 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Score-Based Priors for Distribution Matching with Geometry-Preserving Regularization
Jun 17, 2025Distribution matching (DM) is a versatile domain-invariant representation learning technique that has been applied to tasks such as fair classification, domain adaptation, and domain translation. Non-parametric DM methods struggle with scalability and adversarial DM approaches suffer from instability and mode collapse. While likelihood-based methods are a promising alternative, they often impose unnecessary biases through fixed priors or require explicit density models (e.g., flows) that can be challenging to train. We address this limitation by introducing a novel approach to training likelihood-based DM using expressive score-based prior distributions. Our key insight is that gradient-based DM training only requires the prior's score function -- not its density -- allowing us to train the prior via denoising score matching. This approach eliminates biases from fixed priors (e.g., in VAEs), enabling more effective use of geometry-preserving regularization, while avoiding the challenge of learning an explicit prior density model (e.g., a flow-based prior). Our method also demonstrates better stability and computational efficiency compared to other diffusion-based priors (e.g., LSGM). Furthermore, experiments demonstrate superior performance across multiple tasks, establishing our score-based method as a stable and effective approach to distribution matching. Source code available at https://github.com/inouye-lab/SAUB.
* 32 pages, 20 figures. Accepted to ICML 2025
From Invariant Representations to Invariant Data: Provable Robustness to Spurious Correlations via Noisy Counterfactual Matching
May 30, 2025Spurious correlations can cause model performance to degrade in new environments. Prior causality-inspired works aim to learn invariant representations (e.g., IRM) but typically underperform empirical risk minimization (ERM). Recent alternatives improve robustness by leveraging test-time data, but such data may be unavailable in practice. To address these issues, we take a data-centric approach by leveraging invariant data pairs, pairs of samples that would have the same prediction with the optimally robust classifier. We prove that certain counterfactual pairs will naturally satisfy this invariance property and introduce noisy counterfactual matching (NCM), a simple constraint-based method for leveraging invariant pairs for enhanced robustness, even with a small set of noisy pairs-in the ideal case, each pair can eliminate one spurious feature. For linear causal models, we prove that the test domain error can be upper bounded by the in-domain error and a term that depends on the counterfactuals' diversity and quality. We validate on a synthetic dataset and demonstrate on real-world benchmarks that linear probing on a pretrained backbone improves robustness.
PO-Flow: Flow-based Generative Models for Sampling Potential Outcomes and Counterfactuals
May 21, 2025We propose PO-Flow, a novel continuous normalizing flow (CNF) framework for causal inference that jointly models potential outcomes and counterfactuals. Trained via flow matching, PO-Flow provides a unified framework for individualized potential outcome prediction, counterfactual predictions, and uncertainty-aware density learning. Among generative models, it is the first to enable density learning of potential outcomes without requiring explicit distributional assumptions (e.g., Gaussian mixtures), while also supporting counterfactual prediction conditioned on factual outcomes in general observational datasets. On benchmarks such as ACIC, IHDP, and IBM, it consistently outperforms prior methods across a range of causal inference tasks. Beyond that, PO-Flow succeeds in high-dimensional settings, including counterfactual image generation, demonstrating its broad applicability.
