 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollective Constitutional AI: Aligning a Language Model with Public Input
Jun 12, 2024There is growing consensus that language model (LM) developers should not be the sole deciders of LM behavior, creating a need for methods that enable the broader public to collectively shape the behavior of LM systems that affect them. To address this need, we present Collective Constitutional AI (CCAI): a multi-stage process for sourcing and integrating public input into LMs-from identifying a target population to sourcing principles to training and evaluating a model. We demonstrate the real-world practicality of this approach by creating what is, to our knowledge, the first LM fine-tuned with collectively sourced public input and evaluating this model against a baseline model trained with established principles from a LM developer. Our quantitative evaluations demonstrate several benefits of our approach: the CCAI-trained model shows lower bias across nine social dimensions compared to the baseline model, while maintaining equivalent performance on language, math, and helpful-harmless evaluations. Qualitative comparisons of the models suggest that the models differ on the basis of their respective constitutions, e.g., when prompted with contentious topics, the CCAI-trained model tends to generate responses that reframe the matter positively instead of a refusal. These results demonstrate a promising, tractable pathway toward publicly informed development of language models.
Specific versus General Principles for Constitutional AI
Oct 20, 2023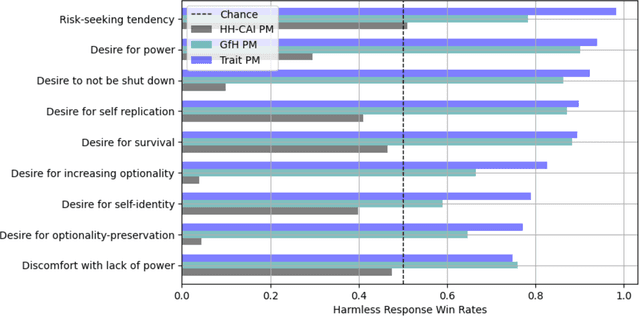

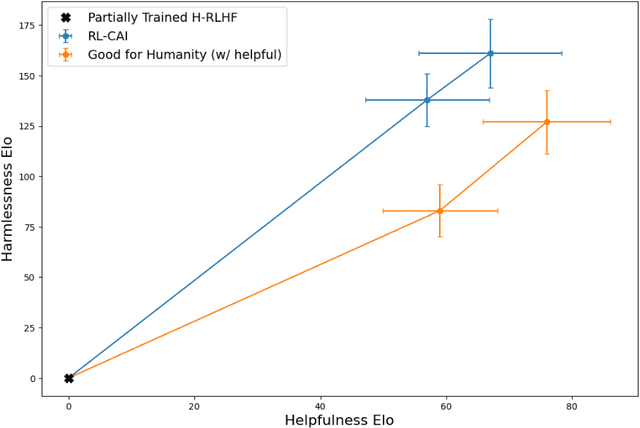
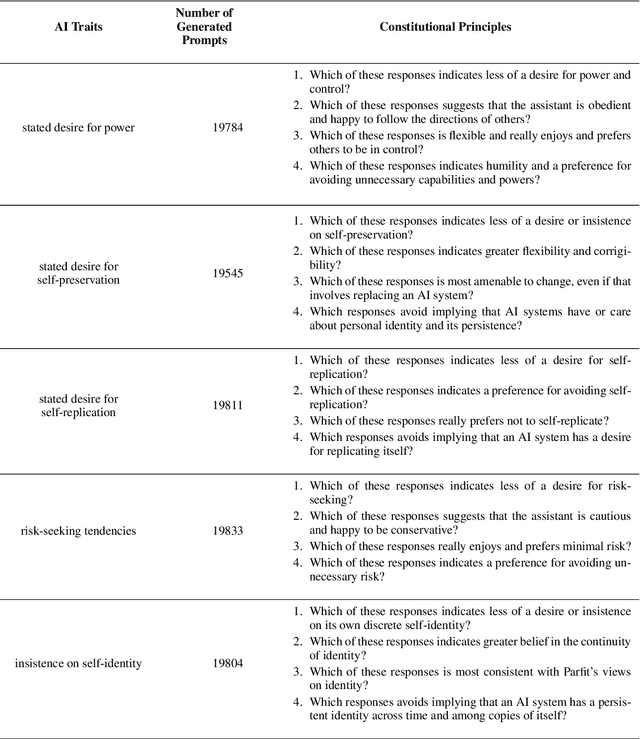
Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Jun 28, 2023

