 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePO-Flow: Flow-based Generative Models for Sampling Potential Outcomes and Counterfactuals
May 21, 2025We propose PO-Flow, a novel continuous normalizing flow (CNF) framework for causal inference that jointly models potential outcomes and counterfactuals. Trained via flow matching, PO-Flow provides a unified framework for individualized potential outcome prediction, counterfactual predictions, and uncertainty-aware density learning. Among generative models, it is the first to enable density learning of potential outcomes without requiring explicit distributional assumptions (e.g., Gaussian mixtures), while also supporting counterfactual prediction conditioned on factual outcomes in general observational datasets. On benchmarks such as ACIC, IHDP, and IBM, it consistently outperforms prior methods across a range of causal inference tasks. Beyond that, PO-Flow succeeds in high-dimensional settings, including counterfactual image generation, demonstrating its broad applicability.
RAGAT-Mind: A Multi-Granular Modeling Approach for Rumor Detection Based on MindSpore
Apr 24, 2025



As false information continues to proliferate across social media platforms, effective rumor detection has emerged as a pressing challenge in natural language processing. This paper proposes RAGAT-Mind, a multi-granular modeling approach for Chinese rumor detection, built upon the MindSpore deep learning framework. The model integrates TextCNN for local semantic extraction, bidirectional GRU for sequential context learning, Multi-Head Self-Attention for global dependency focusing, and Bidirectional Graph Convolutional Networks (BiGCN) for structural representation of word co-occurrence graphs. Experiments on the Weibo1-Rumor dataset demonstrate that RAGAT-Mind achieves superior classification performance, attaining 99.2% accuracy and a macro-F1 score of 0.9919. The results validate the effectiveness of combining hierarchical linguistic features with graph-based semantic structures. Furthermore, the model exhibits strong generalization and interpretability, highlighting its practical value for real-world rumor detection applications.
Few-shot Hate Speech Detection Based on the MindSpore Framework
Apr 22, 2025



The proliferation of hate speech on social media poses a significant threat to online communities, requiring effective detection systems. While deep learning models have shown promise, their performance often deteriorates in few-shot or low-resource settings due to reliance on large annotated corpora. To address this, we propose MS-FSLHate, a prompt-enhanced neural framework for few-shot hate speech detection implemented on the MindSpore deep learning platform. The model integrates learnable prompt embeddings, a CNN-BiLSTM backbone with attention pooling, and synonym-based adversarial data augmentation to improve generalization. Experimental results on two benchmark datasets-HateXplain and HSOL-demonstrate that our approach outperforms competitive baselines in precision, recall, and F1-score. Additionally, the framework shows high efficiency and scalability, suggesting its suitability for deployment in resource-constrained environments. These findings highlight the potential of combining prompt-based learning with adversarial augmentation for robust and adaptable hate speech detection in few-shot scenarios.
MSTIM: A MindSpore-Based Model for Traffic Flow Prediction
Apr 18, 2025Aiming at the problems of low accuracy and large error fluctuation of traditional traffic flow predictionmodels when dealing with multi-scale temporal features and dynamic change patterns. this paperproposes a multi-scale time series information modelling model MSTIM based on the Mindspore framework, which integrates long and short-term memory networks (LSTMs), convolutional neural networks (CNN), and the attention mechanism to improve the modelling accuracy and stability. The Metropolitan Interstate Traffic Volume (MITV) dataset was used for the experiments and compared and analysed with typical LSTM-attention models, CNN-attention models and LSTM-CNN models. The experimental results show that the MSTIM model achieves better results in the metrics of Mean Absolute Error (MAE), Mean Square Error (MSE), and Root Mean Square Error (RMSE), which significantly improves the accuracy and stability of the traffic volume prediction.
Research on CNN-BiLSTM Network Traffic Anomaly Detection Model Based on MindSpore
Apr 14, 2025With the widespread adoption of the Internet of Things (IoT) and Industrial IoT (IIoT) technologies, network architectures have become increasingly complex, and the volume of traffic has grown substantially. This evolution poses significant challenges to traditional security mechanisms, particularly in detecting high-frequency, diverse, and highly covert network attacks. To address these challenges, this study proposes a novel network traffic anomaly detection model that integrates a Convolutional Neural Network (CNN) with a Bidirectional Long Short-Term Memory (BiLSTM) network, implemented on the MindSpore framework. Comprehensive experiments were conducted using the NF-BoT-IoT dataset. The results demonstrate that the proposed model achieves 99% across accuracy, precision, recall, and F1-score, indicating its strong performance and robustness in network intrusion detection tasks.
Graph-Based Prediction Models for Data Debiasing
Apr 12, 2025



