 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Represent Individual Differences for Choice Decision Making
Mar 27, 2025Human decision making can be challenging to predict because decisions are affected by a number of complex factors. Adding to this complexity, decision-making processes can differ considerably between individuals, and methods aimed at predicting human decisions need to take individual differences into account. Behavioral science offers methods by which to measure individual differences (e.g., questionnaires, behavioral models), but these are often narrowed down to low dimensions and not tailored to specific prediction tasks. This paper investigates the use of representation learning to measure individual differences from behavioral experiment data. Representation learning offers a flexible approach to create individual embeddings from data that are both structured (e.g., demographic information) and unstructured (e.g., free text), where the flexibility provides more options for individual difference measures for personalization, e.g., free text responses may allow for open-ended questions that are less privacy-sensitive. In the current paper we use representation learning to characterize individual differences in human performance on an economic decision-making task. We demonstrate that models using representation learning to capture individual differences consistently improve decision predictions over models without representation learning, and even outperform well-known theory-based behavioral models used in these environments. Our results propose that representation learning offers a useful and flexible tool to capture individual differences.
Understanding the Cognitive Complexity in Language Elicited by Product Images
Sep 25, 2024Product images (e.g., a phone) can be used to elicit a diverse set of consumer-reported features expressed through language, including surface-level perceptual attributes (e.g., "white") and more complex ones, like perceived utility (e.g., "battery"). The cognitive complexity of elicited language reveals the nature of cognitive processes and the context required to understand them; cognitive complexity also predicts consumers' subsequent choices. This work offers an approach for measuring and validating the cognitive complexity of human language elicited by product images, providing a tool for understanding the cognitive processes of human as well as virtual respondents simulated by Large Language Models (LLMs). We also introduce a large dataset that includes diverse descriptive labels for product images, including human-rated complexity. We demonstrate that human-rated cognitive complexity can be approximated using a set of natural language models that, combined, roughly capture the complexity construct. Moreover, this approach is minimally supervised and scalable, even in use cases with limited human assessment of complexity.
Accelerating Understanding of Scientific Experiments with End to End Symbolic Regression
Dec 07, 2021
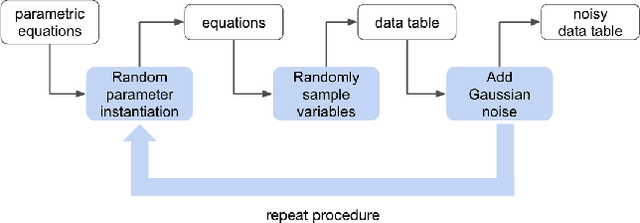
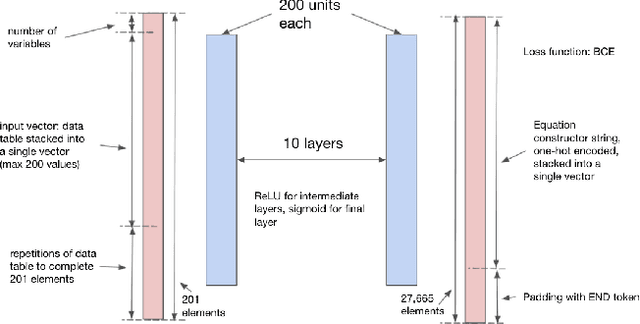
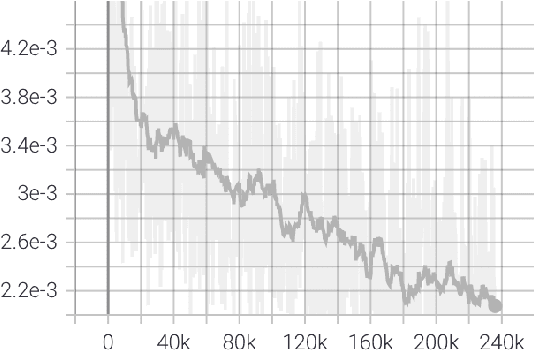
We consider the problem of learning free-form symbolic expressions from raw data, such as that produced by an experiment in any scientific domain. Accurate and interpretable models of scientific phenomena are the cornerstone of scientific research. Simple yet interpretable models, such as linear or logistic regression and decision trees often lack predictive accuracy. Alternatively, accurate blackbox models such as deep neural networks provide high predictive accuracy, but do not readily admit human understanding in a way that would enrich the scientific theory of the phenomenon. Many great breakthroughs in science revolve around the development of parsimonious equational models with high predictive accuracy, such as Newton's laws, universal gravitation, and Maxwell's equations. Previous work on automating the search of equational models from data combine domain-specific heuristics as well as computationally expensive techniques, such as genetic programming and Monte-Carlo search. We develop a deep neural network (MACSYMA) to address the symbolic regression problem as an end-to-end supervised learning problem. MACSYMA can generate symbolic expressions that describe a dataset. The computational complexity of the task is reduced to the feedforward computation of a neural network. We train our neural network on a synthetic dataset consisting of data tables of varying length and varying levels of noise, for which the neural network must learn to produce the correct symbolic expression token by token. Finally, we validate our technique by running on a public dataset from behavioral science.
Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021

Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.
A Visual Analytics Framework for Contrastive Network Analysis
Aug 17, 2020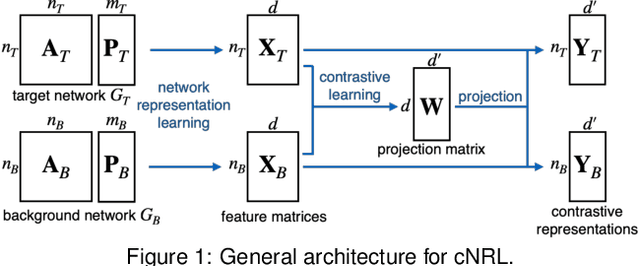
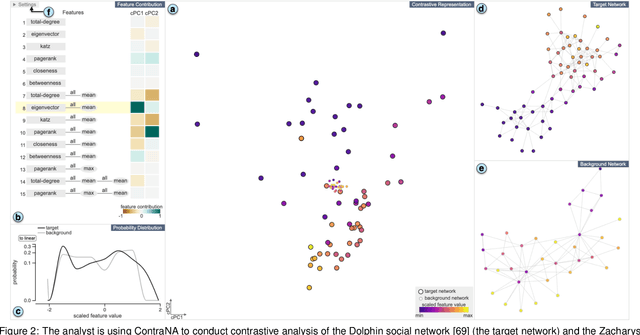
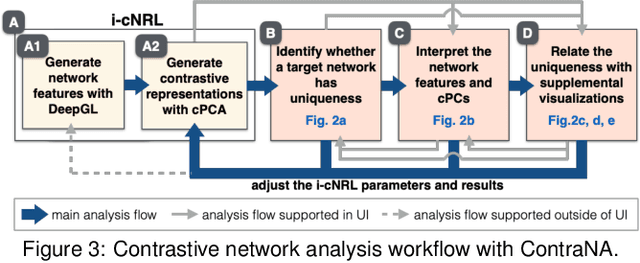
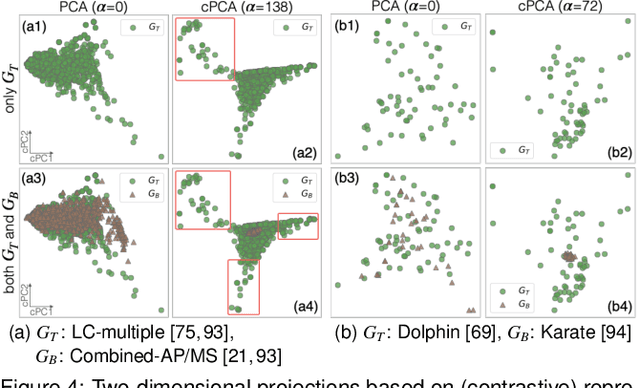
A common network analysis task is comparison of two networks to identify unique characteristics in one network with respect to the other. For example, when comparing protein interaction networks derived from normal and cancer tissues, one essential task is to discover protein-protein interactions unique to cancer tissues. However, this task is challenging when the networks contain complex structural (and semantic) relations. To address this problem, we design ContraNA, a visual analytics framework leveraging both the power of machine learning for uncovering unique characteristics in networks and also the effectiveness of visualization for understanding such uniqueness. The basis of ContraNA is cNRL, which integrates two machine learning schemes, network representation learning (NRL) and contrastive learning (CL), to generate a low-dimensional embedding that reveals the uniqueness of one network when compared to another. ContraNA provides an interactive visualization interface to help analyze the uniqueness by relating embedding results and network structures as well as explaining the learned features by cNRL. We demonstrate the usefulness of ContraNA with two case studies using real-world datasets. We also evaluate through a controlled user study with 12 participants on network comparison tasks. The results show that participants were able to both effectively identify unique characteristics from complex networks and interpret the results obtained from cNRL.
