed Decision-Making in Multi-Robot Networks
Jul 15, 2024
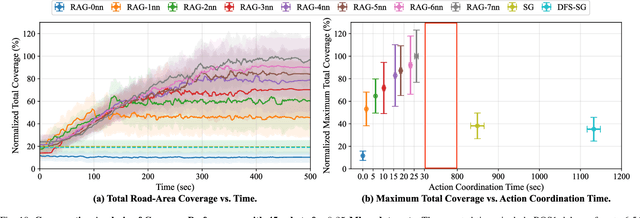
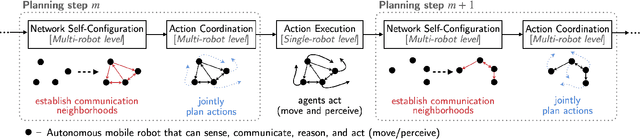
We provide a distributed coordination paradigm that enables scalable and near-optimal joint motion planning among multiple robots. Our coordination paradigm contrasts with current paradigms that are either near-optimal but impractical for replanning times or real-time but offer no near-optimality guarantees. We are motivated by the future of collaborative mobile autonomy, where distributed teams of robots will coordinate via vehicle-to-vehicle (v2v) communication to execute information-heavy tasks like mapping, surveillance, and target tracking. To enable rapid distributed coordination, we must curtail the explosion of information-sharing across the network, thus limiting robot coordination. However, this can lead to suboptimal plans, causing overlapping trajectories instead of complementary ones. We make theoretical and algorithmic contributions to balance the trade-off between decision speed and optimality. We introduce tools for distributed submodular optimization, a diminishing returns property in information-gathering tasks. Theoretically, we analyze how local network topology affects near-optimality at the global level. Algorithmically, we provide a communication- and computation-efficient coordination algorithm for agents to balance the trade-off. Our algorithm is up to two orders faster than competitive near-optimal algorithms. In simulations of surveillance tasks with up to 45 robots, it enables real-time planning at the order of 1 Hz with superior coverage performance. To enable the simulations, we provide a high-fidelity simulator that extends AirSim by integrating a collaborative autonomy pipeline and simulating v2v communication delays.
Simultaneous System Identification and Model Predictive Control with No Dynamic Regret
Jul 04, 2024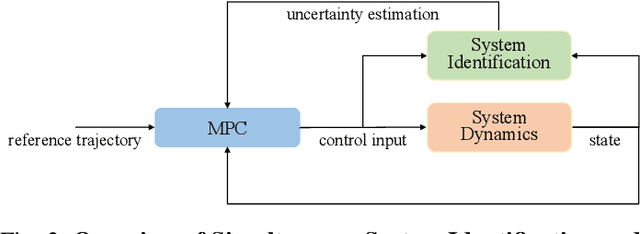
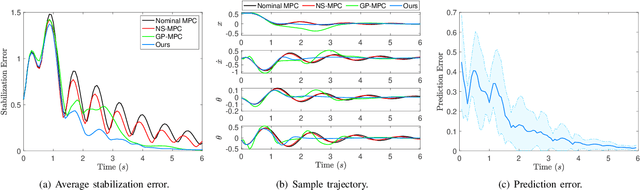
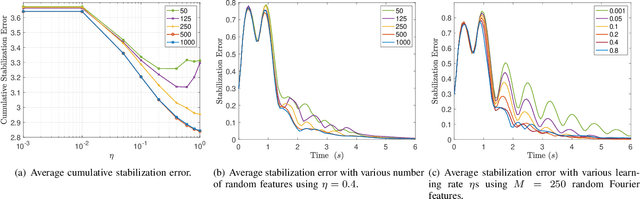
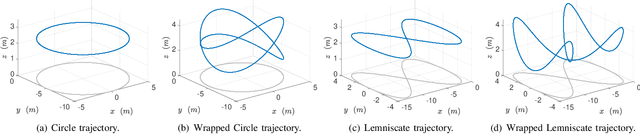
We provide an algorithm for the simultaneous system identification and model predictive control of nonlinear systems. The algorithm has finite-time near-optimality guarantees and asymptotically converges to the optimal (non-causal) controller. Particularly, the algorithm enjoys sublinear dynamic regret, defined herein as the suboptimality against an optimal clairvoyant controller that knows how the unknown disturbances and system dynamics will adapt to its actions. The algorithm is self-supervised and applies to control-affine systems with unknown dynamics and disturbances that can be expressed in reproducing kernel Hilbert spaces. Such spaces can model external disturbances and modeling errors that can even be adaptive to the system's state and control input. For example, they can model wind and wave disturbances to aerial and marine vehicles, or inaccurate model parameters such as inertia of mechanical systems. The algorithm first generates random Fourier features that are used to approximate the unknown dynamics or disturbances. Then, it employs model predictive control based on the current learned model of the unknown dynamics (or disturbances). The model of the unknown dynamics is updated online using least squares based on the data collected while controlling the system. We validate our algorithm in both hardware experiments and physics-based simulations. The simulations include (i) a cart-pole aiming to maintain the pole upright despite inaccurate model parameters, and (ii) a quadrotor aiming to track reference trajectories despite unmodeled aerodynamic drag effects. The hardware experiments include a quadrotor aiming to track a circular trajectory despite unmodeled aerodynamic drag effects, ground effects, and wind disturbances.
