 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving In-Context Learning with Reasoning Distillation
Apr 14, 2025



Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model's understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
Mitigating Hallucination in Fictional Character Role-Play
Jun 25, 2024
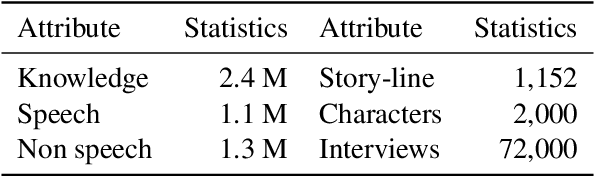
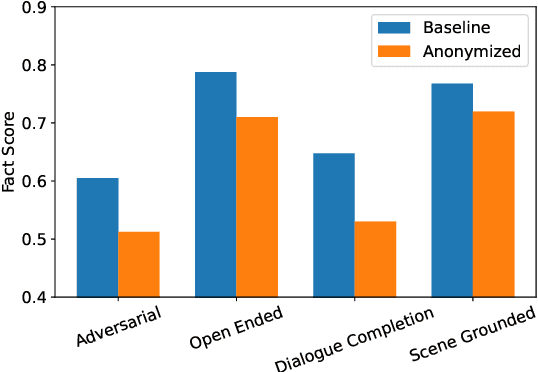
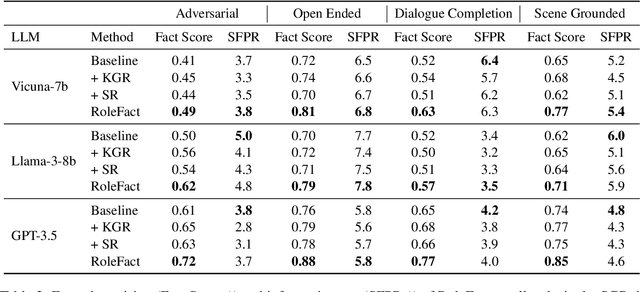
Role-playing has wide-ranging applications in customer support, embodied agents, computational social science, etc. The influence of parametric world knowledge of large language models (LLMs) often causes role-playing characters to act out of character and hallucinate about things outside the scope of their knowledge. In this work, we focus on the evaluation and mitigation of hallucination in fictional character role-play. We introduce a dataset with more than 2,000 characters and 72,000 interviews, including 18,000 adversarial questions. We propose RoleFact, a role-playing method that mitigates hallucination by modulating the influence of parametric knowledge using a pre-calibrated confidence threshold. Experiments show that the proposed method improves the factual precision of generated responses by 18% for adversarial questions with a 44% reduction in temporal hallucination for time-sensitive interviews. The code and the dataset will be available at https://github.com/NafisSadeq/rolefact.git.
LLM+Reasoning+Planning for supporting incomplete user queries in presence of APIs
May 21, 2024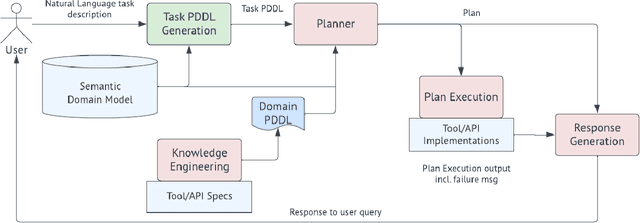
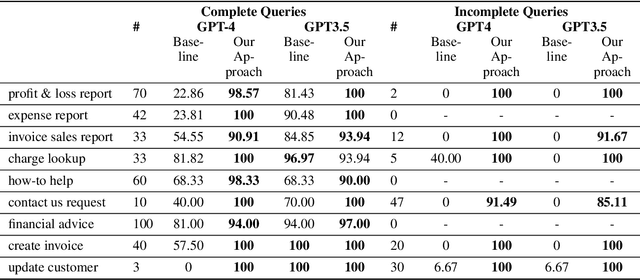
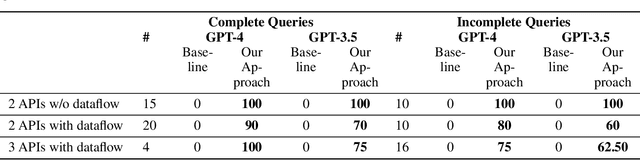
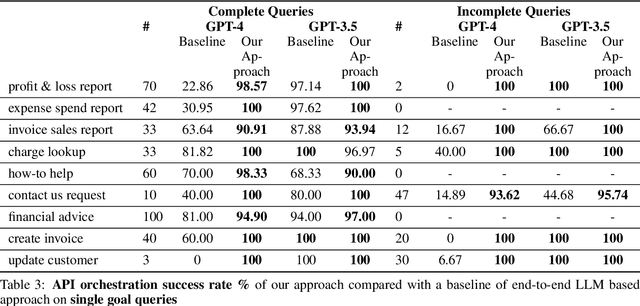
Recent availability of Large Language Models (LLMs) has led to the development of numerous LLM-based approaches aimed at providing natural language interfaces for various end-user tasks. These end-user tasks in turn can typically be accomplished by orchestrating a given set of APIs. In practice, natural language task requests (user queries) are often incomplete, i.e., they may not contain all the information required by the APIs. While LLMs