 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePL-FGSA: A Prompt Learning Framework for Fine-Grained Sentiment Analysis Based on MindSpore
May 20, 2025Fine-grained sentiment analysis (FGSA) aims to identify sentiment polarity toward specific aspects within a text, enabling more precise opinion mining in domains such as product reviews and social media. However, traditional FGSA approaches often require task-specific architectures and extensive annotated data, limiting their generalization and scalability. To address these challenges, we propose PL-FGSA, a unified prompt learning-based framework implemented using the MindSpore platform, which integrates prompt design with a lightweight TextCNN backbone. Our method reformulates FGSA as a multi-task prompt-augmented generation problem, jointly tackling aspect extraction, sentiment classification, and causal explanation in a unified paradigm. By leveraging prompt-based guidance, PL-FGSA enhances interpretability and achieves strong performance under both full-data and low-resource conditions. Experiments on three benchmark datasets-SST-2, SemEval-2014 Task 4, and MAMS-demonstrate that our model consistently outperforms traditional fine-tuning methods and achieves F1-scores of 0.922, 0.694, and 0.597, respectively. These results validate the effectiveness of prompt-based generalization and highlight the practical value of PL-FGSA for real-world sentiment analysis tasks.
MIA-Mind: A Multidimensional Interactive Attention Mechanism Based on MindSpore
Apr 27, 2025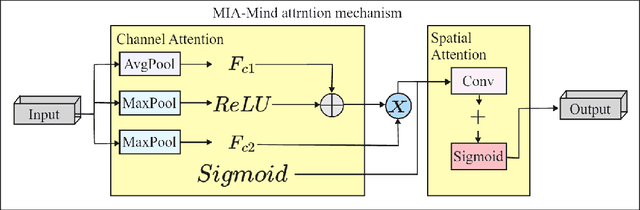

Attention mechanisms have significantly advanced deep learning by enhancing feature representation through selective focus. However, existing approaches often independently model channel importance and spatial saliency, overlooking their inherent interdependence and limiting their effectiveness. To address this limitation, we propose MIA-Mind, a lightweight and modular Multidimensional Interactive Attention Mechanism, built upon the MindSpore framework. MIA-Mind jointly models spatial and channel features through a unified cross-attentive fusion strategy, enabling fine-grained feature recalibration with minimal computational overhead. Extensive experiments are conducted on three representative datasets: on CIFAR-10, MIA-Mind achieves an accuracy of 82.9\%; on ISBI2012, it achieves an accuracy of 78.7\%; and on CIC-IDS2017, it achieves an accuracy of 91.9\%. These results validate the versatility, lightweight design, and generalization ability of MIA-Mind across heterogeneous tasks. Future work will explore the extension of MIA-Mind to large-scale datasets, the development of ada,ptive attention fusion strategies, and distributed deployment to further enhance scalability and robustness.
RAGAT-Mind: A Multi-Granular Modeling Approach for Rumor Detection Based on MindSpore
Apr 24, 2025



As false information continues to proliferate across social media platforms, effective rumor detection has emerged as a pressing challenge in natural language processing. This paper proposes RAGAT-Mind, a multi-granular modeling approach for Chinese rumor detection, built upon the MindSpore deep learning framework. The model integrates TextCNN for local semantic extraction, bidirectional GRU for sequential context learning, Multi-Head Self-Attention for global dependency focusing, and Bidirectional Graph Convolutional Networks (BiGCN) for structural representation of word co-occurrence graphs. Experiments on the Weibo1-Rumor dataset demonstrate that RAGAT-Mind achieves superior classification performance, attaining 99.2% accuracy and a macro-F1 score of 0.9919. The results validate the effectiveness of combining hierarchical linguistic features with graph-based semantic structures. Furthermore, the model exhibits strong generalization and interpretability, highlighting its practical value for real-world rumor detection applications.
Few-shot Hate Speech Detection Based on the MindSpore Framework
Apr 22, 2025



The proliferation of hate speech on social media poses a significant threat to online communities, requiring effective detection systems. While deep learning models have shown promise, their performance often deteriorates in few-shot or low-resource settings due to reliance on large annotated corpora. To address this, we propose MS-FSLHate, a prompt-enhanced neural framework for few-shot hate speech detection implemented on the MindSpore deep learning platform. The model integrates learnable prompt embeddings, a CNN-BiLSTM backbone with attention pooling, and synonym-based adversarial data augmentation to improve generalization. Experimental results on two benchmark datasets-HateXplain and HSOL-demonstrate that our approach outperforms competitive baselines in precision, recall, and F1-score. Additionally, the framework shows high efficiency and scalability, suggesting its suitability for deployment in resource-constrained environments. These findings highlight the potential of combining prompt-based learning with adversarial augmentation for robust and adaptable hate speech detection in few-shot scenarios.
