 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-RAG: A Multimodal Retrieval-Augmented Generation System for Adaptive Video Understanding
May 29, 2025To effectively engage in human society, the ability to adapt, filter information, and make informed decisions in ever-changing situations is critical. As robots and intelligent agents become more integrated into human life, there is a growing opportunity-and need-to offload the cognitive burden on humans to these systems, particularly in dynamic, information-rich scenarios. To fill this critical need, we present Multi-RAG, a multimodal retrieval-augmented generation system designed to provide adaptive assistance to humans in information-intensive circumstances. Our system aims to improve situational understanding and reduce cognitive load by integrating and reasoning over multi-source information streams, including video, audio, and text. As an enabling step toward long-term human-robot partnerships, Multi-RAG explores how multimodal information understanding can serve as a foundation for adaptive robotic assistance in dynamic, human-centered situations. To evaluate its capability in a realistic human-assistance proxy task, we benchmarked Multi-RAG on the MMBench-Video dataset, a challenging multimodal video understanding benchmark. Our system achieves superior performance compared to existing open-source video large language models (Video-LLMs) and large vision-language models (LVLMs), while utilizing fewer resources and less input data. The results demonstrate Multi- RAG's potential as a practical and efficient foundation for future human-robot adaptive assistance systems in dynamic, real-world contexts.
Performance Optimization of Ratings-Based Reinforcement Learning
Jan 13, 2025



This paper explores multiple optimization methods to improve the performance of rating-based reinforcement learning (RbRL). RbRL, a method based on the idea of human ratings, has been developed to infer reward functions in reward-free environments for the subsequent policy learning via standard reinforcement learning, which requires the availability of reward functions. Specifically, RbRL minimizes the cross entropy loss that quantifies the differences between human ratings and estimated ratings derived from the inferred reward. Hence, a low loss means a high degree of consistency between human ratings and estimated ratings. Despite its simple form, RbRL has various hyperparameters and can be sensitive to various factors. Therefore, it is critical to provide comprehensive experiments to understand the impact of various hyperparameters on the performance of RbRL. This paper is a work in progress, providing users some general guidelines on how to select hyperparameters in RbRL.
RbRL2.0: Integrated Reward and Policy Learning for Rating-based Reinforcement Learning
Jan 13, 2025Reinforcement learning (RL), a common tool in decision making, learns policies from various experiences based on the associated cumulative return/rewards without treating them differently. On the contrary, humans often learn to distinguish from different levels of performance and extract the underlying trends towards improving their decision making for best performance. Motivated by this, this paper proposes a novel RL method that mimics humans' decision making process by differentiating among collected experiences for effective policy learning. The main idea is to extract important directional information from experiences with different performance levels, named ratings, so that policies can be updated towards desired deviation from these experiences with different ratings. Specifically, we propose a new policy loss function that penalizes distribution similarities between the current policy and failed experiences with different ratings, and assign different weights to the penalty terms based on the rating classes. Meanwhile, reward learning from these rated samples can be integrated with the new policy loss towards an integrated reward and policy learning from rated samples. Optimizing the integrated reward and policy loss function will lead to the discovery of directions for policy improvement towards maximizing cumulative rewards and penalizing most from the lowest performance level while least from the highest performance level. To evaluate the effectiveness of the proposed method, we present results for experiments on a few typical environments that show improved convergence and overall performance over the existing rating-based reinforcement learning method with only reward learning.
