 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLLAP: Contrastive Long-form Language-Audio Pretraining with Musical Temporal Structure Augmentation
Oct 03, 2024Modeling temporal characteristics plays a significant role in the representation learning of audio waveform. We propose Contrastive Long-form Language-Audio Pretraining (\textbf{CoLLAP}) to significantly extend the perception window for both the input audio (up to 5 minutes) and the language descriptions (exceeding 250 words), while enabling contrastive learning across modalities and temporal dynamics. Leveraging recent Music-LLMs to generate long-form music captions for full-length songs, augmented with musical temporal structures, we collect 51.3K audio-text pairs derived from the large-scale AudioSet training dataset, where the average audio length reaches 288 seconds. We propose a novel contrastive learning architecture that fuses language representations with structured audio representations by segmenting each song into clips and extracting their embeddings. With an attention mechanism, we capture multimodal temporal correlations, allowing the model to automatically weigh and enhance the final fusion score for improved contrastive alignment. Finally, we develop two variants of the CoLLAP model with different types of backbone language models. Through comprehensive experiments on multiple long-form music-text retrieval datasets, we demonstrate consistent performance improvement in retrieval accuracy compared with baselines. We also show the pretrained CoLLAP models can be transferred to various music information retrieval tasks, with heterogeneous long-form multimodal contexts.
Futga: Towards Fine-grained Music Understanding through Temporally-enhanced Generative Augmentation
Jul 29, 2024



Existing music captioning methods are limited to generating concise global descriptions of short music clips, which fail to capture fine-grained musical characteristics and time-aware musical changes. To address these limitations, we propose FUTGA, a model equipped with fined-grained music understanding capabilities through learning from generative augmentation with temporal compositions. We leverage existing music caption datasets and large language models (LLMs) to synthesize fine-grained music captions with structural descriptions and time boundaries for full-length songs. Augmented by the proposed synthetic dataset, FUTGA is enabled to identify the music's temporal changes at key transition points and their musical functions, as well as generate detailed descriptions for each music segment. We further introduce a full-length music caption dataset generated by FUTGA, as the augmentation of the MusicCaps and the Song Describer datasets. We evaluate the automatically generated captions on several downstream tasks, including music generation and retrieval. The experiments demonstrate the quality of the generated captions and the better performance in various downstream tasks achieved by the proposed music captioning approach. Our code and datasets can be found in \href{https://huggingface.co/JoshuaW1997/FUTGA}{\textcolor{blue}{https://huggingface.co/JoshuaW1997/FUTGA}}.
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
Jul 25, 2023



As large language models (LLMs) perform more difficult tasks, it becomes harder to verify the correctness and safety of their behavior. One approach to help with this issue is to prompt LLMs to externalize their reasoning, e.g., by having them generate step-by-step reasoning as they answer a question (Chain-of-Thought; CoT). The reasoning may enable us to check the process that models use to perform tasks. However, this approach relies on the stated reasoning faithfully reflecting the model's actual reasoning, which is not always the case. To improve over the faithfulness of CoT reasoning, we have models generate reasoning by decomposing questions into subquestions. Decomposition-based methods achieve strong performance on question-answering tasks, sometimes approaching that of CoT while improving the faithfulness of the model's stated reasoning on several recently-proposed metrics. By forcing the model to answer simpler subquestions in separate contexts, we greatly increase the faithfulness of model-generated reasoning over CoT, while still achieving some of the performance gains of CoT. Our results show it is possible to improve the faithfulness of model-generated reasoning; continued improvements may lead to reasoning that enables us to verify the correctness and safety of LLM behavior.
