 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Personalized Bangla Book Recommendation: A Large-Scale Multi-Entity Book Graph Dataset
Feb 12, 2026Personalized book recommendation in Bangla literature has been constrained by the lack of structured, large-scale, and publicly available datasets. This work introduces RokomariBG, a large-scale, multi-entity heterogeneous book graph dataset designed to support research on personalized recommendation in a low-resource language setting. The dataset comprises 127,302 books, 63,723 users, 16,601 authors, 1,515 categories, 2,757 publishers, and 209,602 reviews, connected through eight relation types and organized as a comprehensive knowledge graph. To demonstrate the utility of the dataset, we provide a systematic benchmarking study on the Top-N recommendation task, evaluating a diverse set of representative recommendation models, including classical collaborative filtering methods, matrix factorization models, content-based approaches, graph neural networks, a hybrid matrix factorization model with side information, and a neural two-tower retrieval architecture. The benchmarking results highlight the importance of leveraging multi-relational structure and textual side information, with neural retrieval models achieving the strongest performance (NDCG@10 = 0.204). Overall, this work establishes a foundational benchmark and a publicly available resource for Bangla book recommendation research, enabling reproducible evaluation and future studies on recommendation in low-resource cultural domains. The dataset and code are publicly available at https://github.com/backlashblitz/Bangla-Book-Recommendation-Dataset
Improving In-Context Learning with Reasoning Distillation
Apr 14, 2025



Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model's understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
Bridging Conversational and Collaborative Signals for Conversational Recommendation
Dec 09, 2024
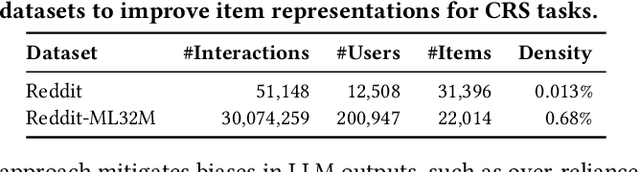
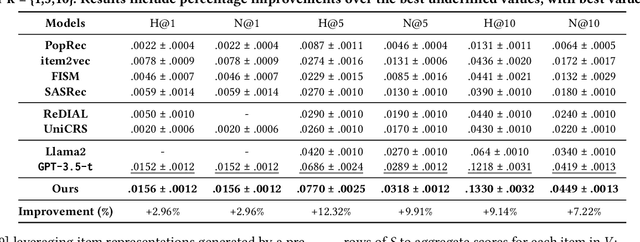
Conversational recommendation systems (CRS) leverage contextual information from conversations to generate recommendations but often struggle due to a lack of collaborative filtering (CF) signals, which capture user-item interaction patterns essential for accurate recommendations. We introduce Reddit-ML32M, a dataset that links reddit conversations with interactions on MovieLens 32M, to enrich item representations by leveraging collaborative knowledge and addressing interaction sparsity in conversational datasets. We propose an LLM-based framework that uses Reddit-ML32M to align LLM-generated recommendations with CF embeddings, refining rankings for better performance. We evaluate our framework against three sets of baselines: CF-based recommenders using only interactions from CRS tasks, traditional CRS models, and LLM-based methods relying on conversational context without item representations. Our approach achieves consistent improvements, including a 12.32% increase in Hit Rate and a 9.9% improvement in NDCG, outperforming the best-performing baseline that relies on conversational context but lacks collaborative item representations.