MAAM: A Lightweight Multi-Agent Aggregation Module for Efficient Image Classification Based on the MindSpore Framework
Apr 18, 2025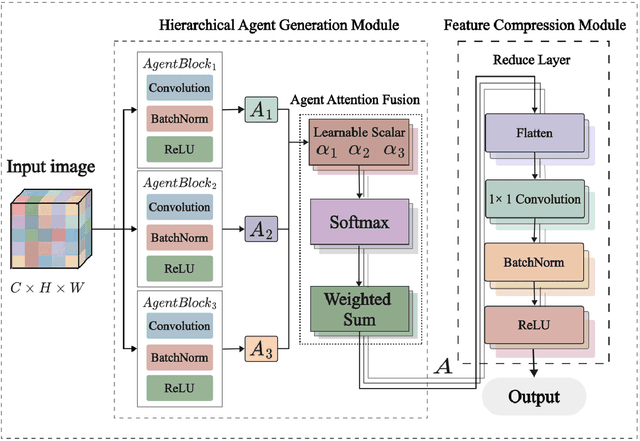
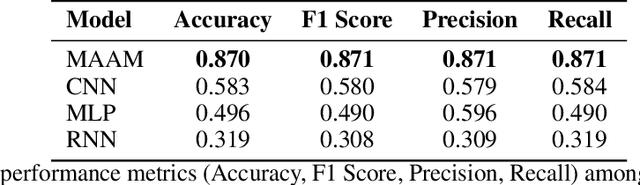
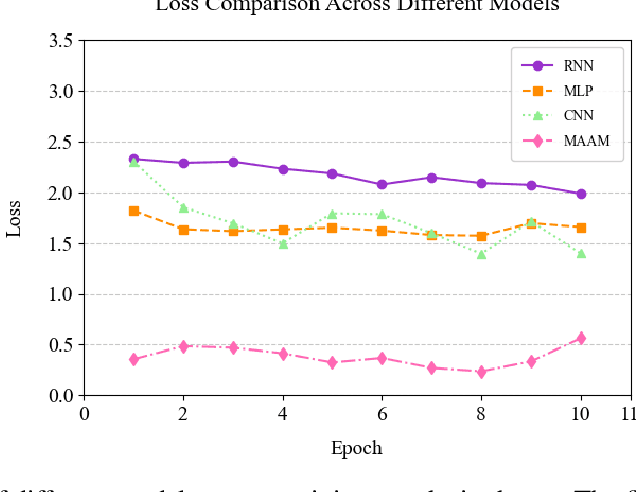
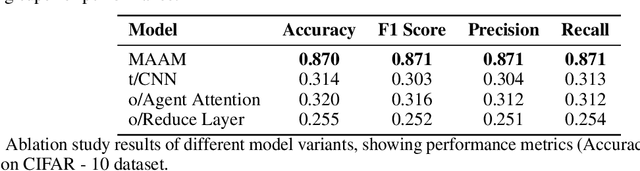
The demand for lightweight models in image classification tasks under resource-constrained environments necessitates a balance between computational efficiency and robust feature representation. Traditional attention mechanisms, despite their strong feature modeling capability, often struggle with high computational complexity and structural rigidity, limiting their applicability in scenarios with limited computational resources (e.g., edge devices or real-time systems). To address this, we propose the Multi-Agent Aggregation Module (MAAM), a lightweight attention architecture integrated with the MindSpore framework. MAAM employs three parallel agent branches with independently parameterized operations to extract heterogeneous features, adaptively fused via learnable scalar weights, and refined through a convolutional compression layer. Leveraging MindSpore's dynamic computational graph and operator fusion, MAAM achieves 87.0% accuracy on the CIFAR-10 dataset, significantly outperforming conventional CNN (58.3%) and MLP (49.6%) models, while improving training efficiency by 30%. Ablation studies confirm the critical role of agent attention (accuracy drops to 32.0% if removed) and compression modules (25.5% if omitted), validating their necessity for maintaining discriminative feature learning. The framework's hardware acceleration capabilities and minimal memory footprint further demonstrate its practicality, offering a deployable solution for image classification in resource-constrained scenarios without compromising accuracy.
MSTIM: A MindSpore-Based Model for Traffic Flow Prediction
Apr 18, 2025Aiming at the problems of low accuracy and large error fluctuation of traditional traffic flow predictionmodels when dealing with multi-scale temporal features and dynamic change patterns. this paperproposes a multi-scale time series information modelling model MSTIM based on the Mindspore framework, which integrates long and short-term memory networks (LSTMs), convolutional neural networks (CNN), and the attention mechanism to improve the modelling accuracy and stability. The Metropolitan Interstate Traffic Volume (MITV) dataset was used for the experiments and compared and analysed with typical LSTM-attention models, CNN-attention models and LSTM-CNN models. The experimental results show that the MSTIM model achieves better results in the metrics of Mean Absolute Error (MAE), Mean Square Error (MSE), and Root Mean Square Error (RMSE), which significantly improves the accuracy and stability of the traffic volume prediction.