Atari-GPT: Investigating the Capabilities of Multimodal Large Language Models as Low-Level Policies for Atari Games
Aug 28, 2024Recent advancements in large language models (LLMs) have expanded their capabilities beyond traditional text-based tasks to multimodal domains, integrating visual, auditory, and textual data. While multimodal LLMs have been extensively explored for high-level planning in domains like robotics and games, their potential as low-level controllers remains largely untapped. This paper explores the application of multimodal LLMs as low-level controllers in the domain of Atari video games, introducing Atari game performance as a new benchmark for evaluating the ability of multimodal LLMs to perform low-level control tasks. Unlike traditional reinforcement learning (RL) and imitation learning (IL) methods that require extensive computational resources as well as reward function specification, these LLMs utilize pre-existing multimodal knowledge to directly engage with game environments. Our study assesses multiple multimodal LLMs performance against traditional RL agents, human players, and random agents, focusing on their ability to understand and interact with complex visual scenes and formulate strategic responses. Additionally, we examine the impact of In-Context Learning (ICL) by incorporating human-demonstrated game-play trajectories to enhance the models contextual understanding. Through this investigation, we aim to determine the extent to which multimodal LLMs can leverage their extensive training to effectively function as low-level controllers, thereby redefining potential applications in dynamic and visually complex environments. Additional results and videos are available at our project webpage: https://sites.google.com/view/atari-gpt/.
StarCraftImage: A Dataset For Prototyping Spatial Reasoning Methods For Multi-Agent Environments
Jan 09, 2024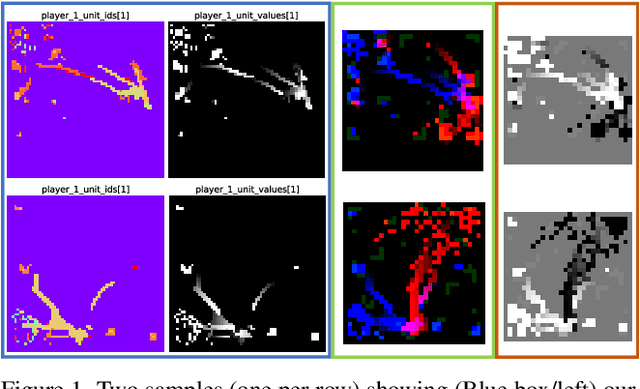
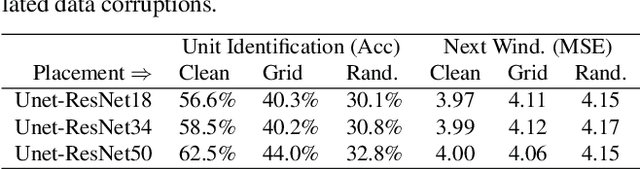
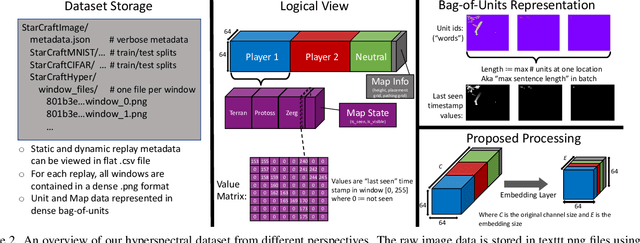
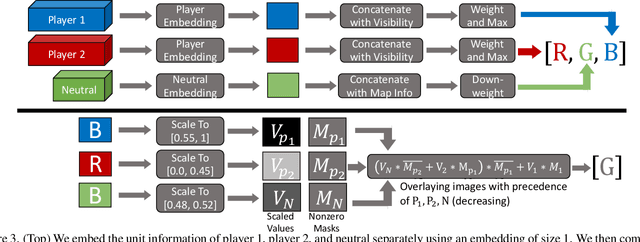