excel at natural language processing (NLP) tasks, they frequently hallucinate on missing information or struggle with orchestrating the APIs. The key idea behind our proposed approach is to leverage logical reasoning and classical AI planning along with an LLM for accurately answering user queries including identification and gathering of any missing information in these queries. Our approach uses an LLM and ASP (Answer Set Programming) solver to translate a user query to a representation in Planning Domain Definition Language (PDDL) via an intermediate representation in ASP. We introduce a special API "get_info_api" for gathering missing information. We model all the APIs as PDDL actions in a way that supports dataflow between the APIs. Our approach then uses a classical AI planner to generate an orchestration of API calls (including calls to get_info_api) to answer the user query. Our evaluation results show that our approach significantly outperforms a pure LLM based approach by achieving over 95\% success rate in most cases on a dataset containing complete and incomplete single goal and multi-goal queries where the multi-goal queries may or may not require dataflow among the APIs.
Unsupervised Improvement of Factual Knowledge in Language Models
Apr 04, 2023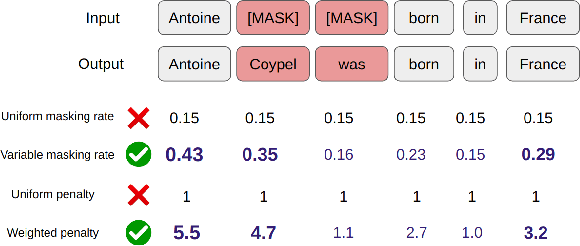
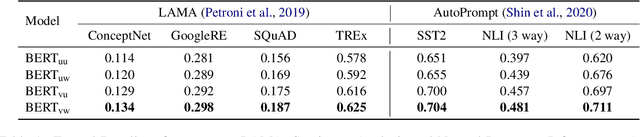
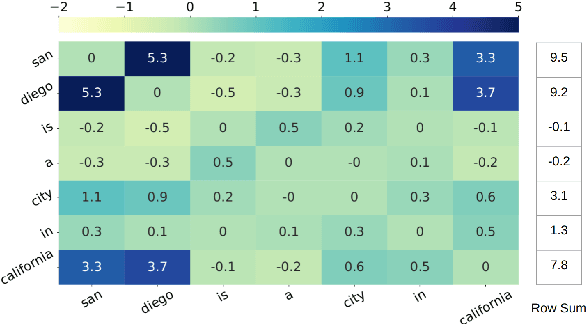
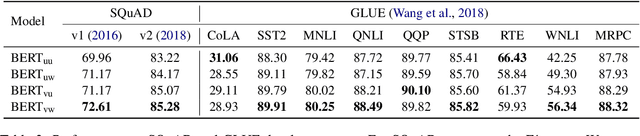
Masked language modeling (MLM) plays a key role in pretraining large language models. But the MLM objective is often dominated by high-frequency words that are sub-optimal for learning factual knowledge. In this work, we propose an approach for influencing MLM pretraining in a way that can improve language model performance on a variety of knowledge-intensive tasks. We force the language model to prioritize informative words in a fully unsupervised way. Experiments demonstrate that the proposed approach can significantly improve the performance of pretrained language models on tasks such as factual recall, question answering, sentiment analysis, and natural language inference in a closed-book setting.