Thoracic Disease Identification and Localization using Distance Learning and Region Verification
Jun 07, 2020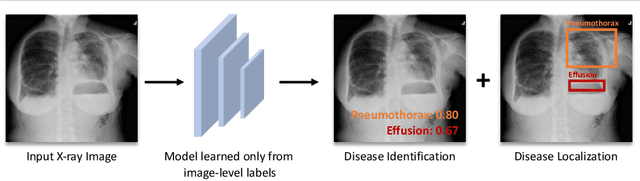
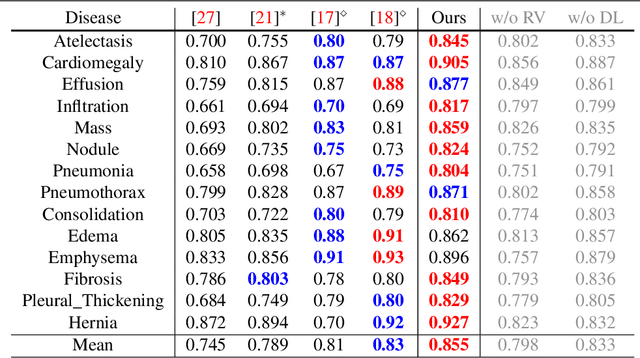
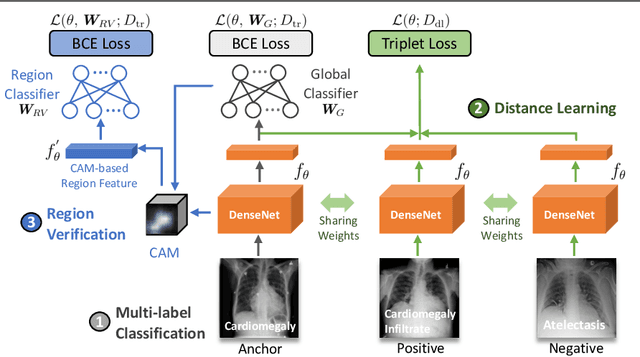
The identification and localization of diseases in medical images using deep learning models have recently attracted significant interest. Existing methods only consider training the networks with each image independently and most leverage an activation map for disease localization. In this paper, we propose an alternative approach that learns discriminative features among triplets of images and cyclically trains on region features to verify whether attentive regions contain information indicative of a disease. Concretely, we adapt a distance learning framework for multi-label disease classification to differentiate subtle disease features. Additionally, we feed back the features of the predicted class-specific regions to a separate classifier during training to better verify the localized diseases. Our model can achieve state-of-the-art classification performance on the challenging ChestX-ray14 dataset, and our ablation studies indicate that both distance learning and region verification contribute to overall classification performance. Moreover, the distance learning and region verification modules can capture essential information for better localization than baseline models without these modules.
