 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Reward Learning from Human Ratings
Jun 10, 2025Reinforcement learning from human feeback (RLHF) has become a key factor in aligning model behavior with users' goals. However, while humans integrate multiple strategies when making decisions, current RLHF approaches often simplify this process by modeling human reasoning through isolated tasks such as classification or regression. In this paper, we propose a novel reinforcement learning (RL) method that mimics human decision-making by jointly considering multiple tasks. Specifically, we leverage human ratings in reward-free environments to infer a reward function, introducing learnable weights that balance the contributions of both classification and regression models. This design captures the inherent uncertainty in human decision-making and allows the model to adaptively emphasize different strategies. We conduct several experiments using synthetic human ratings to validate the effectiveness of the proposed approach. Results show that our method consistently outperforms existing rating-based RL methods, and in some cases, even surpasses traditional RL approaches.
Performance Optimization of Ratings-Based Reinforcement Learning
Jan 13, 2025



This paper explores multiple optimization methods to improve the performance of rating-based reinforcement learning (RbRL). RbRL, a method based on the idea of human ratings, has been developed to infer reward functions in reward-free environments for the subsequent policy learning via standard reinforcement learning, which requires the availability of reward functions. Specifically, RbRL minimizes the cross entropy loss that quantifies the differences between human ratings and estimated ratings derived from the inferred reward. Hence, a low loss means a high degree of consistency between human ratings and estimated ratings. Despite its simple form, RbRL has various hyperparameters and can be sensitive to various factors. Therefore, it is critical to provide comprehensive experiments to understand the impact of various hyperparameters on the performance of RbRL. This paper is a work in progress, providing users some general guidelines on how to select hyperparameters in RbRL.
RbRL2.0: Integrated Reward and Policy Learning for Rating-based Reinforcement Learning
Jan 13, 2025Reinforcement learning (RL), a common tool in decision making, learns policies from various experiences based on the associated cumulative return/rewards without treating them differently. On the contrary, humans often learn to distinguish from different levels of performance and extract the underlying trends towards improving their decision making for best performance. Motivated by this, this paper proposes a novel RL method that mimics humans' decision making process by differentiating among collected experiences for effective policy learning. The main idea is to extract important directional information from experiences with different performance levels, named ratings, so that policies can be updated towards desired deviation from these experiences with different ratings. Specifically, we propose a new policy loss function that penalizes distribution similarities between the current policy and failed experiences with different ratings, and assign different weights to the penalty terms based on the rating classes. Meanwhile, reward learning from these rated samples can be integrated with the new policy loss towards an integrated reward and policy learning from rated samples. Optimizing the integrated reward and policy loss function will lead to the discovery of directions for policy improvement towards maximizing cumulative rewards and penalizing most from the lowest performance level while least from the highest performance level. To evaluate the effectiveness of the proposed method, we present results for experiments on a few typical environments that show improved convergence and overall performance over the existing rating-based reinforcement learning method with only reward learning.
Rating-based Reinforcement Learning
Jul 30, 2023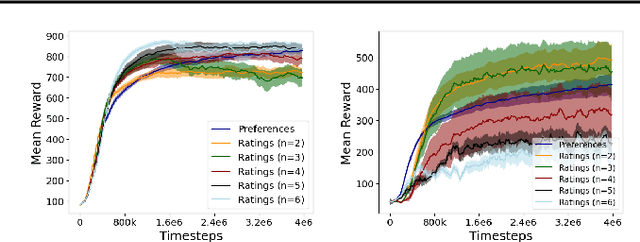

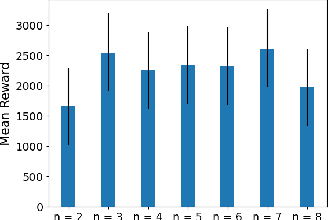
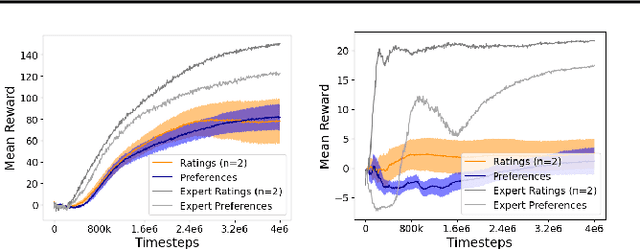
This paper develops a novel rating-based reinforcement learning approach that uses human ratings to obtain human guidance in reinforcement learning. Different from the existing preference-based and ranking-based reinforcement learning paradigms, based on human relative preferences over sample pairs, the proposed rating-based reinforcement learning approach is based on human evaluation of individual trajectories without relative comparisons between sample pairs. The rating-based reinforcement learning approach builds on a new prediction model for human ratings and a novel multi-class loss function. We conduct several experimental studies based on synthetic ratings and real human ratings to evaluate the effectiveness and benefits of the new rating-based reinforcement learning approach.