Spatial reasoning tasks in multi-agent environments such as event prediction, agent type identification, or missing data imputation are important for multiple applications (e.g., autonomous surveillance over sensor networks and subtasks for reinforcement learning (RL)). StarCraft II game replays encode intelligent (and adversarial) multi-agent behavior and could provide a testbed for these tasks; however, extracting simple and standardized representations for prototyping these tasks is laborious and hinders reproducibility. In contrast, MNIST and CIFAR10, despite their extreme simplicity, have enabled rapid prototyping and reproducibility of ML methods. Following the simplicity of these datasets, we construct a benchmark spatial reasoning dataset based on StarCraft II replays that exhibit complex multi-agent behaviors, while still being as easy to use as MNIST and CIFAR10. Specifically, we carefully summarize a window of 255 consecutive game states to create 3.6 million summary images from 60,000 replays, including all relevant metadata such as game outcome and player races. We develop three formats of decreasing complexity: Hyperspectral images that include one channel for every unit type (similar to multispectral geospatial images), RGB images that mimic CIFAR10, and grayscale images that mimic MNIST. We show how this dataset can be used for prototyping spatial reasoning methods. All datasets, code for extraction, and code for dataset loading can be found at https://starcraftdata.davidinouye.com
* Published in CVPR 23'
DisasterResponseGPT: Large Language Models for Accelerated Plan of Action Development in Disaster Response Scenarios
Jun 29, 2023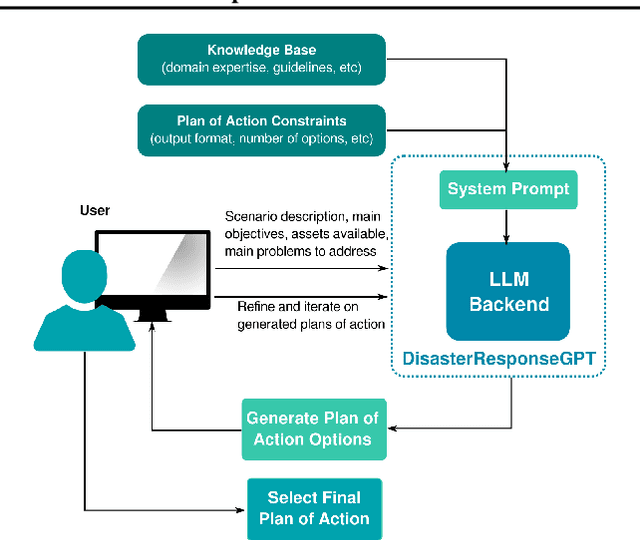
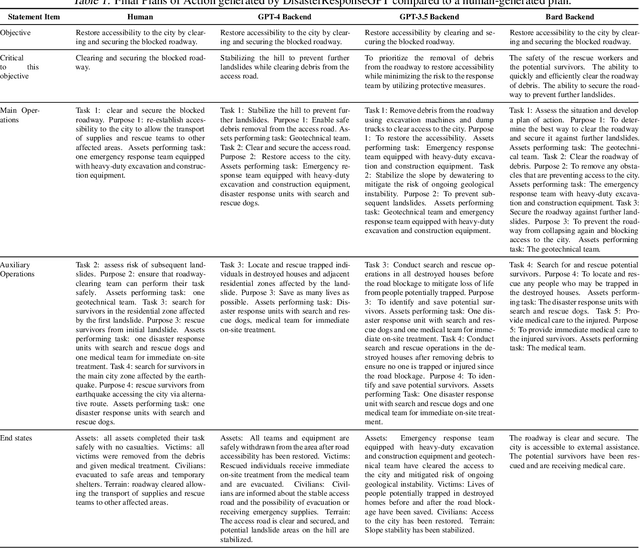


The development of plans of action in disaster response scenarios is a time-consuming process. Large Language Models (LLMs) offer a powerful solution to expedite this process through in-context learning. This study presents DisasterResponseGPT, an algorithm that leverages LLMs to generate valid plans of action quickly by incorporating disaster response and planning guidelines in the initial prompt. In DisasterResponseGPT, users input the scenario description and receive a plan of action as output. The proposed method generates multiple plans within seconds, which can be further refined following the user's feedback. Preliminary results indicate that the plans of action developed by DisasterResponseGPT are comparable to human-generated ones while offering greater ease of modification in real-time. This approach has the potential to revolutionize disaster response operations by enabling rapid updates and adjustments during the plan's execution.