Att-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Mar 15, 2025

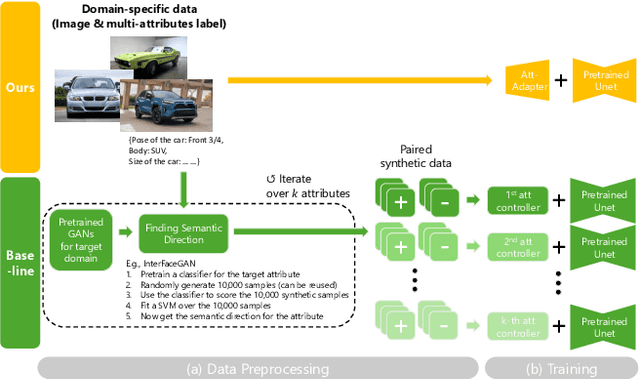

Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the Attribute (Att) Adapter, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning. We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world. Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
Vertical Validation: Evaluating Implicit Generative Models for Graphs on Thin Support Regions
Nov 20, 2024
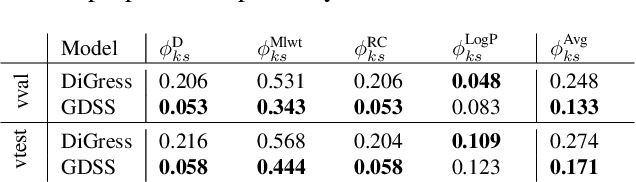

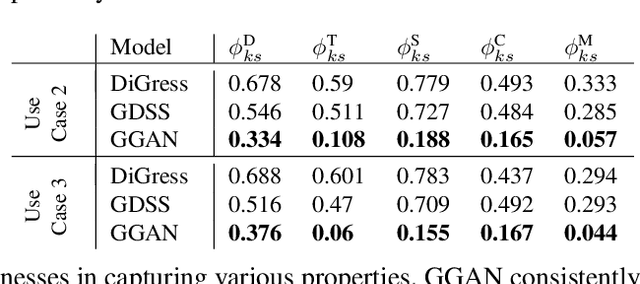
There has been a growing excitement that implicit graph generative models could be used to design or discover new molecules for medicine or material design. Because these molecules have not been discovered, they naturally lie in unexplored or scarcely supported regions of the distribution of known molecules. However, prior evaluation methods for implicit graph generative models have focused on validating statistics computed from the thick support (e.g., mean and variance of a graph property). Therefore, there is a mismatch between the goal of generating novel graphs and the evaluation methods. To address this evaluation gap, we design a novel evaluation method called Vertical Validation (VV) that systematically creates thin support regions during the train-test splitting procedure and then reweights generated samples so that they can be compared to the held-out test data. This procedure can be seen as a generalization of the standard train-test procedure except that the splits are dependent on sample features. We demonstrate that our method can be used to perform model selection if performance on thin support regions is the desired goal. As a side benefit, we also show that our approach can better detect overfitting as exemplified by memorization.
Counterfactual Fairness by Combining Factual and Counterfactual Predictions
Sep 03, 2024



In high-stake domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns. This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group. Previous works have proposed methods that guarantee CF. Notwithstanding, their effects on the model's predictive performance remains largely unclear. To fill in this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner. We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one without losing the optimality. By analyzing its excess risk in order to achieve CF, we quantify this inherent trade-off. Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted. Built upon it, we propose a performant algorithm that can be applied in such scenarios. Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
Decoupled Vertical Federated Learning for Practical Training on Vertically Partitioned Data
Mar 06, 2024Vertical Federated Learning (VFL) is an emergent distributed machine learning paradigm wherein owners of disjoint features of a common set of entities collaborate to learn a global model without sharing data. In VFL, a host client owns data labels for each entity and learns a final representation based on intermediate local representations from all guest clients. Therefore, the host is a single point of failure and label feedback can be used by malicious guest clients to infer private features. Requiring all participants to remain active and trustworthy throughout the entire training process is generally impractical and altogether infeasible outside of controlled environments. We propose Decoupled VFL (DVFL), a blockwise learning approach to VFL. By training each model on its own objective, DVFL allows for decentralized aggregation and isolation between feature learning and label supervision. With these properties, DVFL is fault tolerant and secure. We implement DVFL to train split neural networks and show that model performance is comparable to VFL on a variety of classification datasets.