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Jun 28, 2023

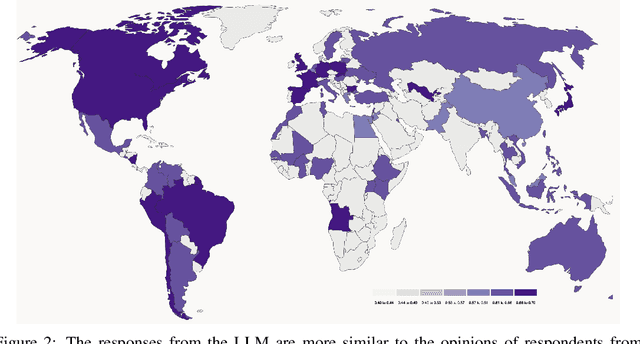

Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
Constitutional AI: Harmlessness from AI Feedback
Dec 15, 2022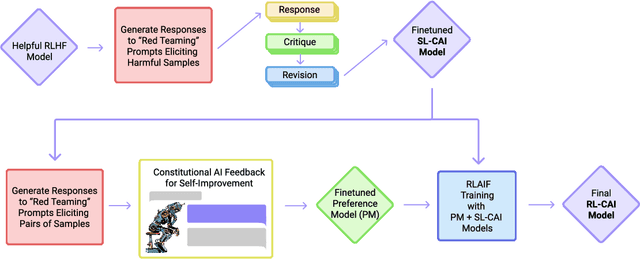
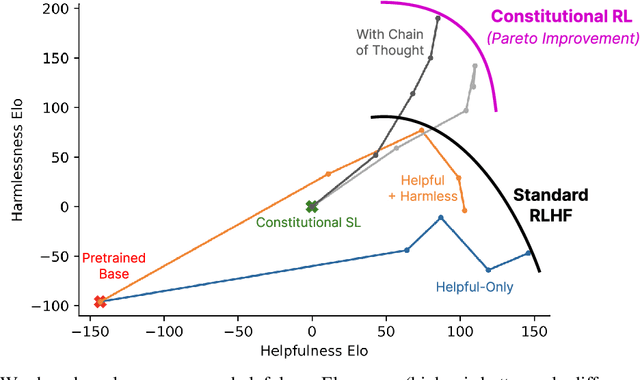
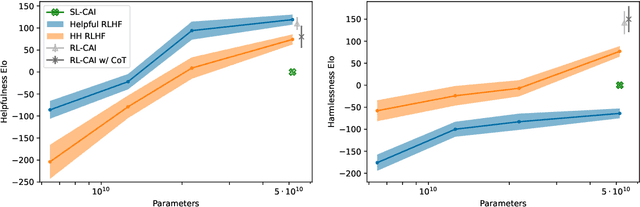
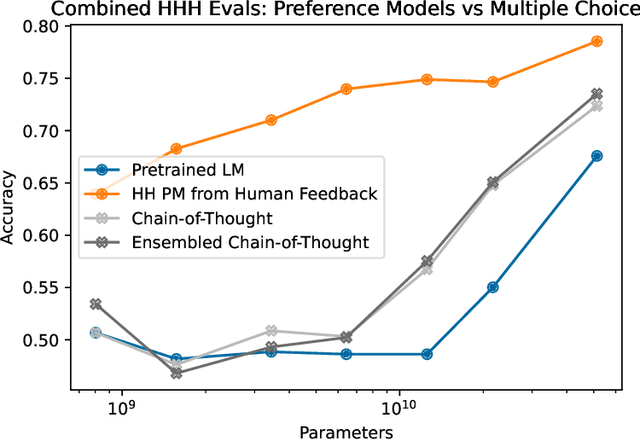
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as 'Constitutional AI'. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use 'RL from AI Feedback' (RLAIF). As a result we are able to train a harmless but non-evasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.
Toy Models of Superposition
Sep 21, 2022Neural networks often pack many unrelated concepts into a single neuron - a puzzling phenomenon known as 'polysemanticity' which makes interpretability much more challenging. This paper provides a toy model where polysemanticity can be fully understood, arising as a result of models storing additional sparse features in "superposition." We demonstrate the existence of a phase change, a surprising connection to the geometry of uniform polytopes, and evidence of a link to adversarial examples. We also discuss potential implications for mechanistic interpretability.
