 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Average Feature Augmentation for Robust Semantic Segmentation with Transformers
Dec 02, 2024



Robustness to out-of-distribution data is crucial for deploying modern neural networks. Recently, Vision Transformers, such as SegFormer for semantic segmentation, have shown impressive robustness to visual corruptions like blur or noise affecting the acquisition device. In this paper, we propose Channel Wise Feature Augmentation (CWFA), a simple yet efficient feature augmentation technique to improve the robustness of Vision Transformers for semantic segmentation. CWFA applies a globally estimated perturbation per encoder with minimal compute overhead during training. Extensive evaluations on Cityscapes and ADE20K, with three state-of-the-art Vision Transformer architectures : SegFormer, Swin Transformer, and Twins demonstrate that CWFA-enhanced models significantly improve robustness without affecting clean data performance. For instance, on Cityscapes, a CWFA-augmented SegFormer-B1 model yields up to 27.7% mIoU robustness gain on impulse noise compared to the non-augmented SegFormer-B1. Furthermore, CWFA-augmented SegFormer-B5 achieves a new state-of-the-art 84.3% retention rate, a 0.7% improvement over the recently published FAN+STL.
Extended Self-Critical Pipeline for Transforming Videos to Text (TRECVID-VTT Task 2021) -- Team: MMCUniAugsburg
Dec 28, 2021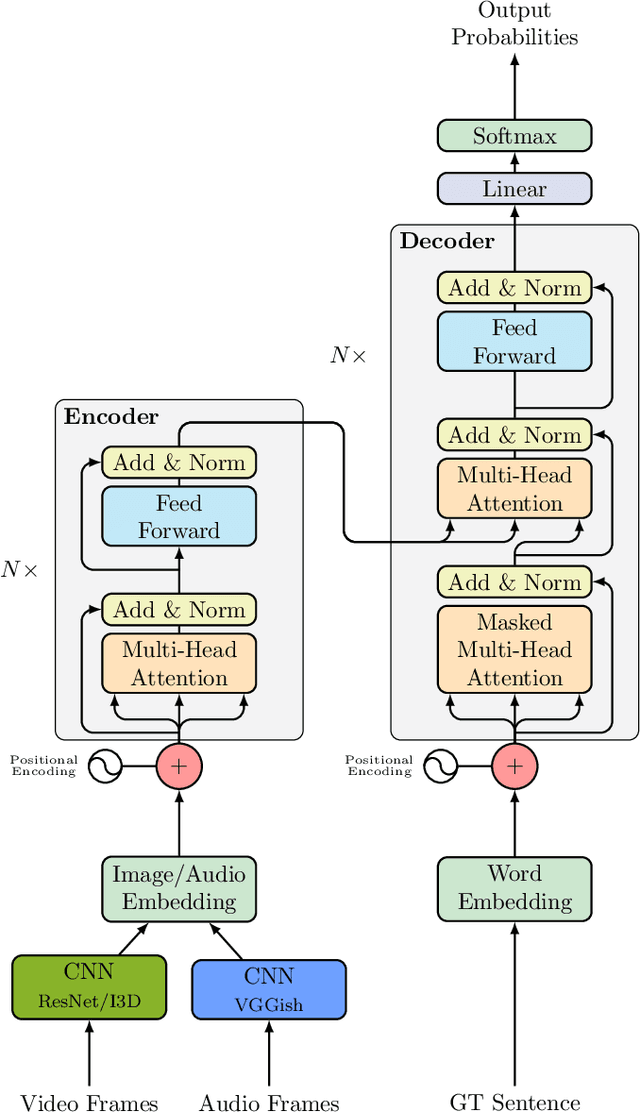

The Multimedia and Computer Vision Lab of the University of Augsburg participated in the VTT task only. We use the VATEX and TRECVID-VTT datasets for training our VTT models. We base our model on the Transformer approach for both of our submitted runs. For our second model, we adapt the X-Linear Attention Networks for Image Captioning which does not yield the desired bump in scores. For both models, we train on the complete VATEX dataset and 90% of the TRECVID-VTT dataset for pretraining while using the remaining 10% for validation. We finetune both models with self-critical sequence training, which boosts the validation performance significantly. Overall, we find that training a Video-to-Text system on traditional Image Captioning pipelines delivers very poor performance. When switching to a Transformer-based architecture our results greatly improve and the generated captions match better with the corresponding video.