A Narration-based Reward Shaping Approach using Grounded Natural Language Commands
Oct 31, 2019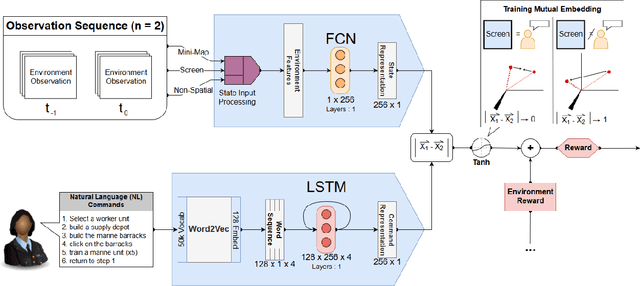
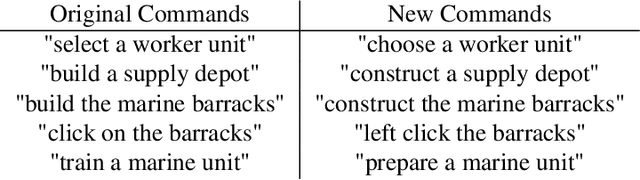
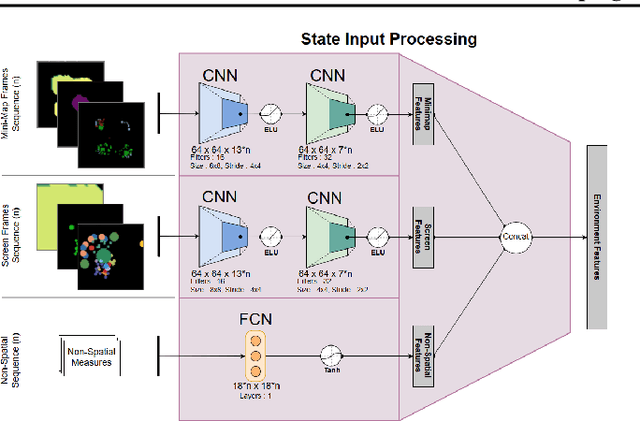
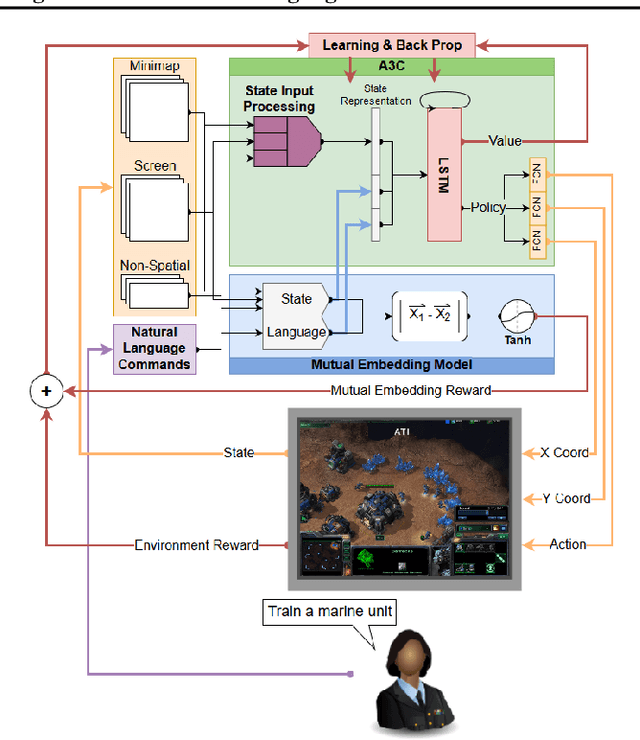
While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of reward sparsity. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we develop a technique that can provide the benefits of reward shaping using natural language commands. Our narration-guided RL agent projects sequences of natural-language commands into the same high-dimensional representation space as corresponding goal states. We show that we can get improved performance with our method compared to traditional reward-shaping approaches. Additionally, we demonstrate the ability of our method to generalize to unseen natural-language commands.
Grounding Natural Language Commands to StarCraft II Game States for Narration-Guided Reinforcement Learning
Apr 24, 2019While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of {\em reward sparsity}. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we investigate to what extent we can contextualize these narrations by grounding them to the goal-specific states. We present a mutual-embedding model using a multi-input deep-neural network that projects a sequence of natural language commands into the same high-dimensional representation space as corresponding goal states. We show that using this model we can learn an embedding space with separable and distinct clusters that accurately maps natural-language commands to corresponding game states . We also discuss how this model can allow for the use of narrations as a robust form of reward shaping to improve RL performance and efficiency.
