 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Place-Based Compromises Between Two Points of View
Apr 27, 2026Large Language Models (LLMs) excel academically but struggle with social intelligence tasks, such as creating good compromises. In this paper, we present methods for generating empathically neutral compromises between two opposing viewpoints. We first compared four different prompt engineering methods using Claude 3 Opus and a dataset of 2,400 contrasting views on shared places. A subset of the gen erated compromises was evaluated for acceptability in a 50-participant study. We found that the best method for generating compromises between two views used external empathic similarity between a compromise and each viewpoint as iterative feedback, outperforming stan dard Chain of Thought (CoT) reasoning. The results indicate that the use of empathic neutrality improves the acceptability of compromises. The dataset of generated compromises was then used to train two smaller foundation models via margin-based alignment of human preferences, improving efficiency and removing the need for empathy estimation during inference.
Personagram: Bridging Personas and Product Design for Creative Ideation with Multimodal LLMs
Feb 05, 2026Product designers often begin their design process with handcrafted personas. While personas are intended to ground design decisions in consumer preferences, they often fall short in practice by remaining abstract, expensive to produce, and difficult to translate into actionable design features. As a result, personas risk serving as static reference points rather than tools that actively shape design outcomes. To address these challenges, we built Personagram, an interactive system powered by multimodal large language models (MLLMs) that helps designers explore detailed census-based personas, extract product features inferred from persona attributes, and recombine them for specific customer segments. In a study with 12 professional designers, we show that Personagram facilitates more actionable ideation workflows by structuring multimodal thinking from persona attributes to product design features, achieving higher engagement with personas, perceived transparency, and satisfaction compared to a chat-based baseline. We discuss implications of integrating AI-generated personas into product design workflows.
ShaLa: Multimodal Shared Latent Space Modelling
Aug 24, 2025This paper presents a novel generative framework for learning shared latent representations across multimodal data. Many advanced multimodal methods focus on capturing all combinations of modality-specific details across inputs, which can inadvertently obscure the high-level semantic concepts that are shared across modalities. Notably, Multimodal VAEs with low-dimensional latent variables are designed to capture shared representations, enabling various tasks such as joint multimodal synthesis and cross-modal inference. However, multimodal VAEs often struggle to design expressive joint variational posteriors and suffer from low-quality synthesis. In this work, ShaLa addresses these challenges by integrating a novel architectural inference model and a second-stage expressive diffusion prior, which not only facilitates effective inference of shared latent representation but also significantly improves the quality of downstream multimodal synthesis. We validate ShaLa extensively across multiple benchmarks, demonstrating superior coherence and synthesis quality compared to state-of-the-art multimodal VAEs. Furthermore, ShaLa scales to many more modalities while prior multimodal VAEs have fallen short in capturing the increasing complexity of the shared latent space.
Learning to Represent Individual Differences for Choice Decision Making
Mar 27, 2025Human decision making can be challenging to predict because decisions are affected by a number of complex factors. Adding to this complexity, decision-making processes can differ considerably between individuals, and methods aimed at predicting human decisions need to take individual differences into account. Behavioral science offers methods by which to measure individual differences (e.g., questionnaires, behavioral models), but these are often narrowed down to low dimensions and not tailored to specific prediction tasks. This paper investigates the use of representation learning to measure individual differences from behavioral experiment data. Representation learning offers a flexible approach to create individual embeddings from data that are both structured (e.g., demographic information) and unstructured (e.g., free text), where the flexibility provides more options for individual difference measures for personalization, e.g., free text responses may allow for open-ended questions that are less privacy-sensitive. In the current paper we use representation learning to characterize individual differences in human performance on an economic decision-making task. We demonstrate that models using representation learning to capture individual differences consistently improve decision predictions over models without representation learning, and even outperform well-known theory-based behavioral models used in these environments. Our results propose that representation learning offers a useful and flexible tool to capture individual differences.
Att-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Mar 15, 2025