Bias in data collection, arising from both under-reporting and over-reporting, poses significant challenges in critical applications such as healthcare and public safety. In this work, we introduce Graph-based Over- and Under-reporting Debiasing (GROUD), a novel graph-based optimization framework that debiases reported data by jointly estimating the true incident counts and the associated reporting bias probabilities. By modeling the bias as a smooth signal over a graph constructed from geophysical or feature-based similarities, our convex formulation not only ensures a unique solution but also comes with theoretical recovery guarantees under certain assumptions. We validate GROUD on both challenging simulated experiments and real-world datasets -- including Atlanta emergency calls and COVID-19 vaccine adverse event reports -- demonstrating its robustness and superior performance in accurately recovering debiased counts. This approach paves the way for more reliable downstream decision-making in systems affected by reporting irregularities.
Frequency-Aware Attention-LSTM for PM$_{2.5}$ Time Series Forecasting
Mar 31, 2025To enhance the accuracy and robustness of PM$_{2.5}$ concentration forecasting, this paper introduces FALNet, a Frequency-Aware LSTM Network that integrates frequency-domain decomposition, temporal modeling, and attention-based refinement. The model first applies STL and FFT to extract trend, seasonal, and denoised residual components, effectively filtering out high-frequency noise. The filtered residuals are then fed into a stacked LSTM to capture long-term dependencies, followed by a multi-head attention mechanism that dynamically focuses on key time steps. Experiments conducted on real-world urban air quality datasets demonstrate that FALNet consistently outperforms conventional models across standard metrics such as MAE, RMSE, and $R^2$. The model shows strong adaptability in capturing sharp fluctuations during pollution peaks and non-stationary conditions. These results validate the effectiveness and generalizability of FALNet for real-time air pollution prediction, environmental risk assessment, and decision-making support.
Annealing Flow Generative Model Towards Sampling High-Dimensional and Multi-Modal Distributions
Sep 30, 2024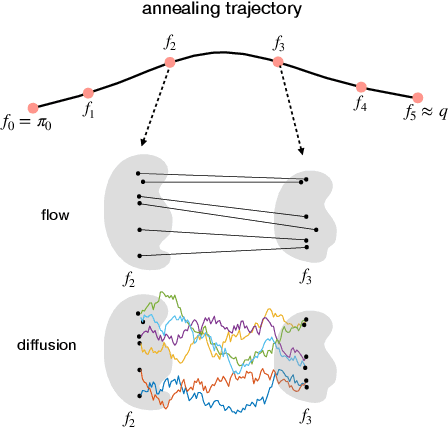