Leveraging Untrustworthy Commands for Multi-Robot Coordination in Unpredictable Environments: A Bandit Submodular Maximization Approach
Sep 28, 2023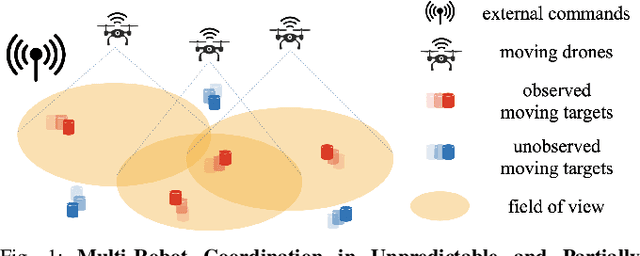
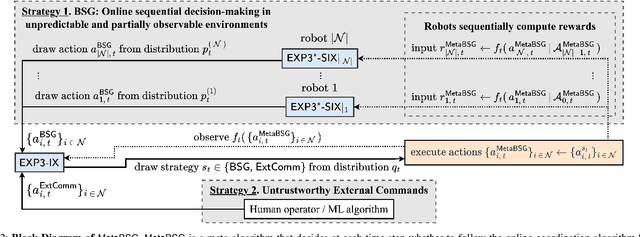
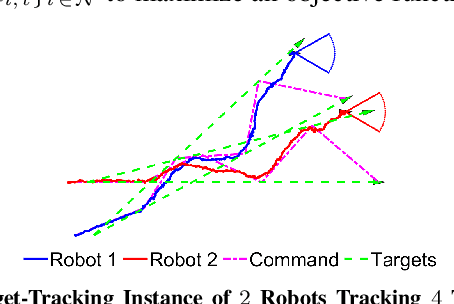
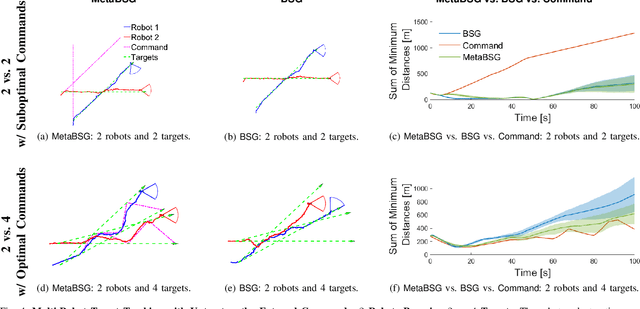
We study the problem of multi-agent coordination in unpredictable and partially-observable environments with untrustworthy external commands. The commands are actions suggested to the robots, and are untrustworthy in that their performance guarantees, if any, are unknown. Such commands may be generated by human operators or machine learning algorithms and, although untrustworthy, can often increase the robots' performance in complex multi-robot tasks. We are motivated by complex multi-robot tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization problems due to the information overlap among the robots. We provide an algorithm, Meta Bandit Sequential Greedy (MetaBSG), which enjoys performance guarantees even when the external commands are arbitrarily bad. MetaBSG leverages a meta-algorithm to learn whether the robots should follow the commands or a recently developed submodular coordination algorithm, Bandit Sequential Greedy (BSG) [1], which has performance guarantees even in unpredictable and partially-observable environments. Particularly, MetaBSG asymptotically can achieve the better performance out of the commands and the BSG algorithm, quantifying its suboptimality against the optimal time-varying multi-robot actions in hindsight. Thus, MetaBSG can be interpreted as robustifying the untrustworthy commands. We validate our algorithm in simulated scenarios of multi-target tracking.