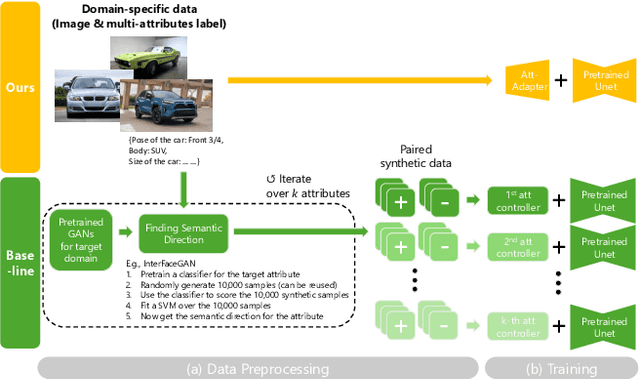

Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the Attribute (Att) Adapter, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning. We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world. Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
Inkspire: Supporting Design Exploration with Generative AI through Analogical Sketching
Jan 30, 2025



With recent advancements in the capabilities of Text-to-Image (T2I) AI models, product designers have begun experimenting with them in their work. However, T2I models struggle to interpret abstract language and the current user experience of T2I tools can induce design fixation rather than a more iterative, exploratory process. To address these challenges, we developed Inkspire, a sketch-driven tool that supports designers in prototyping product design concepts with analogical inspirations and a complete sketch-to-design-to-sketch feedback loop. To inform the design of Inkspire, we conducted an exchange session with designers and distilled design goals for improving T2I interactions. In a within-subjects study comparing Inkspire to ControlNet, we found that Inkspire supported designers with more inspiration and exploration of design ideas, and improved aspects of the co-creative process by allowing designers to effectively grasp the current state of the AI to guide it towards novel design intentions.
Stylish and Functional: Guided Interpolation Subject to Physical Constraints
Dec 20, 2024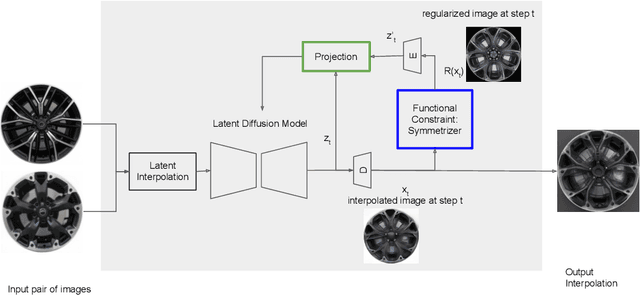