Research on CNN-BiLSTM Network Traffic Anomaly Detection Model Based on MindSpore
Apr 14, 2025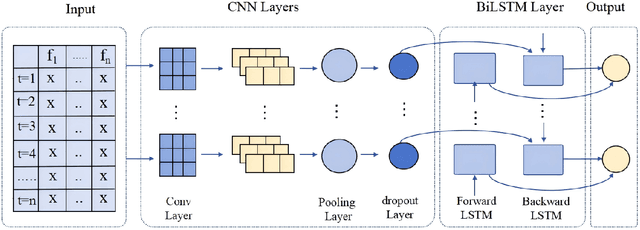
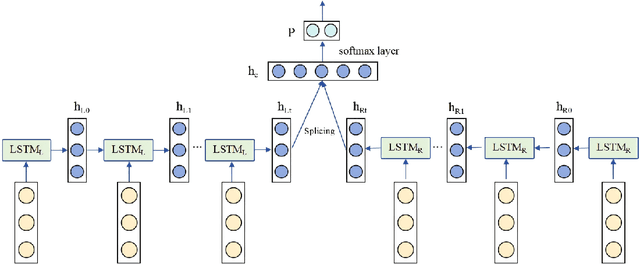
With the widespread adoption of the Internet of Things (IoT) and Industrial IoT (IIoT) technologies, network architectures have become increasingly complex, and the volume of traffic has grown substantially. This evolution poses significant challenges to traditional security mechanisms, particularly in detecting high-frequency, diverse, and highly covert network attacks. To address these challenges, this study proposes a novel network traffic anomaly detection model that integrates a Convolutional Neural Network (CNN) with a Bidirectional Long Short-Term Memory (BiLSTM) network, implemented on the MindSpore framework. Comprehensive experiments were conducted using the NF-BoT-IoT dataset. The results demonstrate that the proposed model achieves 99% across accuracy, precision, recall, and F1-score, indicating its strong performance and robustness in network intrusion detection tasks.
Frequency-Aware Attention-LSTM for PM$_{2.5}$ Time Series Forecasting
Mar 31, 2025To enhance the accuracy and robustness of PM$_{2.5}$ concentration forecasting, this paper introduces FALNet, a Frequency-Aware LSTM Network that integrates frequency-domain decomposition, temporal modeling, and attention-based refinement. The model first applies STL and FFT to extract trend, seasonal, and denoised residual components, effectively filtering out high-frequency noise. The filtered residuals are then fed into a stacked LSTM to capture long-term dependencies, followed by a multi-head attention mechanism that dynamically focuses on key time steps. Experiments conducted on real-world urban air quality datasets demonstrate that FALNet consistently outperforms conventional models across standard metrics such as MAE, RMSE, and $R^2$. The model shows strong adaptability in capturing sharp fluctuations during pollution peaks and non-stationary conditions. These results validate the effectiveness and generalizability of FALNet for real-time air pollution prediction, environmental risk assessment, and decision-making support.
Innovative LSGTime Model for Crime Spatiotemporal Prediction Based on MindSpore Framework
Mar 26, 2025With the acceleration of urbanization, the spatiotemporal characteristics of criminal activities have become increasingly complex. Accurate prediction of crime distribution is crucial for optimizing the allocation of police resources and preventing crime. This paper proposes LGSTime, a crime spatiotemporal prediction model that integrates Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and the Multi-head Sparse Self-attention mechanism. LSTM and GRU capture long-term dependencies in crime time series, such as seasonality and periodicity, through their unique gating mechanisms. The Multi-head Sparse Self-attention mechanism, on the other hand, focuses on both temporal and spatial features of criminal events simultaneously through parallel processing and sparsification techniques, significantly improving computational efficiency and prediction accuracy. The integrated model leverages the strengths of each technique to better handle complex spatiotemporal data. Experimental findings demonstrate that the model attains optimal performance across four real - world crime datasets. In comparison to the CNN model, it exhibits performance enhancements of 2.8\%, 1.9\%, and 1.4\% in the Mean Squared Error (MSE), Mean Absolute Error (MAE), and Root Mean Squared Error (RMSE) metrics respectively. These results offer a valuable reference for tackling the challenges in crime prediction.
KEDformer:Knowledge Extraction Seasonal Trend Decomposition for Long-term Sequence Prediction
Dec 06, 2024



Time series forecasting is a critical task in domains such as energy, finance, and meteorology, where accurate long-term predictions are essential. While Transformer-based models have shown promise in capturing temporal dependencies, their application to extended sequences is limited by computational inefficiencies and limited generalization. In this study, we propose KEDformer, a knowledge extraction-driven framework that integrates seasonal-trend decomposition to address these challenges. KEDformer leverages knowledge extraction methods that focus on the most informative weights within the self-attention mechanism to reduce computational overhead. Additionally, the proposed KEDformer framework decouples time series into seasonal and trend components. This decomposition enhances the model's ability to capture both short-term fluctuations and long-term patterns. Extensive experiments on five public datasets from energy, transportation, and weather domains demonstrate the effectiveness and competitiveness of KEDformer, providing an efficient solution for long-term time series forecasting.