 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Represent Individual Differences for Choice Decision Making
Mar 27, 2025Human decision making can be challenging to predict because decisions are affected by a number of complex factors. Adding to this complexity, decision-making processes can differ considerably between individuals, and methods aimed at predicting human decisions need to take individual differences into account. Behavioral science offers methods by which to measure individual differences (e.g., questionnaires, behavioral models), but these are often narrowed down to low dimensions and not tailored to specific prediction tasks. This paper investigates the use of representation learning to measure individual differences from behavioral experiment data. Representation learning offers a flexible approach to create individual embeddings from data that are both structured (e.g., demographic information) and unstructured (e.g., free text), where the flexibility provides more options for individual difference measures for personalization, e.g., free text responses may allow for open-ended questions that are less privacy-sensitive. In the current paper we use representation learning to characterize individual differences in human performance on an economic decision-making task. We demonstrate that models using representation learning to capture individual differences consistently improve decision predictions over models without representation learning, and even outperform well-known theory-based behavioral models used in these environments. Our results propose that representation learning offers a useful and flexible tool to capture individual differences.
Leveraging Language Models and Bandit Algorithms to Drive Adoption of Battery-Electric Vehicles
Oct 30, 2024

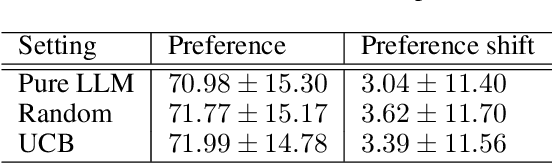

Behavior change interventions are important to coordinate societal action across a wide array of important applications, including the adoption of electrified vehicles to reduce emissions. Prior work has demonstrated that interventions for behavior must be personalized, and that the intervention that is most effective on average across a large group can result in a backlash effect that strengthens opposition among some subgroups. Thus, it is important to target interventions to different audiences, and to present them in a natural, conversational style. In this context, an important emerging application domain for large language models (LLMs) is conversational interventions for behavior change. In this work, we leverage prior work on understanding values motivating the adoption of battery electric vehicles. We leverage new advances in LLMs, combined with a contextual bandit, to develop conversational interventions that are personalized to the values of each study participant. We use a contextual bandit algorithm to learn to target values based on the demographics of each participant. To train our bandit algorithm in an offline manner, we leverage LLMs to play the role of study participants. We benchmark the persuasive effectiveness of our bandit-enhanced LLM against an unaided LLM generating conversational interventions without demographic-targeted values.
Using LLMs to Model the Beliefs and Preferences of Targeted Populations
Mar 29, 2024We consider the problem of aligning a large language model (LLM) to model the preferences of a human population. Modeling the beliefs, preferences, and behaviors of a specific population can be useful for a variety of different applications, such as conducting simulated focus groups for new products, conducting virtual surveys, and testing behavioral interventions, especially for interventions that are expensive, impractical, or unethical. Existing work has had mixed success using LLMs to accurately model human behavior in different contexts. We benchmark and evaluate two well-known fine-tuning approaches and evaluate the resulting populations on their ability to match the preferences of real human respondents on a survey of preferences for battery electric vehicles (BEVs). We evaluate our models against their ability to match population-wide statistics as well as their ability to match individual responses, and we investigate the role of temperature in controlling the trade-offs between these two. Additionally, we propose and evaluate a novel loss term to improve model performance on responses that require a numeric response.
Accelerating Understanding of Scientific Experiments with End to End Symbolic Regression
Dec 07, 2021
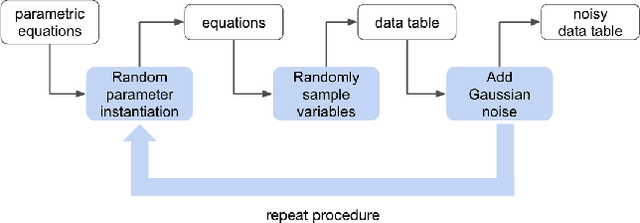
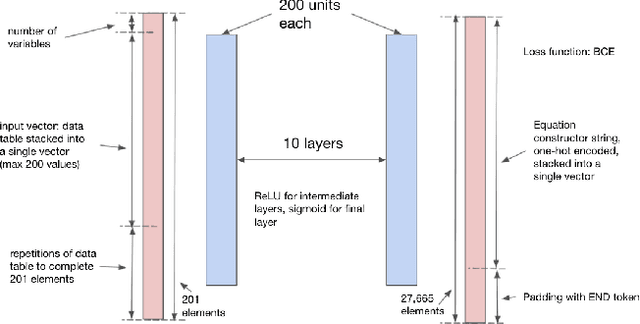
We consider the problem of learning free-form symbolic expressions from raw data, such as that produced by an experiment in any scientific domain. Accurate and interpretable models of scientific phenomena are the cornerstone of scientific research. Simple yet interpretable models, such as linear or logistic regression and decision trees often lack predictive accuracy. Alternatively, accurate blackbox models such as deep neural networks provide high predictive accuracy, but do not readily admit human understanding in a way that would enrich the scientific theory of the phenomenon. Many great breakthroughs in science revolve around the development of parsimonious equational models with high predictive accuracy, such as Newton's laws, universal gravitation, and Maxwell's equations. Previous work on automating the search of equational models from data combine domain-specific heuristics as well as computationally expensive techniques, such as genetic programming and Monte-Carlo search. We develop a deep neural network (MACSYMA) to address the symbolic regression problem as an end-to-end supervised learning problem. MACSYMA can generate symbolic expressions that describe a dataset. The computational complexity of the task is reduced to the feedforward computation of a neural network. We train our neural network on a synthetic dataset consisting of data tables of varying length and varying levels of noise, for which the neural network must learn to produce the correct symbolic expression token by token. Finally, we validate our technique by running on a public dataset from behavioral science.
