 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Narration-based Reward Shaping Approach using Grounded Natural Language Commands
Oct 31, 2019
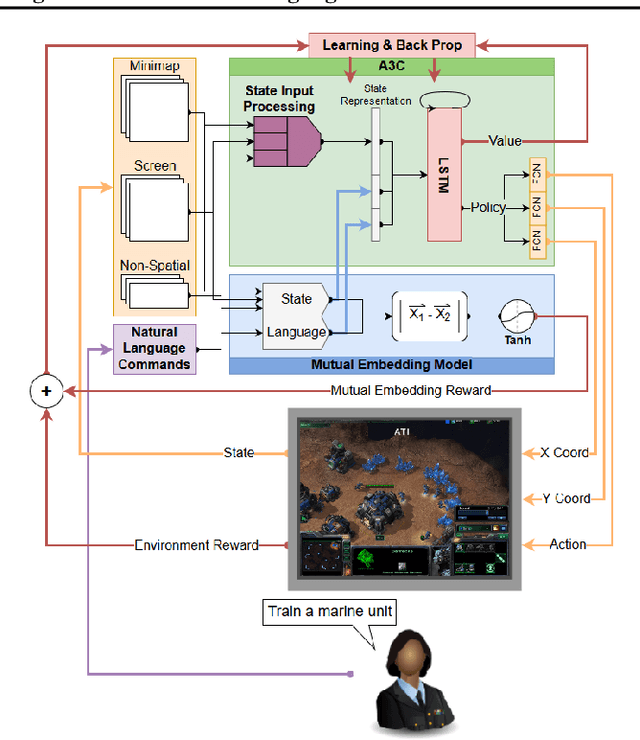
While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of reward sparsity. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we develop a technique that can provide the benefits of reward shaping using natural language commands. Our narration-guided RL agent projects sequences of natural-language commands into the same high-dimensional representation space as corresponding goal states. We show that we can get improved performance with our method compared to traditional reward-shaping approaches. Additionally, we demonstrate the ability of our method to generalize to unseen natural-language commands.
Grounding Natural Language Commands to StarCraft II Game States for Narration-Guided Reinforcement Learning
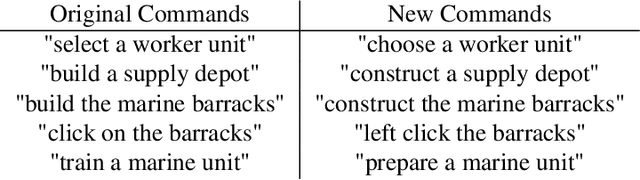
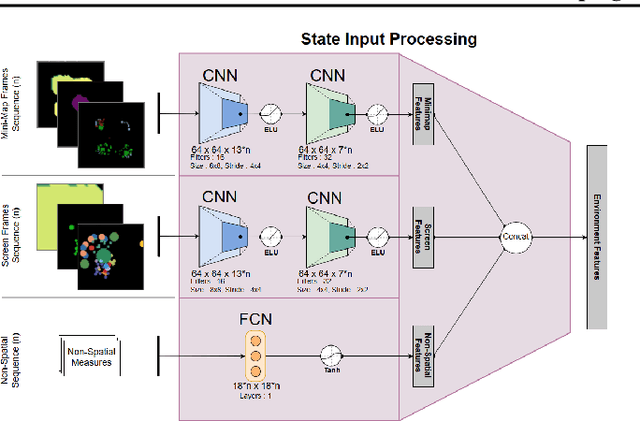
Apr 24, 2019While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of {\em reward sparsity}. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we investigate to what extent we can contextualize these narrations by grounding them to the goal-specific states. We present a mutual-embedding model using a multi-input deep-neural network that projects a sequence of natural language commands into the same high-dimensional representation space as corresponding goal states. We show that using this model we can learn an embedding space with separable and distinct clusters that accurately maps natural-language commands to corresponding game states . We also discuss how this model can allow for the use of narrations as a robust form of reward shaping to improve RL performance and efficiency.
Coordination-driven learning in multi-agent problem spaces
Sep 13, 2018We discuss the role of coordination as a direct learning objective in multi-agent reinforcement learning (MARL) domains. To this end, we present a novel means of quantifying coordination in multi-agent systems, and discuss the implications of using such a measure to optimize coordinated agent policies. This concept has important implications for adversary-aware RL, which we take to be a sub-domain of multi-agent learning.