Generative AI is revolutionizing engineering design practices by enabling rapid prototyping and manipulation of designs. One example of design manipulation involves taking two reference design images and using them as prompts to generate a design image that combines aspects of both. Real engineering designs have physical constraints and functional requirements in addition to aesthetic design considerations. Internet-scale foundation models commonly used for image generation, however, are unable to take these physical constraints and functional requirements into consideration as part of the generation process. We consider the problem of generating a design inspired by two input designs, and propose a zero-shot framework toward enforcing physical, functional requirements over the generation process by leveraging a pretrained diffusion model as the backbone. As a case study, we consider the example of rotational symmetry in generation of wheel designs. Automotive wheels are required to be rotationally symmetric for physical stability. We formulate the requirement of rotational symmetry by the use of a symmetrizer, and we use this symmetrizer to guide the diffusion process towards symmetric wheel generations. Our experimental results find that the proposed approach makes generated interpolations with higher realism than methods in related work, as evaluated by Fr\'echet inception distance (FID). We also find that our approach generates designs that more closely satisfy physical and functional requirements than generating without the symmetry guidance.
Understanding the Cognitive Complexity in Language Elicited by Product Images
Sep 25, 2024Product images (e.g., a phone) can be used to elicit a diverse set of consumer-reported features expressed through language, including surface-level perceptual attributes (e.g., "white") and more complex ones, like perceived utility (e.g., "battery"). The cognitive complexity of elicited language reveals the nature of cognitive processes and the context required to understand them; cognitive complexity also predicts consumers' subsequent choices. This work offers an approach for measuring and validating the cognitive complexity of human language elicited by product images, providing a tool for understanding the cognitive processes of human as well as virtual respondents simulated by Large Language Models (LLMs). We also introduce a large dataset that includes diverse descriptive labels for product images, including human-rated complexity. We demonstrate that human-rated cognitive complexity can be approximated using a set of natural language models that, combined, roughly capture the complexity construct. Moreover, this approach is minimally supervised and scalable, even in use cases with limited human assessment of complexity.
Accelerating Understanding of Scientific Experiments with End to End Symbolic Regression
Dec 07, 2021
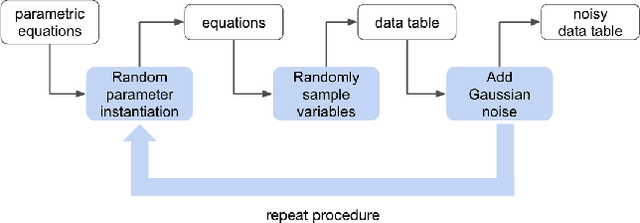
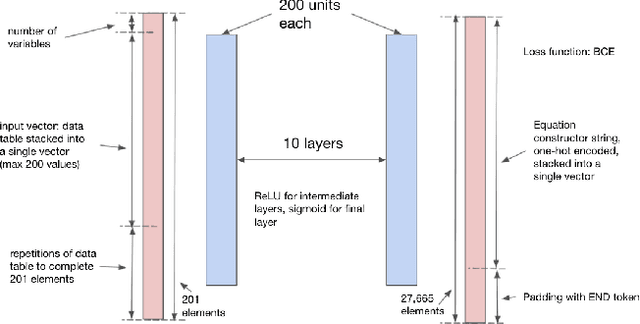
We consider the problem of learning free-form symbolic expressions from raw data, such as that produced by an experiment in any scientific domain. Accurate and interpretable models of scientific phenomena are the cornerstone of scientific research. Simple yet interpretable models, such as linear or logistic regression and decision trees often lack predictive accuracy. Alternatively, accurate blackbox models such as deep neural networks provide high predictive accuracy, but do not readily admit human understanding in a way that would enrich the scientific theory of the phenomenon. Many great breakthroughs in science revolve around the development of parsimonious equational models with high predictive accuracy, such as Newton's laws, universal gravitation, and Maxwell's equations. Previous work on automating the search of equational models from data combine domain-specific heuristics as well as computationally expensive techniques, such as genetic programming and Monte-Carlo search. We develop a deep neural network (MACSYMA) to address the symbolic regression problem as an end-to-end supervised learning problem. MACSYMA can generate symbolic expressions that describe a dataset. The computational complexity of the task is reduced to the feedforward computation of a neural network. We train our neural network on a synthetic dataset consisting of data tables of varying length and varying levels of noise, for which the neural network must learn to produce the correct symbolic expression token by token. Finally, we validate our technique by running on a public dataset from behavioral science.
Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021
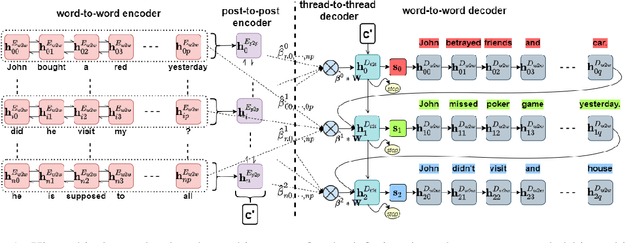

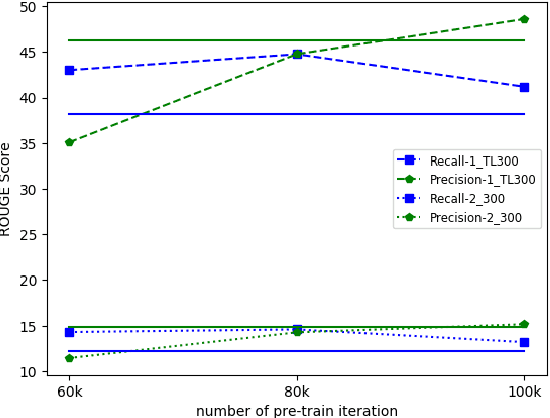
Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.