Interpretable Contrastive Learning for Networks
May 25, 2020
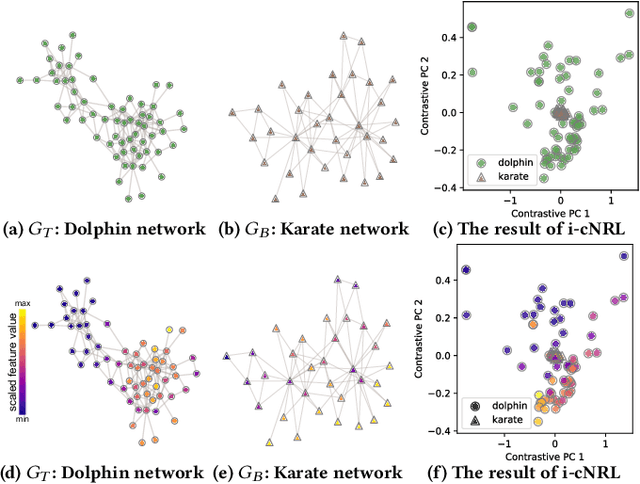


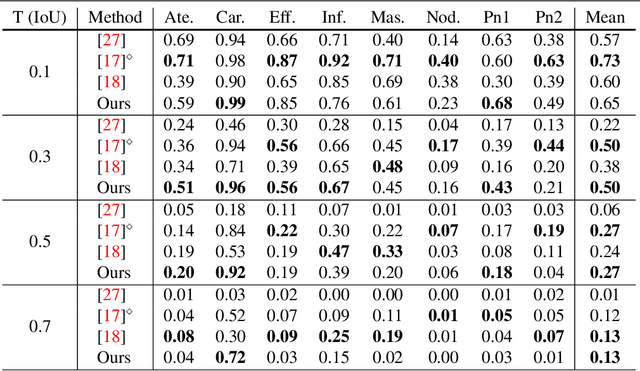
Contrastive learning (CL) is an emerging analysis approach that aims to discover unique patterns in one dataset relative to another. By applying this approach to network analysis, we can reveal unique characteristics in one network by contrasting with another. For example, with networks of protein interactions obtained from normal and cancer tissues, we can discover unique types of interactions in cancer tissues. However, existing CL methods cannot be directly applied to networks. To address this issue, we introduce a novel approach called contrastive network representation learning (cNRL). This approach embeds network nodes into a low-dimensional space that reveals the uniqueness of one network compared to another. Within this approach, we also design a method, named i-cNRL, that offers interpretability in the learned results, allowing for understanding which specific patterns are found in one network but not the other. We demonstrate the capability of i-cNRL with multiple network models and real-world datasets. Furthermore, we provide quantitative and qualitative comparisons across i-cNRL and other potential cNRL algorithm designs.
Addressing Data Bias Problems for Chest X-ray Image Report Generation
Aug 06, 2019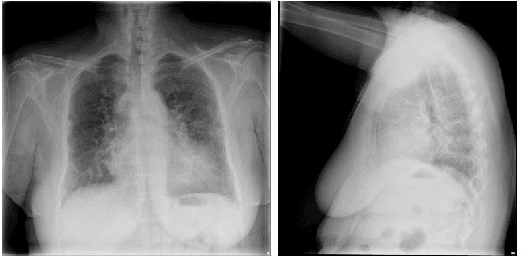
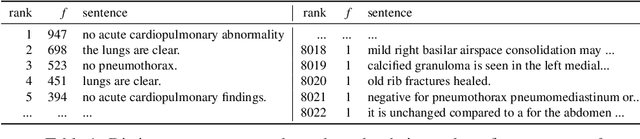
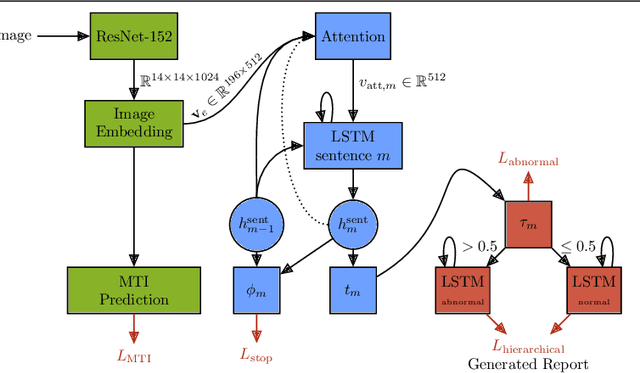
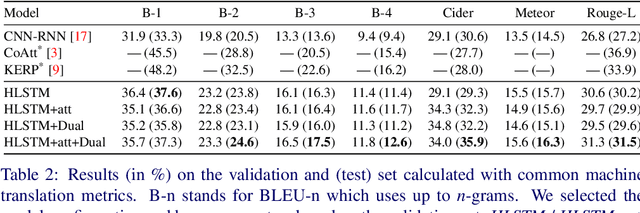
Automatic medical report generation from chest X-ray images is one possibility for assisting doctors to reduce their workload. However, the different patterns and data distribution of normal and abnormal cases can bias machine learning models. Previous attempts did not focus on isolating the generation of the abnormal and normal sentences in order to increase the variability of generated paragraphs. To address this, we propose to separate abnormal and normal sentence generation by using two different word LSTMs in a hierarchical LSTM model. We conduct an analysis on the distinctiveness of generated sentences compared to the BLEU score, which increases when less distinct reports are generated. We hope our findings will help to encourage the development of new metrics to better verify methods of automatic medical report generation.