Synchronized Audio-Visual Frames with Fractional Positional Encoding for Transformers in Video-to-Text Translation
Dec 28, 2021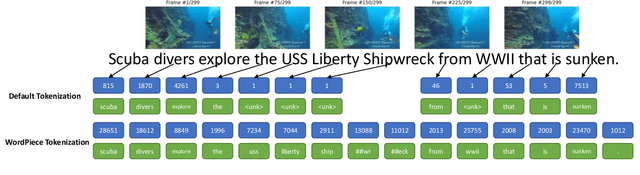
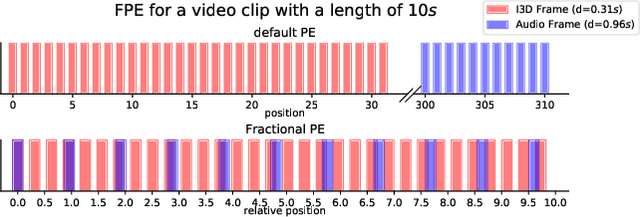
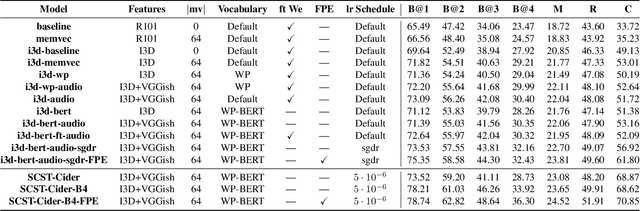
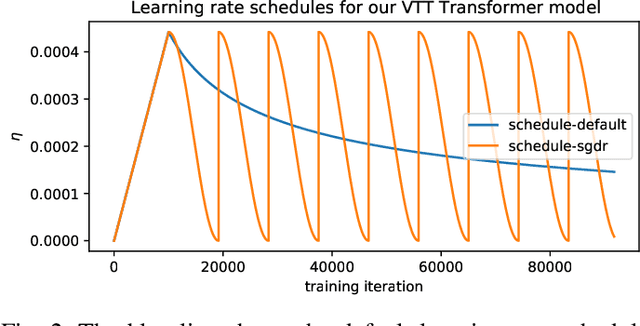
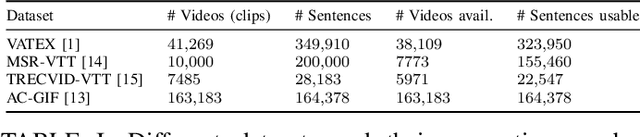
Video-to-Text (VTT) is the task of automatically generating descriptions for short audio-visual video clips, which can support visually impaired people to understand scenes of a YouTube video for instance. Transformer architectures have shown great performance in both machine translation and image captioning, lacking a straightforward and reproducible application for VTT. However, there is no comprehensive study on different strategies and advice for video description generation including exploiting the accompanying audio with fully self-attentive networks. Thus, we explore promising approaches from image captioning and video processing and apply them to VTT by developing a straightforward Transformer architecture. Additionally, we present a novel way of synchronizing audio and video features in Transformers which we call Fractional Positional Encoding (FPE). We run multiple experiments on the VATEX dataset to determine a configuration applicable to unseen datasets that helps describe short video clips in natural language and improved the CIDEr and BLEU-4 scores by 37.13 and 12.83 points compared to a vanilla Transformer network and achieve state-of-the-art results on the MSR-VTT and MSVD datasets. Also, FPE helps increase the CIDEr score by a relative factor of 8.6%.
Addressing Data Bias Problems for Chest X-ray Image Report Generation
Aug 06, 2019
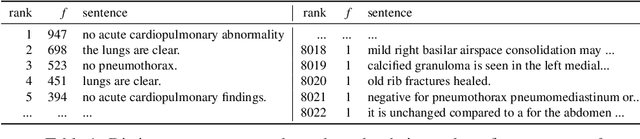
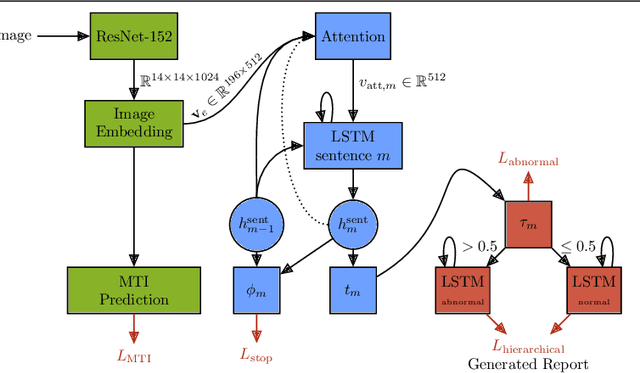
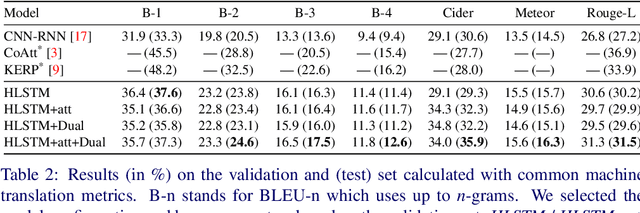
Automatic medical report generation from chest X-ray images is one possibility for assisting doctors to reduce their workload. However, the different patterns and data distribution of normal and abnormal cases can bias machine learning models. Previous attempts did not focus on isolating the generation of the abnormal and normal sentences in order to increase the variability of generated paragraphs. To address this, we propose to separate abnormal and normal sentence generation by using two different word LSTMs in a hierarchical LSTM model. We conduct an analysis on the distinctiveness of generated sentences compared to the BLEU score, which increases when less distinct reports are generated. We hope our findings will help to encourage the development of new metrics to better verify methods of automatic medical report generation.