Mitigating Hallucination in Fictional Character Role-Play
Jun 25, 2024
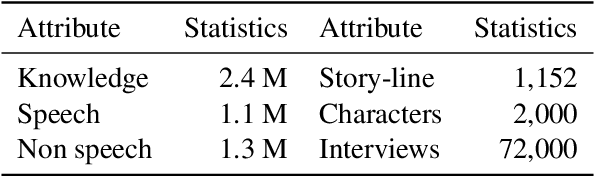
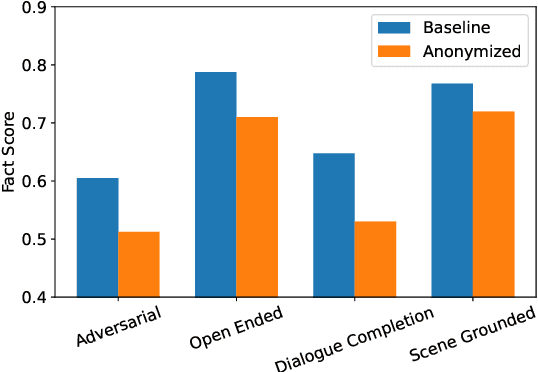
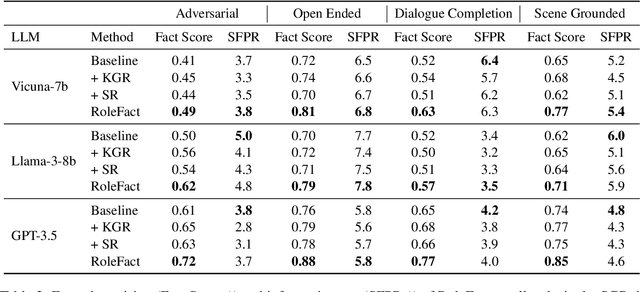
Role-playing has wide-ranging applications in customer support, embodied agents, computational social science, etc. The influence of parametric world knowledge of large language models (LLMs) often causes role-playing characters to act out of character and hallucinate about things outside the scope of their knowledge. In this work, we focus on the evaluation and mitigation of hallucination in fictional character role-play. We introduce a dataset with more than 2,000 characters and 72,000 interviews, including 18,000 adversarial questions. We propose RoleFact, a role-playing method that mitigates hallucination by modulating the influence of parametric knowledge using a pre-calibrated confidence threshold. Experiments show that the proposed method improves the factual precision of generated responses by 18% for adversarial questions with a 44% reduction in temporal hallucination for time-sensitive interviews. The code and the dataset will be available at https://github.com/NafisSadeq/rolefact.git.
Unsupervised Improvement of Factual Knowledge in Language Models
Apr 04, 2023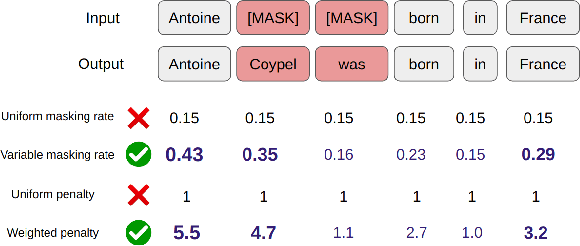
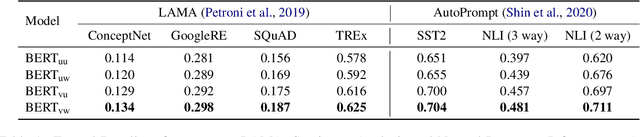
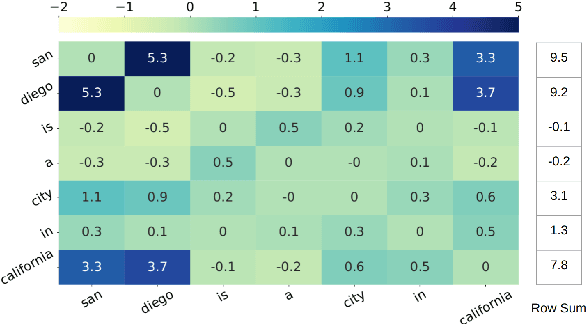
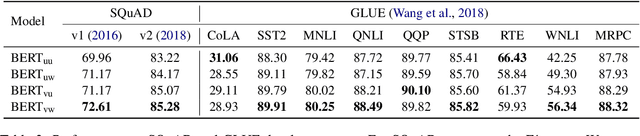
Masked language modeling (MLM) plays a key role in pretraining large language models. But the MLM objective is often dominated by high-frequency words that are sub-optimal for learning factual knowledge. In this work, we propose an approach for influencing MLM pretraining in a way that can improve language model performance on a variety of knowledge-intensive tasks. We force the language model to prioritize informative words in a fully unsupervised way. Experiments demonstrate that the proposed approach can significantly improve the performance of pretrained language models on tasks such as factual recall, question answering, sentiment analysis, and natural language inference in a closed-book setting.