 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Represent Individual Differences for Choice Decision Making
Mar 27, 2025Human decision making can be challenging to predict because decisions are affected by a number of complex factors. Adding to this complexity, decision-making processes can differ considerably between individuals, and methods aimed at predicting human decisions need to take individual differences into account. Behavioral science offers methods by which to measure individual differences (e.g., questionnaires, behavioral models), but these are often narrowed down to low dimensions and not tailored to specific prediction tasks. This paper investigates the use of representation learning to measure individual differences from behavioral experiment data. Representation learning offers a flexible approach to create individual embeddings from data that are both structured (e.g., demographic information) and unstructured (e.g., free text), where the flexibility provides more options for individual difference measures for personalization, e.g., free text responses may allow for open-ended questions that are less privacy-sensitive. In the current paper we use representation learning to characterize individual differences in human performance on an economic decision-making task. We demonstrate that models using representation learning to capture individual differences consistently improve decision predictions over models without representation learning, and even outperform well-known theory-based behavioral models used in these environments. Our results propose that representation learning offers a useful and flexible tool to capture individual differences.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020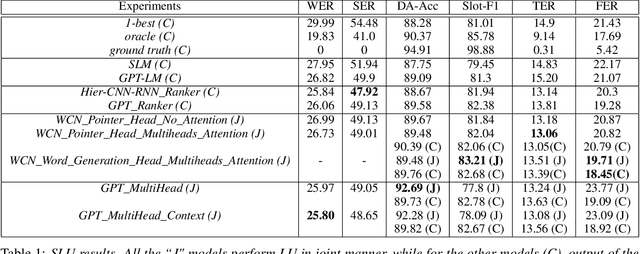
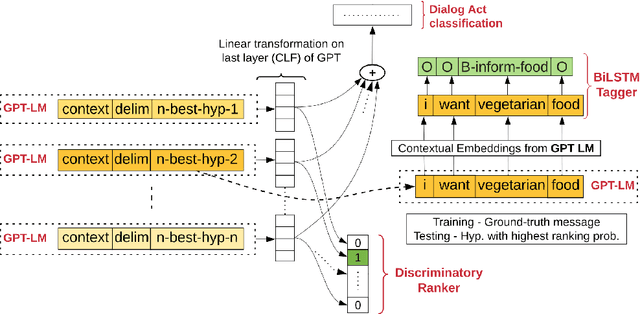
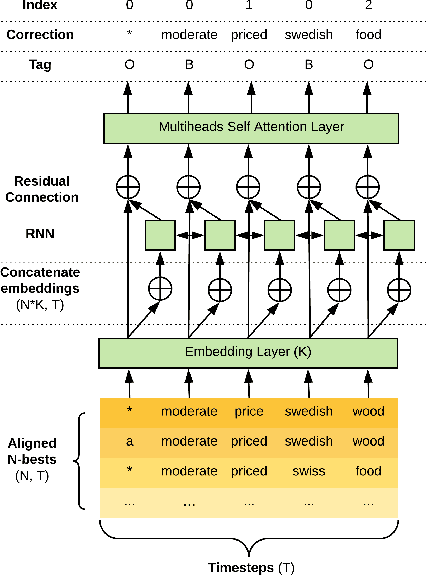
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
OCC: A Smart Reply System for Efficient In-App Communications
Jul 18, 2019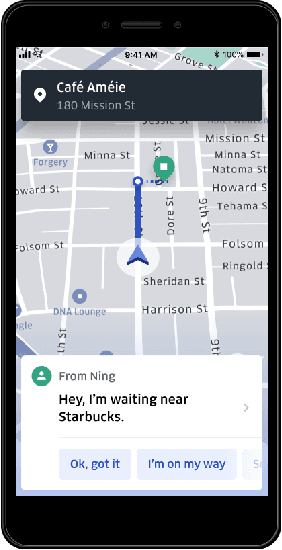

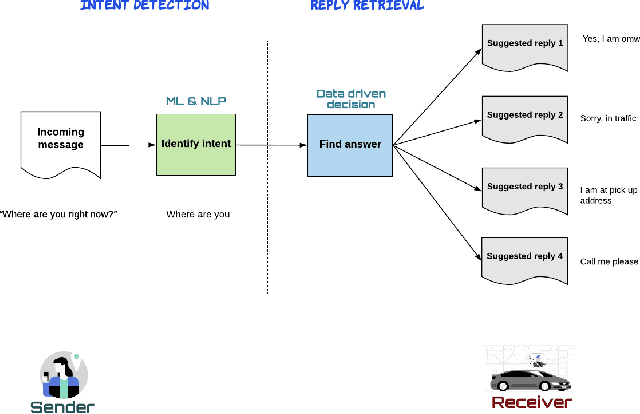

Smart reply systems have been developed for various messaging platforms. In this paper, we introduce Uber's smart reply system: one-click-chat (OCC), which is a key enhanced feature on top of the Uber in-app chat system. It enables driver-partners to quickly respond to rider messages using smart replies. The smart replies are dynamically selected according to conversation content using machine learning algorithms. Our system consists of two major components: intent detection and reply retrieval, which are very different from standard smart reply systems where the task is to directly predict a reply. It is designed specifically for mobile applications with short and non-canonical messages. Reply retrieval utilizes pairings between intent and reply based on their popularity in chat messages as derived from historical data. For intent detection, a set of embedding and classification techniques are experimented with, and we choose to deploy a solution using unsupervised distributed embedding and nearest-neighbor classifier. It has the advantage of only requiring a small amount of labeled training data, simplicity in developing and deploying to production, and fast inference during serving and hence highly scalable. At the same time, it performs comparably with deep learning architectures such as word-level convolutional neural network. Overall, the system achieves a high accuracy of 76% on intent detection. Currently, the system is deployed in production for English-speaking countries and 71% of in-app communications between riders and driver-partners adopted the smart replies to speedup the communication process.
* link to demo: https://www.youtube.com/watch?v=nOffUT7rS0A&t=32s