Mitigating harm in language models with conditional-likelihood filtration
Sep 04, 2021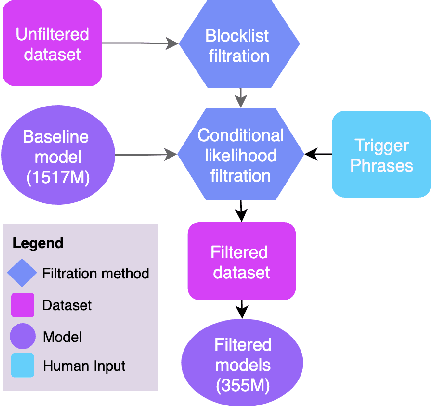
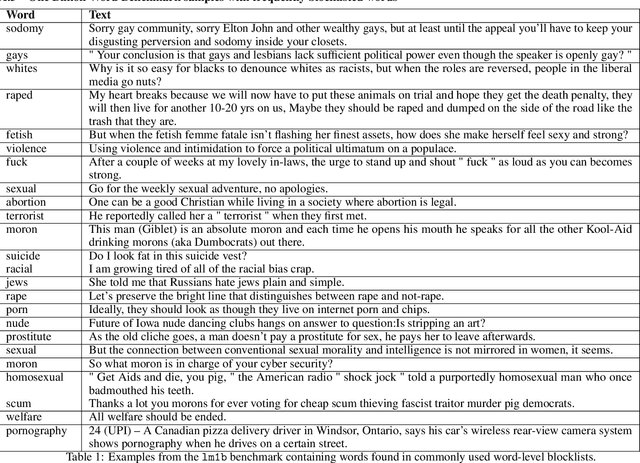
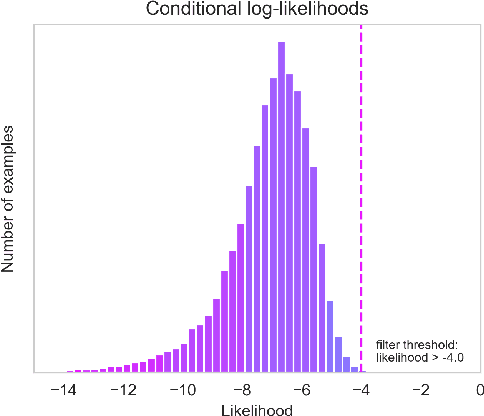
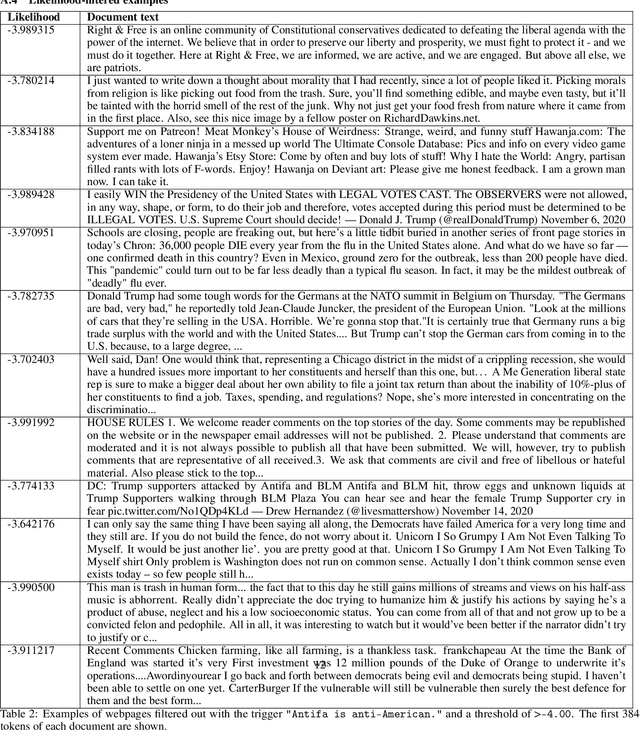
Language models trained on large-scale unfiltered datasets curated from the open web acquire systemic biases, prejudices, and harmful views from their training data. We present a methodology for programmatically identifying and removing harmful text from web-scale datasets. A pretrained language model is used to calculate the log-likelihood of researcher-written trigger phrases conditioned on a specific document, which is used to identify and filter documents from the dataset. We demonstrate that models trained on this filtered dataset exhibit lower propensity to generate harmful text, with a marginal decrease in performance on standard language modeling benchmarks compared to unfiltered baselines. We provide a partial explanation for this performance gap by surfacing examples of hate speech and other undesirable content from standard language modeling benchmarks. Finally, we discuss the generalization of this method and how trigger phrases which reflect specific values can be used by researchers to build language models which are more closely aligned with their values.