 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Capacity for Moral Self-Correction in Large Language Models
Feb 18, 2023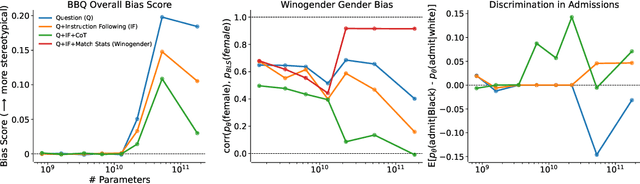

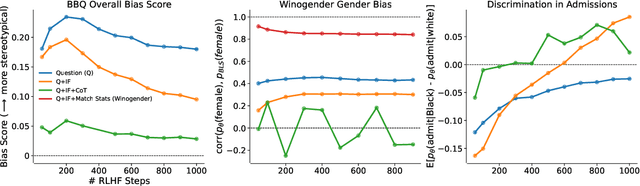

We test the hypothesis that language models trained with reinforcement learning from human feedback (RLHF) have the capability to "morally self-correct" -- to avoid producing harmful outputs -- if instructed to do so. We find strong evidence in support of this hypothesis across three different experiments, each of which reveal different facets of moral self-correction. We find that the capability for moral self-correction emerges at 22B model parameters, and typically improves with increasing model size and RLHF training. We believe that at this level of scale, language models obtain two capabilities that they can use for moral self-correction: (1) they can follow instructions and (2) they can learn complex normative concepts of harm like stereotyping, bias, and discrimination. As such, they can follow instructions to avoid certain kinds of morally harmful outputs. We believe our results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles.
Constitutional AI: Harmlessness from AI Feedback
Dec 15, 2022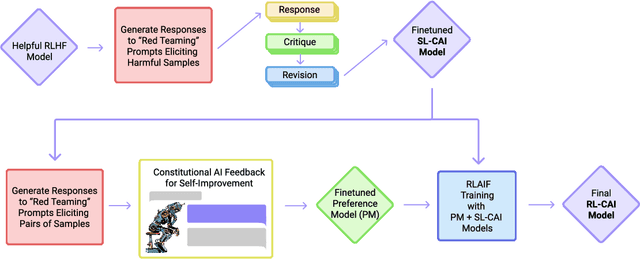
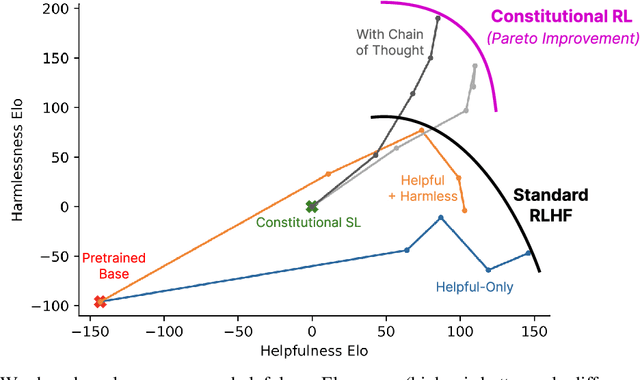
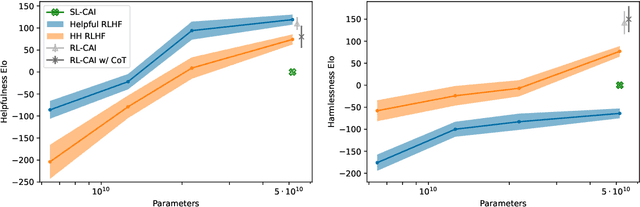
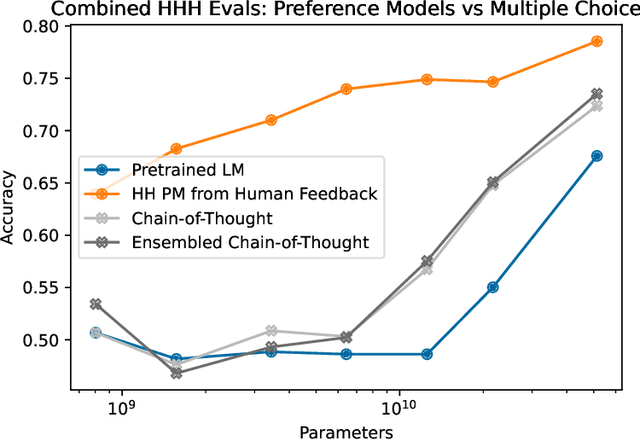
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as 'Constitutional AI'. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use 'RL from AI Feedback' (RLAIF). As a result we are able to train a harmless but non-evasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.
Toy Models of Superposition
Sep 21, 2022Neural networks often pack many unrelated concepts into a single neuron - a puzzling phenomenon known as 'polysemanticity' which makes interpretability much more challenging. This paper provides a toy model where polysemanticity can be fully understood, arising as a result of models storing additional sparse features in "superposition." We demonstrate the existence of a phase change, a surprising connection to the geometry of uniform polytopes, and evidence of a link to adversarial examples. We also discuss potential implications for mechanistic interpretability.