 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020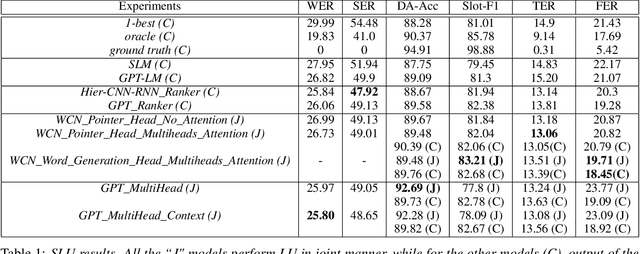
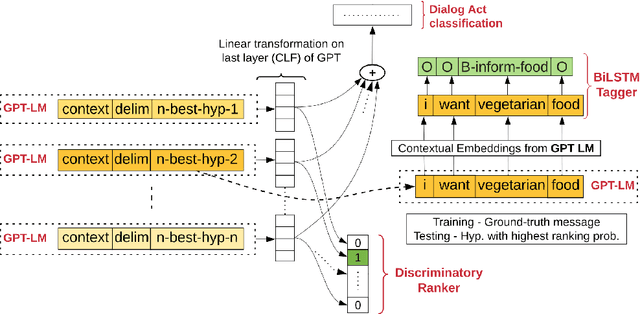
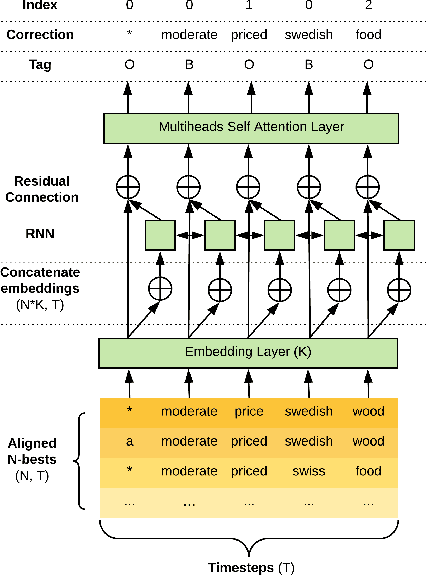
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

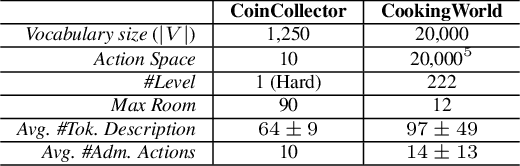
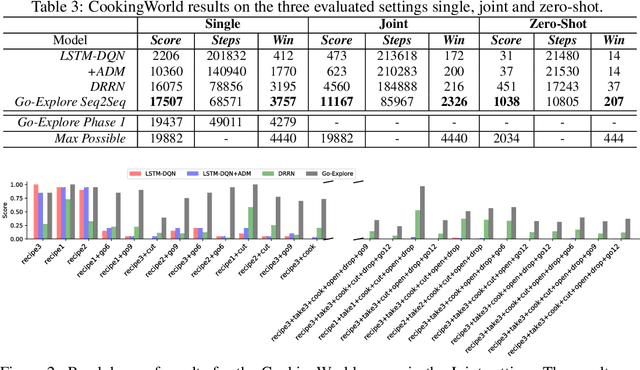
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Flexibly-Structured Model for Task-Oriented Dialogues
Aug 06, 2019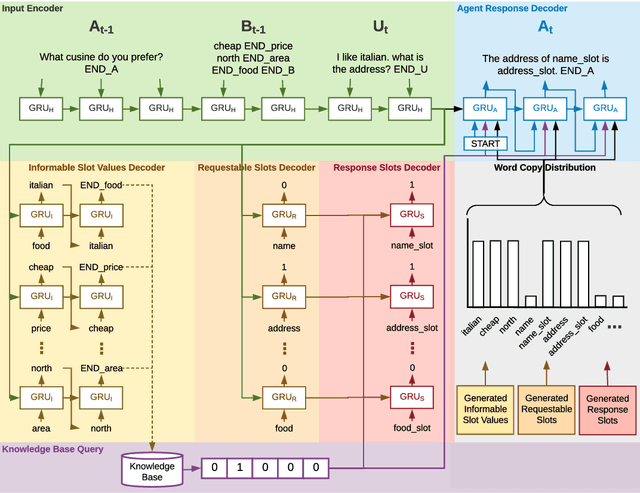
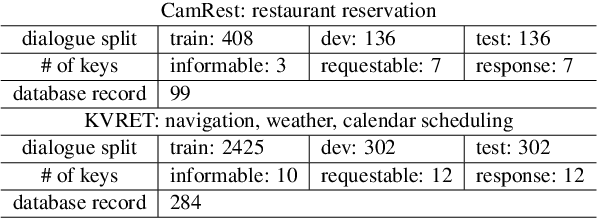