Safe Non-Stochastic Control of Control-Affine Systems: An Online Convex Optimization Approach
Sep 28, 2023



We study how to safely control nonlinear control-affine systems that are corrupted with bounded non-stochastic noise, i.e., noise that is unknown a priori and that is not necessarily governed by a stochastic model. We focus on safety constraints that take the form of time-varying convex constraints such as collision-avoidance and control-effort constraints. We provide an algorithm with bounded dynamic regret, i.e., bounded suboptimality against an optimal clairvoyant controller that knows the realization of the noise a prior. We are motivated by the future of autonomy where robots will autonomously perform complex tasks despite real-world unpredictable disturbances such as wind gusts. To develop the algorithm, we capture our problem as a sequential game between a controller and an adversary, where the controller plays first, choosing the control input, whereas the adversary plays second, choosing the noise's realization. The controller aims to minimize its cumulative tracking error despite being unable to know the noise's realization a prior. We validate our algorithm in simulated scenarios of (i) an inverted pendulum aiming to stay upright, and (ii) a quadrotor aiming to fly to a goal location through an unknown cluttered environment.
Bandit Submodular Maximization for Multi-Robot Coordination in Unpredictable and Partially Observable Environments
May 26, 2023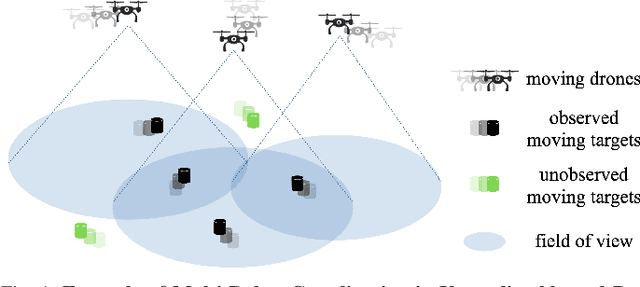
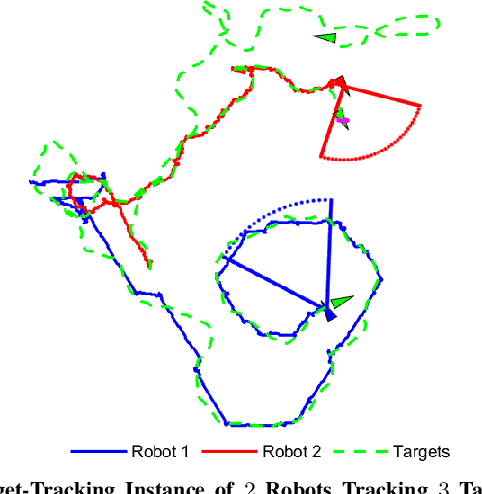
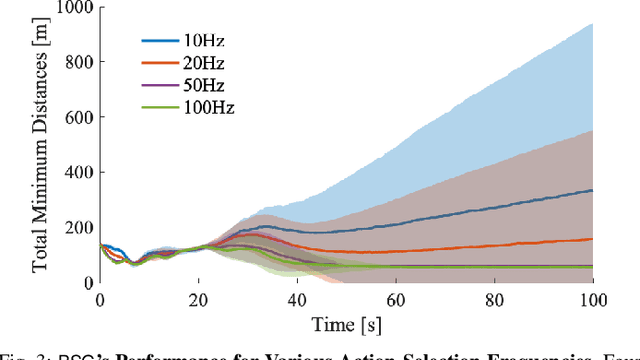
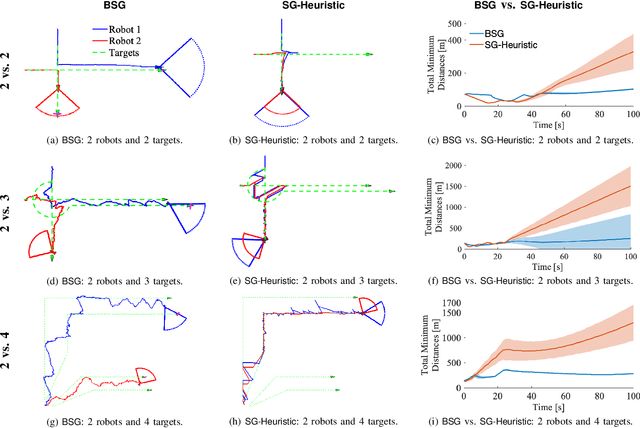
We study the problem of multi-agent coordination in unpredictable and partially observable environments, that is, environments whose future evolution is unknown a priori and that can only be partially observed. We are motivated by the future of autonomy that involves multiple robots coordinating actions in dynamic, unstructured, and partially observable environments to complete complex tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems due to the information overlap among the robots. We introduce the first submodular coordination algorithm with bandit feedback and bounded tracking regret -- bandit feedback is the robots' ability to compute in hindsight only the effect of their chosen actions, instead of all the alternative actions that they could have chosen instead, due to the partial observability; and tracking regret is the algorithm's suboptimality with respect to the optimal time-varying actions that fully know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially, quantifying how often the robots should re-select actions to learn to coordinate as if they fully knew the future a priori. The algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to the bandit setting, by leveraging submodularity and algorithms for the problem of tracking the best action. We validate our algorithm in simulated scenarios of multi-target tracking.