 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Invariant Representations to Invariant Data: Provable Robustness to Spurious Correlations via Noisy Counterfactual Matching
May 30, 2025Spurious correlations can cause model performance to degrade in new environments. Prior causality-inspired works aim to learn invariant representations (e.g., IRM) but typically underperform empirical risk minimization (ERM). Recent alternatives improve robustness by leveraging test-time data, but such data may be unavailable in practice. To address these issues, we take a data-centric approach by leveraging invariant data pairs, pairs of samples that would have the same prediction with the optimally robust classifier. We prove that certain counterfactual pairs will naturally satisfy this invariance property and introduce noisy counterfactual matching (NCM), a simple constraint-based method for leveraging invariant pairs for enhanced robustness, even with a small set of noisy pairs-in the ideal case, each pair can eliminate one spurious feature. For linear causal models, we prove that the test domain error can be upper bounded by the in-domain error and a term that depends on the counterfactuals' diversity and quality. We validate on a synthetic dataset and demonstrate on real-world benchmarks that linear probing on a pretrained backbone improves robustness.
Counterfactual Fairness by Combining Factual and Counterfactual Predictions
Sep 03, 2024



In high-stake domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns. This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group. Previous works have proposed methods that guarantee CF. Notwithstanding, their effects on the model's predictive performance remains largely unclear. To fill in this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner. We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one without losing the optimality. By analyzing its excess risk in order to achieve CF, we quantify this inherent trade-off. Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted. Built upon it, we propose a performant algorithm that can be applied in such scenarios. Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
Benchmarking Algorithms for Federated Domain Generalization
Jul 11, 2023



While prior domain generalization (DG) benchmarks consider train-test dataset heterogeneity, we evaluate Federated DG which introduces federated learning (FL) specific challenges. Additionally, we explore domain-based heterogeneity in clients' local datasets - a realistic Federated DG scenario. Prior Federated DG evaluations are limited in terms of the number or heterogeneity of clients and dataset diversity. To address this gap, we propose an Federated DG benchmark methodology that enables control of the number and heterogeneity of clients and provides metrics for dataset difficulty. We then apply our methodology to evaluate 13 Federated DG methods, which include centralized DG methods adapted to the FL context, FL methods that handle client heterogeneity, and methods designed specifically for Federated DG. Our results suggest that despite some progress, there remain significant performance gaps in Federated DG particularly when evaluating with a large number of clients, high client heterogeneity, or more realistic datasets. Please check our extendable benchmark code here: https://github.com/inouye-lab/FedDG_Benchmark.
Towards Characterizing Domain Counterfactuals For Invertible Latent Causal Models
Jun 20, 2023



Learning latent causal models from data has many important applications such as robustness, model extrapolation, and counterfactuals. Most prior theoretic work has focused on full causal discovery (i.e., recovering the true latent variables) but requires strong assumptions such as linearity or fails to have any analysis of the equivalence class of solutions (e.g., IRM). Instead of full causal discovery, we focus on a specific type of causal query called the domain counterfactual, which hypothesizes what a sample would have looked like if it had been generated in a different domain (or environment). Concretely, we assume domain-specific invertible latent structural causal models and a shared invertible observation function, both of which are less restrictive assumptions than prior theoretic works. Under these assumptions, we define domain counterfactually equivalent models and prove that any model can be transformed into an equivalent model via two invertible functions. This constructive property provides a tight characterization of the domain counterfactual equivalence classes. Building upon this result, we prove that every equivalence class contains a model where all intervened variables are at the end when topologically sorted by the causal DAG, i.e., all non-intervened variables have non-intervened ancestors. This surprising result suggests that an algorithm that only allows intervention in the last $k$ latent variables may improve model estimation for counterfactuals. In experiments, we enforce the sparse intervention hypothesis via this theoretic result by constraining that the latent SCMs can only differ in the last few causal mechanisms and demonstrate the feasibility of this algorithm in simulated and image-based experiments.
Exploring Adversarial Examples via Invertible Neural Networks
Dec 24, 2020

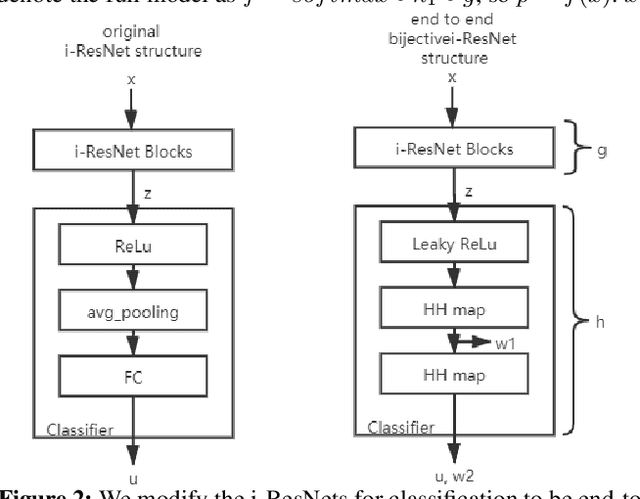

Adversarial examples (AEs) are images that can mislead deep neural network (DNN) classifiers via introducing slight perturbations into original images. This security vulnerability has led to vast research in recent years because it can introduce real-world threats into systems that rely on neural networks. Yet, a deep understanding of the characteristics of adversarial examples has remained elusive. We propose a new way of achieving such understanding through a recent development, namely, invertible neural models with Lipschitz continuous mapping functions from the input to the output. With the ability to invert any latent representation back to its corresponding input image, we can investigate adversarial examples at a deeper level and disentangle the adversarial example's latent representation. Given this new perspective, we propose a fast latent space adversarial example generation method that could accelerate adversarial training. Moreover, this new perspective could contribute to new ways of adversarial example detection.