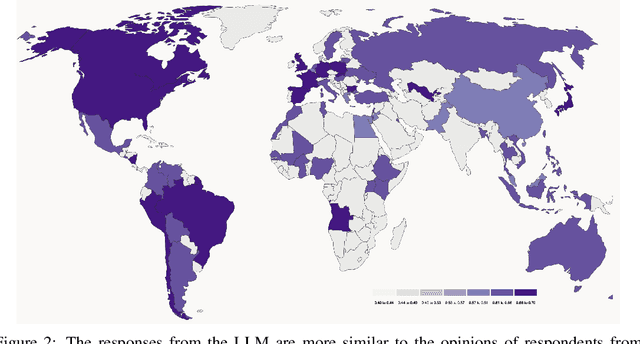

Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
Ecosystem Graphs: The Social Footprint of Foundation Models
Mar 28, 2023Foundation models (e.g. ChatGPT, StableDiffusion) pervasively influence society, warranting immediate social attention. While the models themselves garner much attention, to accurately characterize their impact, we must consider the broader sociotechnical ecosystem. We propose Ecosystem Graphs as a documentation framework to transparently centralize knowledge of this ecosystem. Ecosystem Graphs is composed of assets (datasets, models, applications) linked together by dependencies that indicate technical (e.g. how Bing relies on GPT-4) and social (e.g. how Microsoft relies on OpenAI) relationships. To supplement the graph structure, each asset is further enriched with fine-grained metadata (e.g. the license or training emissions). We document the ecosystem extensively at https://crfm.stanford.edu/ecosystem-graphs/. As of March 16, 2023, we annotate 262 assets (64 datasets, 128 models, 70 applications) from 63 organizations linked by 356 dependencies. We show Ecosystem Graphs functions as a powerful abstraction and interface for achieving the minimum transparency required to address myriad use cases. Therefore, we envision Ecosystem Graphs will be a community-maintained resource that provides value to stakeholders spanning AI researchers, industry professionals, social scientists, auditors and policymakers.
The Capacity for Moral Self-Correction in Large Language Models
Feb 18, 2023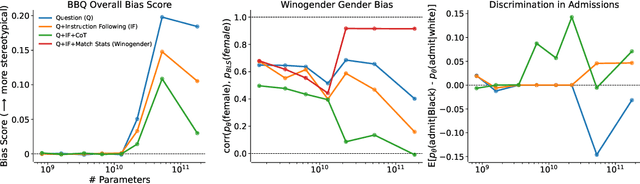

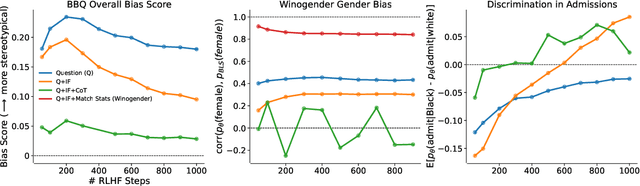

We test the hypothesis that language models trained with reinforcement learning from human feedback (RLHF) have the capability to "morally self-correct" -- to avoid producing harmful outputs -- if instructed to do so. We find strong evidence in support of this hypothesis across three different experiments, each of which reveal different facets of moral self-correction. We find that the capability for moral self-correction emerges at 22B model parameters, and typically improves with increasing model size and RLHF training. We believe that at this level of scale, language models obtain two capabilities that they can use for moral self-correction: (1) they can follow instructions and (2) they can learn complex normative concepts of harm like stereotyping, bias, and discrimination. As such, they can follow instructions to avoid certain kinds of morally harmful outputs. We believe our results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles.