 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
Evaluation on Entity Matching in Recommender Systems
Jan 23, 2026Entity matching is a crucial component in various recommender systems, including conversational recommender systems (CRS) and knowledge-based recommender systems. However, the lack of rigorous evaluation frameworks for cross-dataset entity matching impedes progress in areas such as LLM-driven conversational recommendations and knowledge-grounded dataset construction. In this paper, we introduce Reddit-Amazon-EM, a novel dataset comprising naturally occurring items from Reddit and the Amazon '23 dataset. Through careful manual annotation, we identify corresponding movies across Reddit-Movies and Amazon'23, two existing recommender system datasets with inherently overlapping catalogs. Leveraging Reddit-Amazon-EM, we conduct a comprehensive evaluation of state-of-the-art entity matching methods, including rule-based, graph-based, lexical-based, embedding-based, and LLM-based approaches. For reproducible research, we release our manually annotated entity matching gold set and provide the mapping between the two datasets using the best-performing method from our experiments. This serves as a valuable resource for advancing future work on entity matching in recommender systems.
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
In-context Ranking Preference Optimization
Apr 21, 2025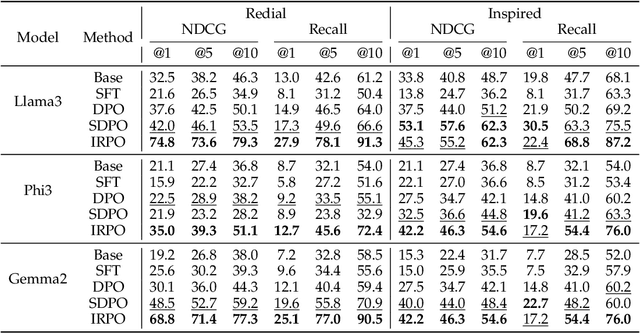
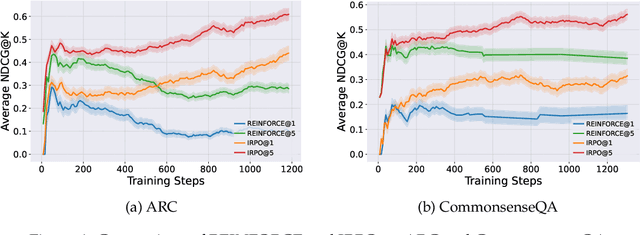
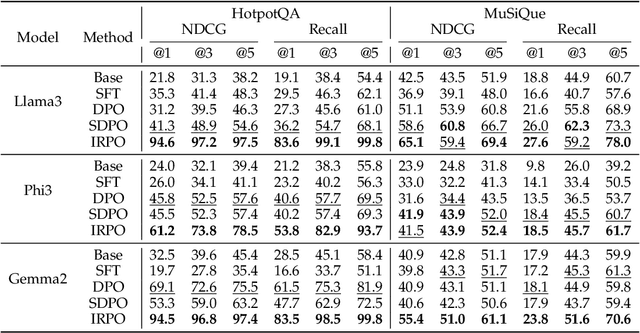
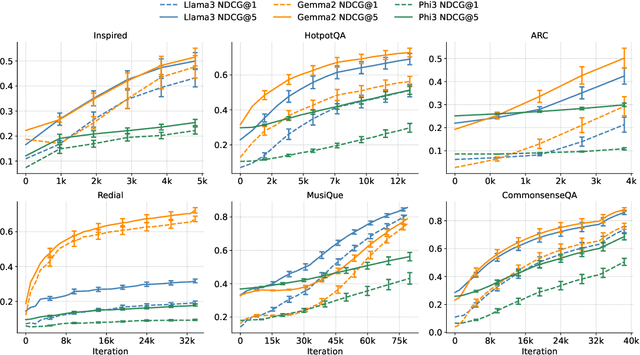
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.