Compact Convolutional Neural Networks for Classification of Asynchronous Steady-state Visual Evoked Potentials
Oct 09, 2018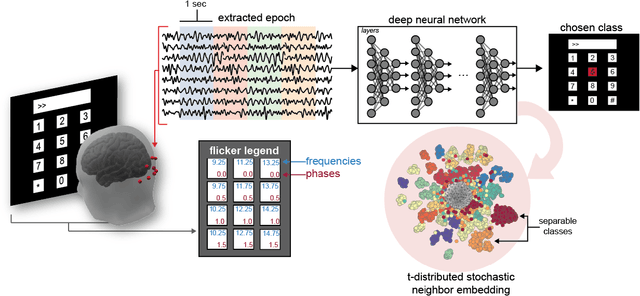

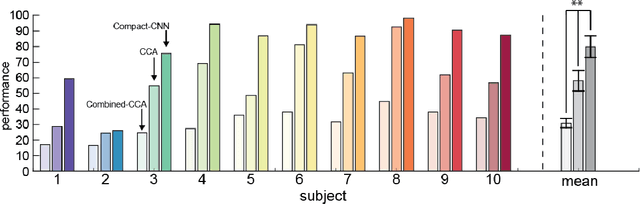
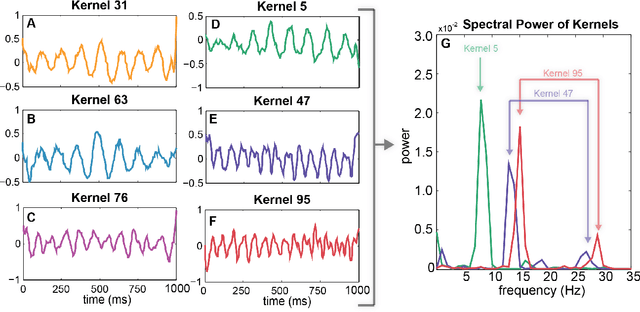
Steady-State Visual Evoked Potentials (SSVEPs) are neural oscillations from the parietal and occipital regions of the brain that are evoked from flickering visual stimuli. SSVEPs are robust signals measurable in the electroencephalogram (EEG) and are commonly used in brain-computer interfaces (BCIs). However, methods for high-accuracy decoding of SSVEPs usually require hand-crafted approaches that leverage domain-specific knowledge of the stimulus signals, such as specific temporal frequencies in the visual stimuli and their relative spatial arrangement. When this knowledge is unavailable, such as when SSVEP signals are acquired asynchronously, such approaches tend to fail. In this paper, we show how a compact convolutional neural network (Compact-CNN), which only requires raw EEG signals for automatic feature extraction, can be used to decode signals from a 12-class SSVEP dataset without the need for any domain-specific knowledge or calibration data. We report across subject mean accuracy of approximately 80% (chance being 8.3%) and show this is substantially better than current state-of-the-art hand-crafted approaches using canonical correlation analysis (CCA) and Combined-CCA. Furthermore, we analyze our Compact-CNN to examine the underlying feature representation, discovering that the deep learner extracts additional phase and amplitude related features associated with the structure of the dataset. We discuss how our Compact-CNN shows promise for BCI applications that allow users to freely gaze/attend to any stimulus at any time (e.g., asynchronous BCI) as well as provides a method for analyzing SSVEP signals in a way that might augment our understanding about the basic processing in the visual cortex.
Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces
Jan 19, 2018


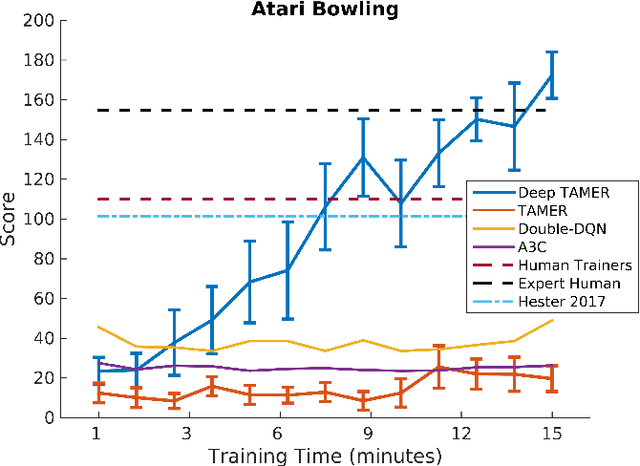
While recent advances in deep reinforcement learning have allowed autonomous learning agents to succeed at a variety of complex tasks, existing algorithms generally require a lot of training data. One way to increase the speed at which agents are able to learn to perform tasks is by leveraging the input of human trainers. Although such input can take many forms, real-time, scalar-valued feedback is especially useful in situations where it proves difficult or impossible for humans to provide expert demonstrations. Previous approaches have shown the usefulness of human input provided in this fashion (e.g., the TAMER framework), but they have thus far not considered high-dimensional state spaces or employed the use of deep learning. In this paper, we do both: we propose Deep TAMER, an extension of the TAMER framework that leverages the representational power of deep neural networks in order to learn complex tasks in just a short amount of time with a human trainer. We demonstrate Deep TAMER's success by using it and just 15 minutes of human-provided feedback to train an agent that performs better than humans on the Atari game of Bowling - a task that has proven difficult for even state-of-the-art reinforcement learning methods.