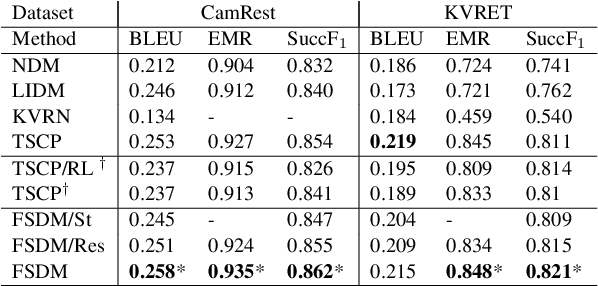
This paper proposes a novel end-to-end architecture for task-oriented dialogue systems. It is based on a simple and practical yet very effective sequence-to-sequence approach, where language understanding and state tracking tasks are modeled jointly with a structured copy-augmented sequential decoder and a multi-label decoder for each slot. The policy engine and language generation tasks are modeled jointly following that. The copy-augmented sequential decoder deals with new or unknown values in the conversation, while the multi-label decoder combined with the sequential decoder ensures the explicit assignment of values to slots. On the generation part, slot binary classifiers are used to improve performance. This architecture is scalable to real-world scenarios and is shown through an empirical evaluation to achieve state-of-the-art performance on both the Cambridge Restaurant dataset and the Stanford in-car assistant dataset\footnote{The code is available at \url{https://github.com/uber-research/FSDM}}
OCC: A Smart Reply System for Efficient In-App Communications
Jul 18, 2019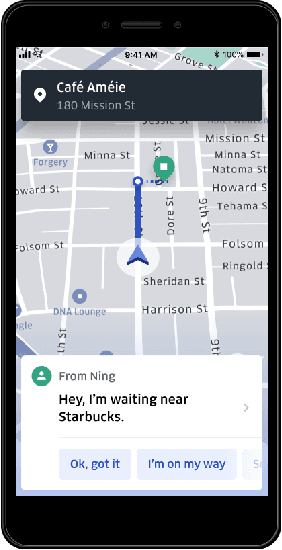