From Reviews to Dialogues: Active Synthesis for Zero-Shot LLM-based Conversational Recommender System
Apr 21, 2025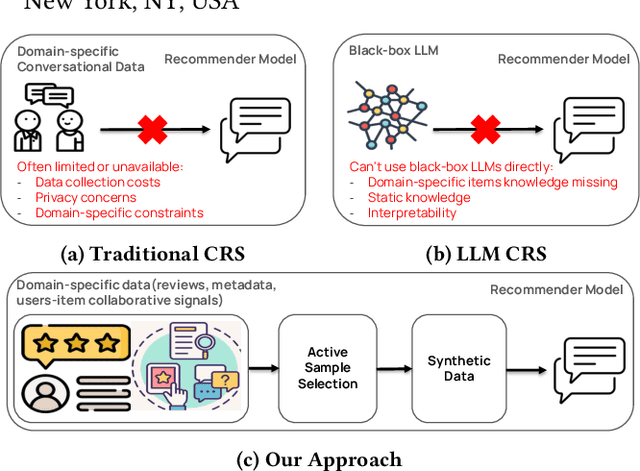
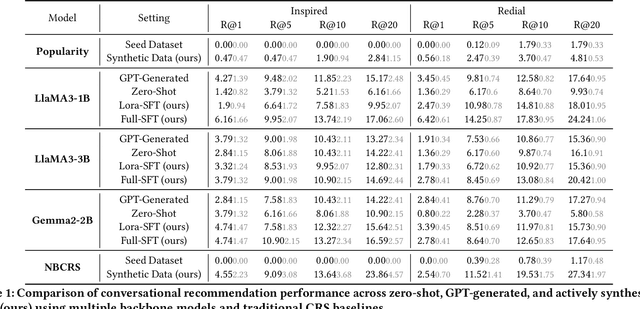
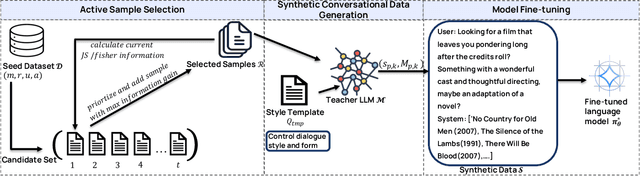
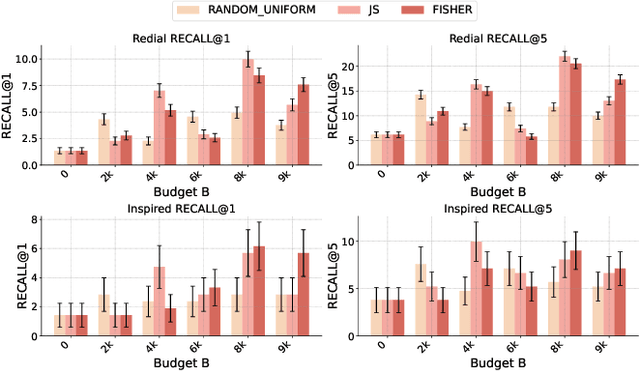
Conversational recommender systems (CRS) typically require extensive domain-specific conversational datasets, yet high costs, privacy concerns, and data-collection challenges severely limit their availability. Although Large Language Models (LLMs) demonstrate strong zero-shot recommendation capabilities, practical applications often favor smaller, internally managed recommender models due to scalability, interpretability, and data privacy constraints, especially in sensitive or rapidly evolving domains. However, training these smaller models effectively still demands substantial domain-specific conversational data, which remains challenging to obtain. To address these limitations, we propose an active data augmentation framework that synthesizes conversational training data by leveraging black-box LLMs guided by active learning techniques. Specifically, our method utilizes publicly available non-conversational domain data, including item metadata, user reviews, and collaborative signals, as seed inputs. By employing active learning strategies to select the most informative seed samples, our approach efficiently guides LLMs to generate synthetic, semantically coherent conversational interactions tailored explicitly to the target domain. Extensive experiments validate that conversational data generated by our proposed framework significantly improves the performance of LLM-based CRS models, effectively addressing the challenges of building CRS in no- or low-resource scenarios.
Improving In-Context Learning with Reasoning Distillation
Apr 14, 2025



Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model's understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
Apr 09, 2025Personalized preference alignment for large language models (LLMs), the process of tailoring LLMs to individual users' preferences, is an emerging research direction spanning the area of NLP and personalization. In this survey, we present an analysis of works on personalized alignment and modeling for LLMs. We introduce a taxonomy of preference alignment techniques, including training time, inference time, and additionally, user-modeling based methods. We provide analysis and discussion on the strengths and limitations of each group of techniques and then cover evaluation, benchmarks, as well as open problems in the field.