Image Captioning with Clause-Focused Metrics in a Multi-Modal Setting for Marketing
May 06, 2019
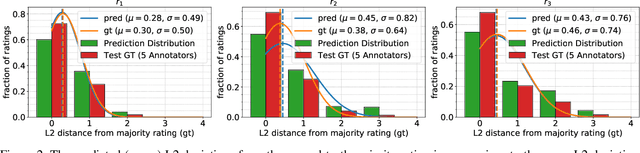
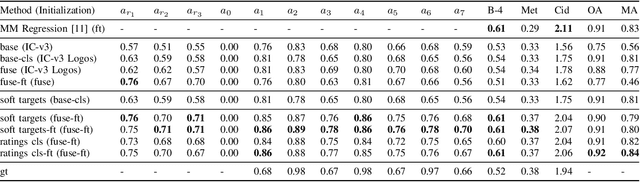

Automatically generating descriptive captions for images is a well-researched area in computer vision. However, existing evaluation approaches focus on measuring the similarity between two sentences disregarding fine-grained semantics of the captions. In our setting of images depicting persons interacting with branded products, the subject, predicate, object and the name of the branded product are important evaluation criteria of the generated captions. Generating image captions with these constraints is a new challenge, which we tackle in this work. By simultaneously predicting integer-valued ratings that describe attributes of the human-product interaction, we optimize a deep neural network architecture in a multi-task learning setting, which considerably improves the caption quality. Furthermore, we introduce a novel metric that allows us to assess whether the generated captions meet our requirements (i.e., subject, predicate, object, and product name) and describe a series of experiments on caption quality and how to address annotator disagreements for the image ratings with an approach called soft targets. We also show that our novel clause-focused metrics are also applicable to other image captioning datasets, such as the popular MSCOCO dataset.
Multimodal Image Captioning for Marketing Analysis
Feb 06, 2018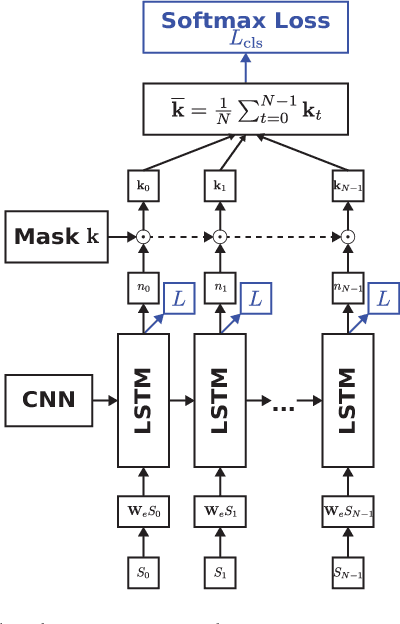
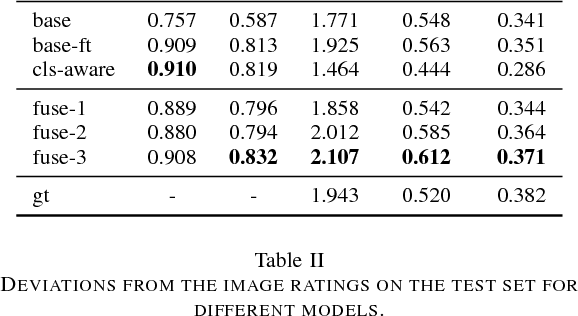
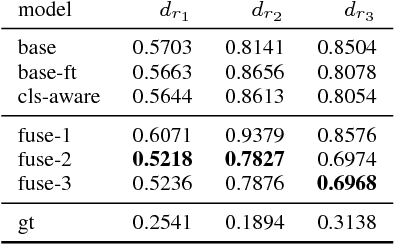
Automatically captioning images with natural language sentences is an important research topic. State of the art models are able to produce human-like sentences. These models typically describe the depicted scene as a whole and do not target specific objects of interest or emotional relationships between these objects in the image. However, marketing companies require to describe these important attributes of a given scene. In our case, objects of interest are consumer goods, which are usually identifiable by a product logo and are associated with certain brands. From a marketing point of view, it is desirable to also evaluate the emotional context of a trademarked product, i.e., whether it appears in a positive or a negative connotation. We address the problem of finding brands in images and deriving corresponding captions by introducing a modified image captioning network. We also add a third output modality, which simultaneously produces real-valued image ratings. Our network is trained using a classification-aware loss function in order to stimulate the generation of sentences with an emphasis on words identifying the brand of a product. We evaluate our model on a dataset of images depicting interactions between humans and branded products. The introduced network improves mean class accuracy by 24.5 percent. Thanks to adding the third output modality, it also considerably improves the quality of generated captions for images depicting branded products.