 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Logs to Language: Learning Optimal Verbalization for LLM-Based Recommendation in Production
Feb 24, 2026Large language models (LLMs) are promising backbones for generative recommender systems, yet a key challenge remains underexplored: verbalization, i.e., converting structured user interaction logs into effective natural language inputs. Existing methods rely on rigid templates that simply concatenate fields, yielding suboptimal representations for recommendation. We propose a data-centric framework that learns verbalization for LLM-based recommendation. Using reinforcement learning, a verbalization agent transforms raw interaction histories into optimized textual contexts, with recommendation accuracy as the training signal. This agent learns to filter noise, incorporate relevant metadata, and reorganize information to improve downstream predictions. Experiments on a large-scale industrial streaming dataset show that learned verbalization delivers up to 93% relative improvement in discovery item recommendation accuracy over template-based baselines. Further analysis reveals emergent strategies such as user interest summarization, noise removal, and syntax normalization, offering insights into effective context construction for LLM-based recommender systems.
Netflix Artwork Personalization via LLM Post-training
Jan 06, 2026Large language models (LLMs) have demonstrated success in various applications of user recommendation and personalization across e-commerce and entertainment. On many entertainment platforms such as Netflix, users typically interact with a wide range of titles, each represented by an artwork. Since users have diverse preferences, an artwork that appeals to one type of user may not resonate with another with different preferences. Given this user heterogeneity, our work explores the novel problem of personalized artwork recommendations according to diverse user preferences. Similar to the multi-dimensional nature of users' tastes, titles contain different themes and tones that may appeal to different viewers. For example, the same title might feature both heartfelt family drama and intense action scenes. Users who prefer romantic content may like the artwork emphasizing emotional warmth between the characters, while those who prefer action thrillers may find high-intensity action scenes more intriguing. Rather than a one-size-fits-all approach, we conduct post-training of pre-trained LLMs to make personalized artwork recommendations, selecting the most preferred visual representation of a title for each user and thereby improving user satisfaction and engagement. Our experimental results with Llama 3.1 8B models (trained on a dataset of 110K data points and evaluated on 5K held-out user-title pairs) show that the post-trained LLMs achieve 3-5\% improvements over the Netflix production model, suggesting a promising direction for granular personalized recommendations using LLMs.
Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems
Feb 19, 2025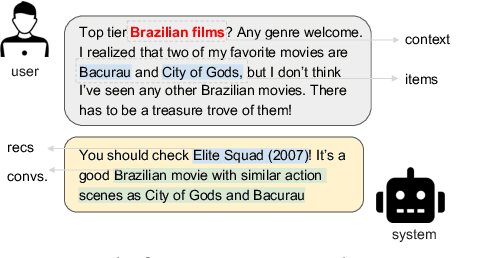
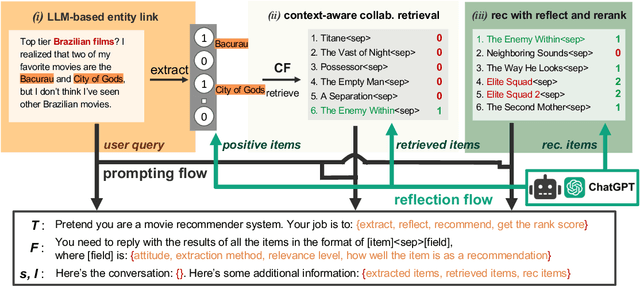

Conversational recommender systems (CRS) aim to provide personalized recommendations via interactive dialogues with users. While large language models (LLMs) enhance CRS with their superior understanding of context-aware user preferences, they typically struggle to leverage behavioral data, which have proven to be important for classical collaborative filtering (CF)-based approaches. For this reason, we propose CRAG, Collaborative Retrieval Augmented Generation for LLM-based CRS. To the best of our knowledge, CRAG is the first approach that combines state-of-the-art LLMs with CF for conversational recommendations. Our experiments on two publicly available movie conversational recommendation datasets, i.e., a refined Reddit dataset (which we name Reddit-v2) as well as the Redial dataset, demonstrate the superior item coverage and recommendation performance of CRAG, compared to several CRS baselines. Moreover, we observe that the improvements are mainly due to better recommendation accuracy on recently released movies. The code and data are available at https://github.com/yaochenzhu/CRAG.
Large Language Models as Zero-Shot Conversational Recommenders
Aug 19, 2023



In this paper, we present empirical studies on conversational recommendation tasks using representative large language models in a zero-shot setting with three primary contributions. (1) Data: To gain insights into model behavior in "in-the-wild" conversational recommendation scenarios, we construct a new dataset of recommendation-related conversations by scraping a popular discussion website. This is the largest public real-world conversational recommendation dataset to date. (2) Evaluation: On the new dataset and two existing conversational recommendation datasets, we observe that even without fine-tuning, large language models can outperform existing fine-tuned conversational recommendation models. (3) Analysis: We propose various probing tasks to investigate the mechanisms behind the remarkable performance of large language models in conversational recommendation. We analyze both the large language models' behaviors and the characteristics of the datasets, providing a holistic understanding of the models' effectiveness, limitations and suggesting directions for the design of future conversational recommenders
Prostate Cancer Diagnosis using Deep Learning with 3D Multiparametric MRI
Mar 12, 2017A novel deep learning architecture (XmasNet) based on convolutional neural networks was developed for the classification of prostate cancer lesions, using the 3D multiparametric MRI data provided by the PROSTATEx challenge. End-to-end training was performed for XmasNet, with data augmentation done through 3D rotation and slicing, in order to incorporate the 3D information of the lesion. XmasNet outperformed traditional machine learning models based on engineered features, for both train and test data. For the test data, XmasNet outperformed 69 methods from 33 participating groups and achieved the second highest AUC (0.84) in the PROSTATEx challenge. This study shows the great potential of deep learning for cancer imaging.