Learning Flight Control Systems from Human Demonstrations and Real-Time Uncertainty-Informed Interventions
May 01, 2023



This paper describes a methodology for learning flight control systems from human demonstrations and interventions while considering the estimated uncertainty in the learned models. The proposed approach uses human demonstrations to train an initial model via imitation learning and then iteratively, improve its performance by using real-time human interventions. The aim of the interventions is to correct undesired behaviors and adapt the model to changes in the task dynamics. The learned model uncertainty is estimated in real-time via Monte Carlo Dropout and the human supervisor is cued for intervention via an audiovisual signal when this uncertainty exceeds a predefined threshold. This proposed approach is validated in an autonomous quadrotor landing task on both fixed and moving platforms. It is shown that with this algorithm, a human can rapidly teach a flight task to an unmanned aerial vehicle via demonstrating expert trajectories and then adapt the learned model by intervening when the learned controller performs any undesired maneuver, the task changes, and/or the model uncertainty exceeds a threshold
Gaze-Informed Multi-Objective Imitation Learning from Human Demonstrations
Feb 25, 2021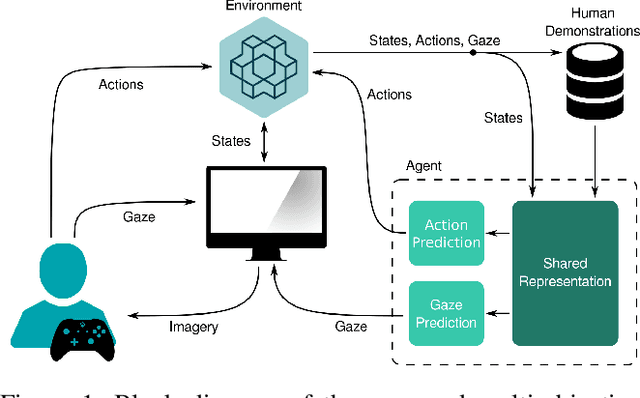
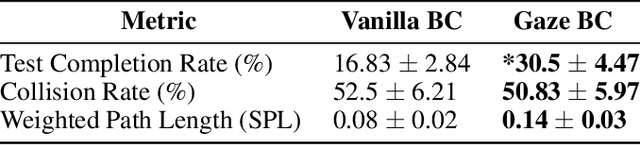
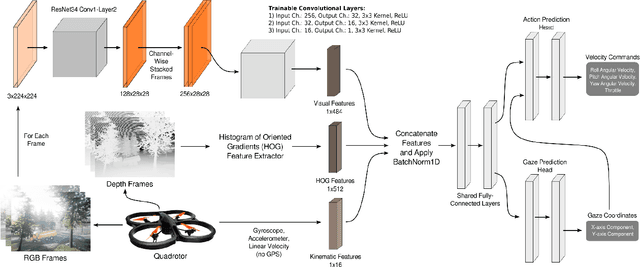

In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation. However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. Previous approaches have only studied the utilization of attention in simple, synchronous environments, limiting their applicability to real-world domains. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context. The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a real-world, photorealistic simulated environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient paths, while simultaneously learning to predict human visual attention. This research aims to highlight the importance of multimodal learning of visual attention information from additional human input modalities and encourages the community to adopt them when training agents from human demonstrations to perform visuomotor tasks.