StarCraftImage: A Dataset For Prototyping Spatial Reasoning Methods For Multi-Agent Environments
Jan 09, 2024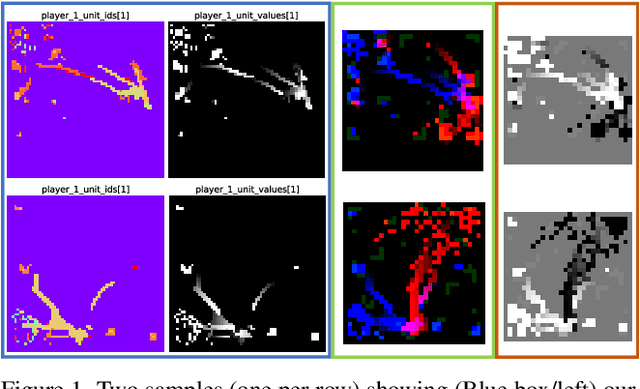
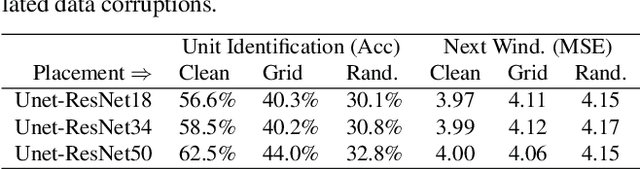
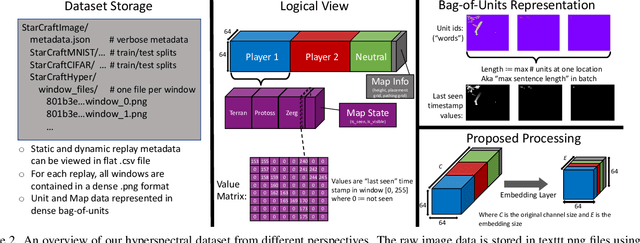
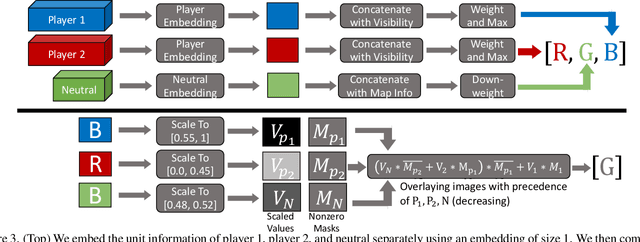
Spatial reasoning tasks in multi-agent environments such as event prediction, agent type identification, or missing data imputation are important for multiple applications (e.g., autonomous surveillance over sensor networks and subtasks for reinforcement learning (RL)). StarCraft II game replays encode intelligent (and adversarial) multi-agent behavior and could provide a testbed for these tasks; however, extracting simple and standardized representations for prototyping these tasks is laborious and hinders reproducibility. In contrast, MNIST and CIFAR10, despite their extreme simplicity, have enabled rapid prototyping and reproducibility of ML methods. Following the simplicity of these datasets, we construct a benchmark spatial reasoning dataset based on StarCraft II replays that exhibit complex multi-agent behaviors, while still being as easy to use as MNIST and CIFAR10. Specifically, we carefully summarize a window of 255 consecutive game states to create 3.6 million summary images from 60,000 replays, including all relevant metadata such as game outcome and player races. We develop three formats of decreasing complexity: Hyperspectral images that include one channel for every unit type (similar to multispectral geospatial images), RGB images that mimic CIFAR10, and grayscale images that mimic MNIST. We show how this dataset can be used for prototyping spatial reasoning methods. All datasets, code for extraction, and code for dataset loading can be found at https://starcraftdata.davidinouye.com
* Published in CVPR 23'
Fault-Tolerant Vertical Federated Learning on Dynamic Networks
Dec 27, 2023Vertical Federated learning (VFL) is a class of FL where each client shares the same sample space but only holds a subset of the features. While VFL tackles key privacy challenges of distributed learning, it often assumes perfect hardware and communication capabilities. This assumption hinders the broad deployment of VFL, particularly on edge devices, which are heterogeneous in their in-situ capabilities and will connect/disconnect from the network over time. To address this gap, we define Internet Learning (IL) including its data splitting and network context and which puts good performance under extreme dynamic condition of clients as the primary goal. We propose VFL as a naive baseline and develop several extensions to handle the IL paradigm of learning. Furthermore, we implement new methods, propose metrics, and extensively analyze results based on simulating a sensor network. The results show that the developed methods are more robust to changes in the network than VFL baseline.
Towards Practical Non-Adversarial Distribution Alignment via Variational Bounds
Oct 30, 2023Distribution alignment can be used to learn invariant representations with applications in fairness and robustness. Most prior works resort to adversarial alignment methods but the resulting minimax problems are unstable and challenging to optimize. Non-adversarial likelihood-based approaches either require model invertibility, impose constraints on the latent prior, or lack a generic framework for alignment. To overcome these limitations, we propose a non-adversarial VAE-based alignment method that can be applied to any model pipeline. We develop a set of alignment upper bounds (including a noisy bound) that have VAE-like objectives but with a different perspective. We carefully compare our method to prior VAE-based alignment approaches both theoretically and empirically. Finally, we demonstrate that our novel alignment losses can replace adversarial losses in standard invariant representation learning pipelines without modifying the original architectures -- thereby significantly broadening the applicability of non-adversarial alignment methods.