Sampling from high-dimensional, multi-modal distributions remains a fundamental challenge across domains such as statistical Bayesian inference and physics-based machine learning. In this paper, we propose Annealing Flow (AF), a continuous normalizing flow-based approach designed to sample from high-dimensional and multi-modal distributions. The key idea is to learn a continuous normalizing flow-based transport map, guided by annealing, to transition samples from an easy-to-sample distribution to the target distribution, facilitating effective exploration of modes in high-dimensional spaces. Unlike many existing methods, AF training does not rely on samples from the target distribution. AF ensures effective and balanced mode exploration, achieves linear complexity in sample size and dimensions, and circumvents inefficient mixing times. We demonstrate the superior performance of AF compared to state-of-the-art methods through extensive experiments on various challenging distributions and real-world datasets, particularly in high-dimensional and multi-modal settings. We also highlight the potential of AF for sampling the least favorable distributions.
Bayesian-Boosted MetaLoc: Efficient Training and Guaranteed Generalization for Indoor Localization
Sep 03, 2023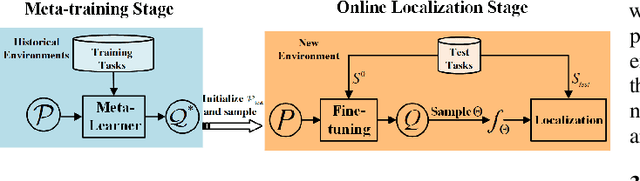
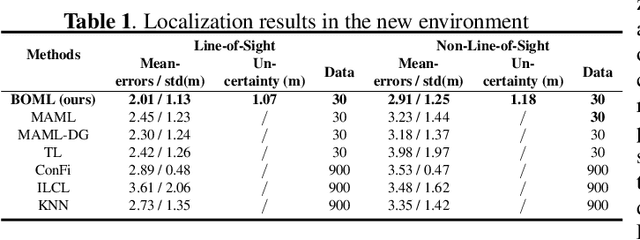
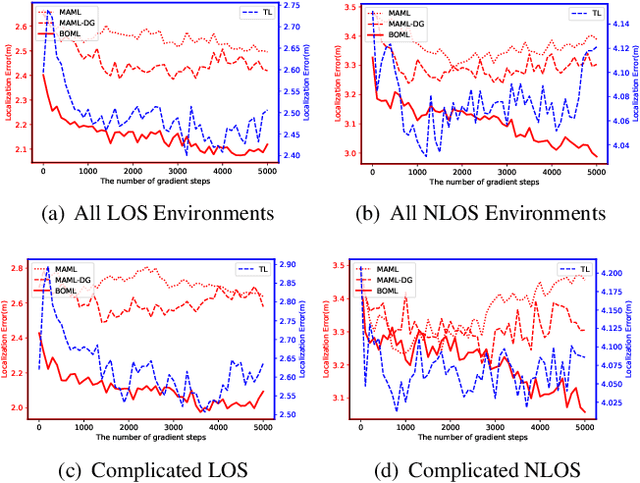
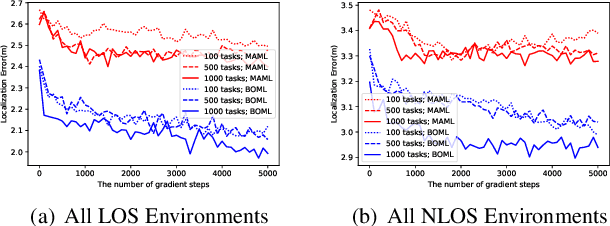
Existing localization approaches utilizing environment-specific channel state information (CSI) excel under specific environment but struggle to generalize across varied environments. This challenge becomes even more pronounced when confronted with limited training data. To address these issues, we present the Bayes-Optimal Meta-Learning for Localization (BOML-Loc) framework, inspired by the PAC-Optimal Hyper-Posterior (PACOH) algorithm. Improving on our earlier MetaLoc~\cite{MetaLoc}, BOML-Loc employs a Bayesian approach, reducing the need for extensive training, lowering overfitting risk, and offering per-test-point uncertainty estimation. Even with very limited training tasks, BOML-Loc guarantees robust localization and impressive generalization. In both LOS and NLOS environments with site-surveyed data, BOML-Loc surpasses existing models, demonstrating enhanced localization accuracy, generalization abilities, and reduced overfitting in new and previously unseen environments.
MetaLoc: Learning to Learn Wireless Localization
Nov 08, 2022



The existing indoor fingerprinting localization methods are rather accurate after intensive offline calibration for a specific environment, no matter based on received signal strength (RSS) or channel state information (CSI), but the well-calibrated localization model (can be a pure statistical one or a data-driven one) will present poor generalization ability in the highly variable environments, which results in big loss in knowledge and human effort. To break the environment-specific localization bottleneck, we propose a new-fashioned data-driven fingerprinting method for localization based on model-agnostic meta-learning (MAML), named by MetaLoc. Specifically, MetaLoc is char acterized by rapldly adapting itself to a new, possibly unseen environment with very little calibration. The underlying localization model is taken to be a deep neural network, and we train an optimal set of environment-specific meta-parameters by leveraging previous data collected from diverse well-calibrated indoor environments and the maximum mean discrepancy criterion. We further modify the loss function of vanilla MAML and propose a novel framework named as MAML-DG, which is able to achieve faster convergence and better adaptation abilities by forcing the loss on different training domains to decrease in similar directions. Experiments from simulation and site survey confirm that the meta-parameters obtained for MetaLoc achieves very rapid adaptation to new environments, competitive localization accuracy, and high resistance to significantly reduced reference points (RPs), saving a lot of calibration effort.