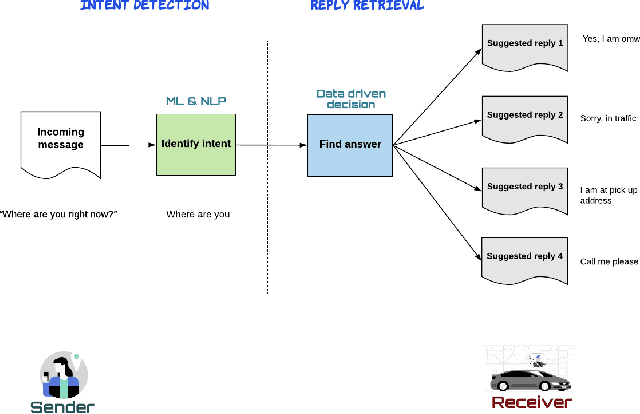

Smart reply systems have been developed for various messaging platforms. In this paper, we introduce Uber's smart reply system: one-click-chat (OCC), which is a key enhanced feature on top of the Uber in-app chat system. It enables driver-partners to quickly respond to rider messages using smart replies. The smart replies are dynamically selected according to conversation content using machine learning algorithms. Our system consists of two major components: intent detection and reply retrieval, which are very different from standard smart reply systems where the task is to directly predict a reply. It is designed specifically for mobile applications with short and non-canonical messages. Reply retrieval utilizes pairings between intent and reply based on their popularity in chat messages as derived from historical data. For intent detection, a set of embedding and classification techniques are experimented with, and we choose to deploy a solution using unsupervised distributed embedding and nearest-neighbor classifier. It has the advantage of only requiring a small amount of labeled training data, simplicity in developing and deploying to production, and fast inference during serving and hence highly scalable. At the same time, it performs comparably with deep learning architectures such as word-level convolutional neural network. Overall, the system achieves a high accuracy of 76% on intent detection. Currently, the system is deployed in production for English-speaking countries and 71% of in-app communications between riders and driver-partners adopted the smart replies to speedup the communication process.
* link to demo: https://www.youtube.com/watch?v=nOffUT7rS0A&t=32s
COTA: Improving the Speed and Accuracy of Customer Support through Ranking and Deep Networks
Jul 03, 2018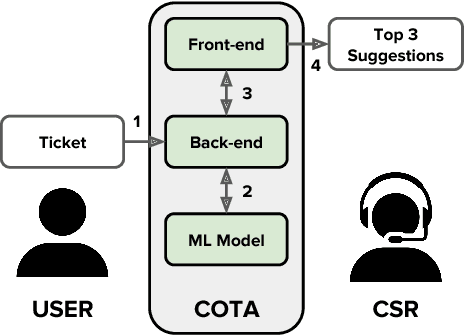
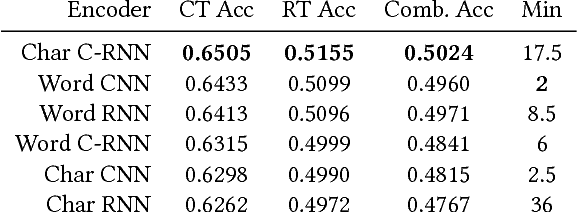
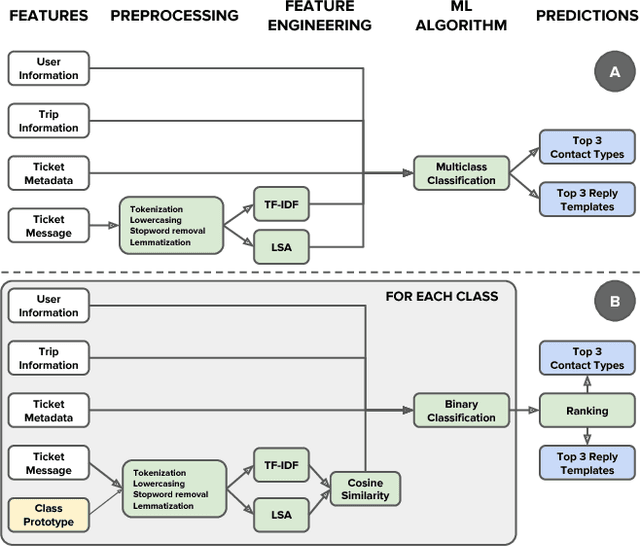

For a company looking to provide delightful user experiences, it is of paramount importance to take care of any customer issues. This paper proposes COTA, a system to improve speed and reliability of customer support for end users through automated ticket classification and answers selection for support representatives. Two machine learning and natural language processing techniques are demonstrated: one relying on feature engineering (COTA v1) and the other exploiting raw signals through deep learning architectures (COTA v2). COTA v1 employs a new approach that converts the multi-classification task into a ranking problem, demonstrating significantly better performance in the case of thousands of classes. For COTA v2, we propose an Encoder-Combiner-Decoder, a novel deep learning architecture that allows for heterogeneous input and output feature types and injection of prior knowledge through network architecture choices. This paper compares these models and their variants on the task of ticket classification and answer selection, showing model COTA v2 outperforms COTA v1, and analyzes their inner workings and shortcomings. Finally, an A/B test is conducted in a production setting validating the real-world impact of COTA in reducing issue resolution time by 10 percent without reducing customer satisfaction.
Prostate Cancer Diagnosis using Deep Learning with 3D Multiparametric MRI
Mar 12, 2017A novel deep learning architecture (XmasNet) based on convolutional neural networks was developed for the classification of prostate cancer lesions, using the 3D multiparametric MRI data provided by the PROSTATEx challenge. End-to-end training was performed for XmasNet, with data augmentation done through 3D rotation and slicing, in order to incorporate the 3D information of the lesion. XmasNet outperformed traditional machine learning models based on engineered features, for both train and test data. For the test data, XmasNet outperformed 69 methods from 33 participating groups and achieved the second highest AUC (0.84) in the PROSTATEx challenge. This study shows the great potential of deep learning for cancer imaging.