Generating Multi-Sentence Abstractive Summaries of Interleaved Texts
Jun 05, 2019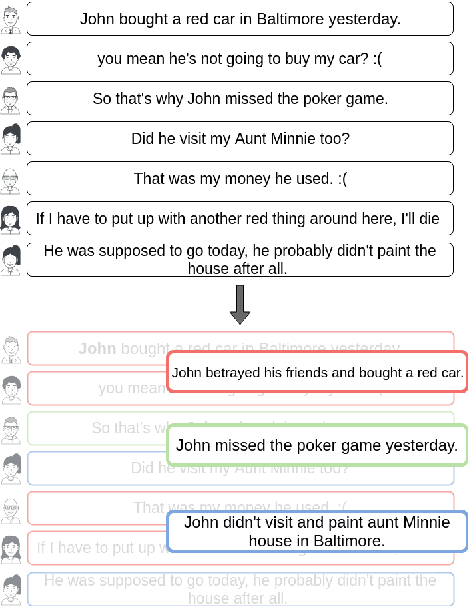

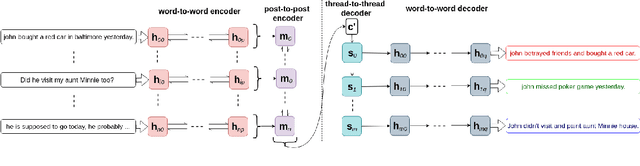
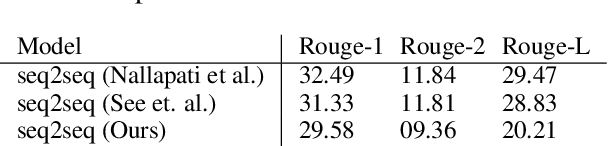
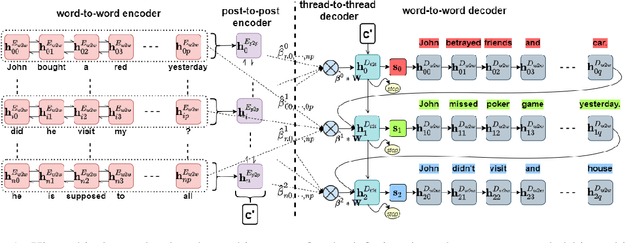
In multi-participant postings, as in online chat conversations, several conversations or topic threads may take place concurrently. This leads to difficulties for readers reviewing the postings in not only following discussions but also in quickly identifying their essence. A two-step process, disentanglement of interleaved posts followed by summarization of each thread, addresses the issue, but disentanglement errors are propagated to the summarization step, degrading the overall performance. To address this, we propose an end-to-end trainable encoder-decoder network for summarizing interleaved posts. The interleaved posts are encoded hierarchically, i.e., word-to-word (words in a post) followed by post-to-post (posts in a channel). The decoder also generates summaries hierarchically, thread-to-thread (generate thread representations) followed by word-to-word (i.e., generate summary words). Additionally, we propose a hierarchical attention mechanism for interleaved text. Overall, our end-to-end trainable hierarchical framework enhances performance over a sequence to sequence framework by 8% on a synthetic interleaved texts dataset.