Machine learning reveals how personalized climate communication can both succeed and backfire
Sep 10, 2021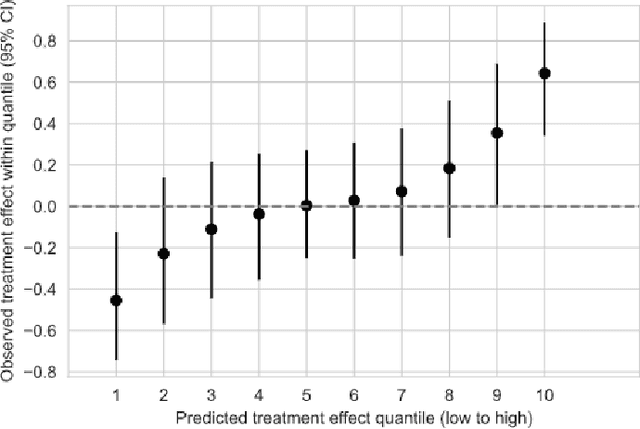
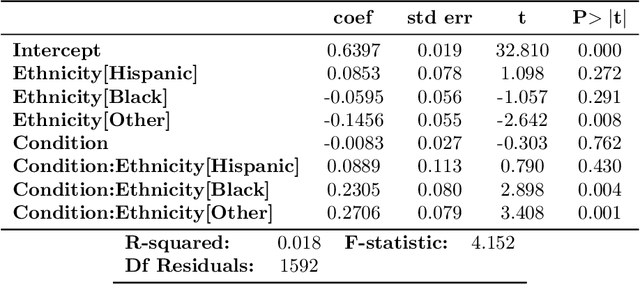
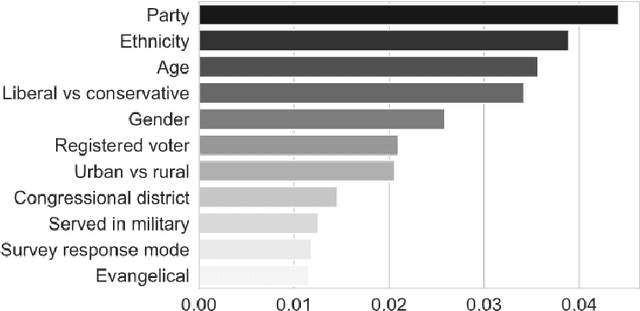
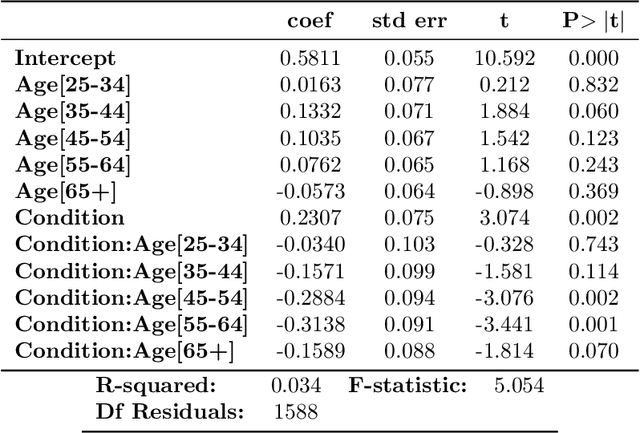
Different advertising messages work for different people. Machine learning can be an effective way to personalise climate communications. In this paper we use machine learning to reanalyse findings from a recent study, showing that online advertisements increased some people's belief in climate change while resulting in decreased belief in others. In particular, we show that the effect of the advertisements could change depending on people's age and ethnicity.