PODNet: A Neural Network for Discovery of Plannable Options
Nov 15, 2019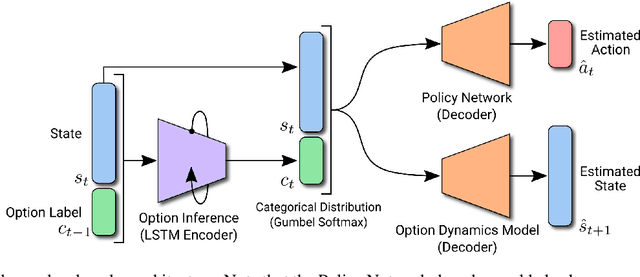
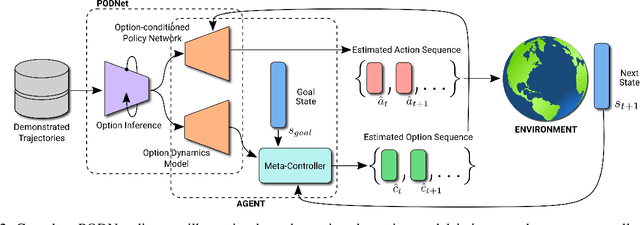
Learning from demonstration has been widely studied in machine learning but becomes challenging when the demonstrated trajectories are unstructured and follow different objectives. This short-paper proposes PODNet, Plannable Option Discovery Network, addressing how to segment an unstructured set of demonstrated trajectories for option discovery. This enables learning from demonstration to perform multiple tasks and plan high-level trajectories based on the discovered option labels. PODNet combines a custom categorical variational autoencoder, a recurrent option inference network, option-conditioned policy network, and option dynamics model in an end-to-end learning architecture. Due to the concurrently trained option-conditioned policy network and option dynamics model, the proposed architecture has implications in multi-task and hierarchical learning, explainable and interpretable artificial intelligence, and applications where the agent is required to learn only from observations.
Integrating Behavior Cloning and Reinforcement Learning for Improved Performance in Sparse Reward Environments
Oct 09, 2019

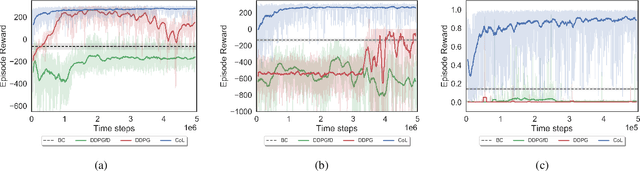
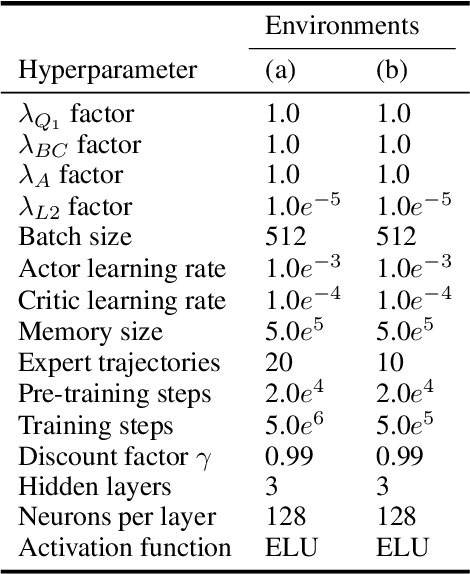
This paper investigates how to efficiently transition and update policies, trained initially with demonstrations, using off-policy actor-critic reinforcement learning. It is well-known that techniques based on Learning from Demonstrations, for example behavior cloning, can lead to proficient policies given limited data. However, it is currently unclear how to efficiently update that policy using reinforcement learning as these approaches are inherently optimizing different objective functions. Previous works have used loss functions which combine behavioral cloning losses with reinforcement learning losses to enable this update, however, the components of these loss functions are often set anecdotally, and their individual contributions are not well understood. In this work we propose the Cycle-of-Learning (CoL) framework that uses an actor-critic architecture with a loss function that combines behavior cloning and 1-step Q-learning losses with an off-policy pre-training step from human demonstrations. This enables transition from behavior cloning to reinforcement learning without performance degradation and improves reinforcement learning in terms of overall performance and training time. Additionally, we carefully study the composition of these combined losses and their impact on overall policy learning. We show that our approach outperforms state-of-the-art techniques for combining behavior cloning and reinforcement learning for both dense and sparse reward scenarios. Our results also suggest that directly including the behavior cloning loss on demonstration data helps to ensure stable learning and ground future policy updates.