Latent Factor Models Meets Instructions:Goal-conditioned Latent Factor Discovery without Task Supervision
Feb 21, 2025Instruction-following LLMs have recently allowed systems to discover hidden concepts from a collection of unstructured documents based on a natural language description of the purpose of the discovery (i.e., goal). Still, the quality of the discovered concepts remains mixed, as it depends heavily on LLM's reasoning ability and drops when the data is noisy or beyond LLM's knowledge. We present Instruct-LF, a goal-oriented latent factor discovery system that integrates LLM's instruction-following ability with statistical models to handle large, noisy datasets where LLM reasoning alone falls short. Instruct-LF uses LLMs to propose fine-grained, goal-related properties from documents, estimates their presence across the dataset, and applies gradient-based optimization to uncover hidden factors, where each factor is represented by a cluster of co-occurring properties. We evaluate latent factors produced by Instruct-LF on movie recommendation, text-world navigation, and legal document categorization tasks. These interpretable representations improve downstream task performance by 5-52% than the best baselines and were preferred 1.8 times as often as the best alternative, on average, in human evaluation.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
GUI Agents: A Survey
Dec 18, 2024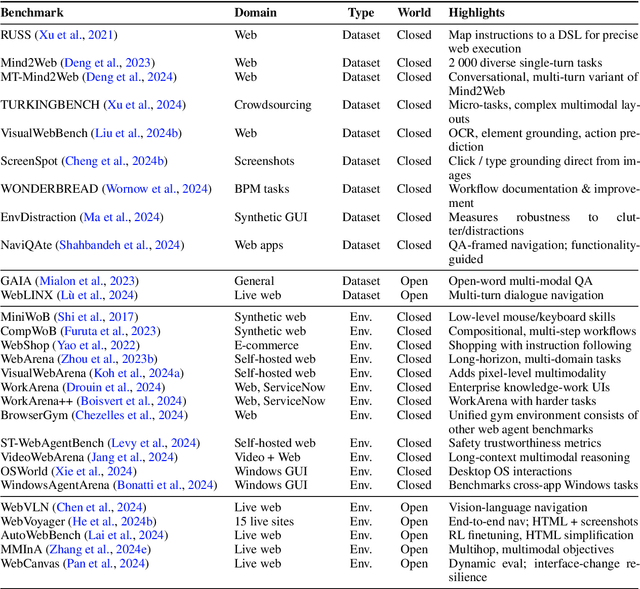
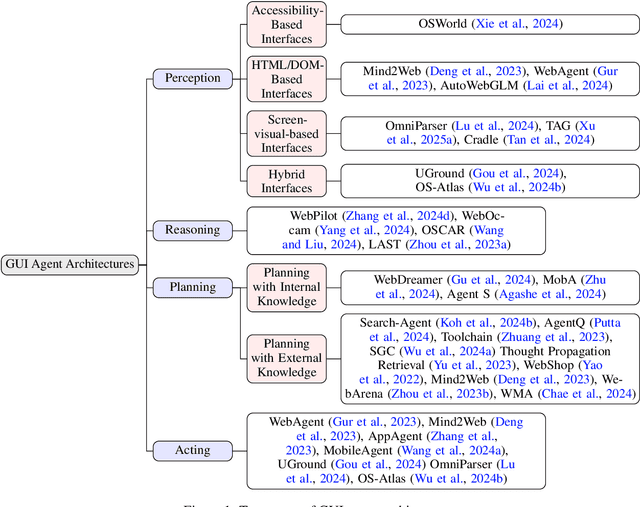

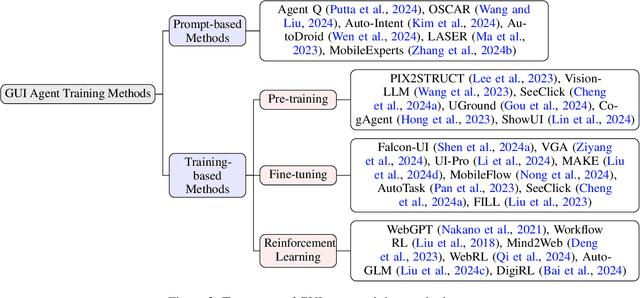
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.