 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecific versus General Principles for Constitutional AI
Oct 20, 2023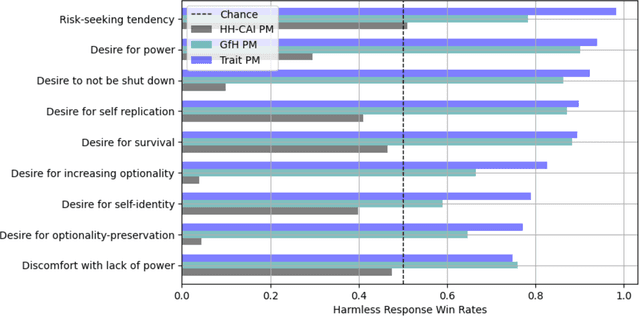

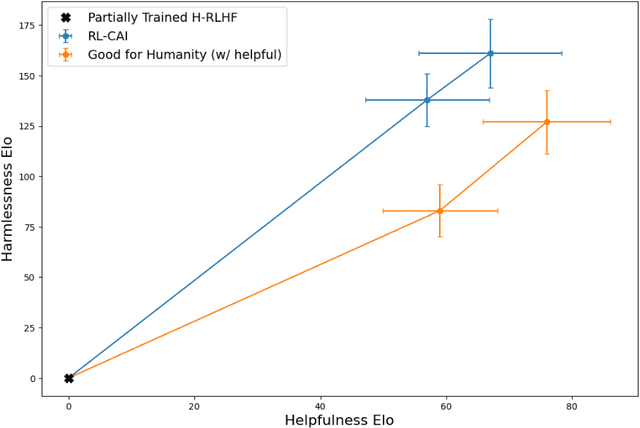
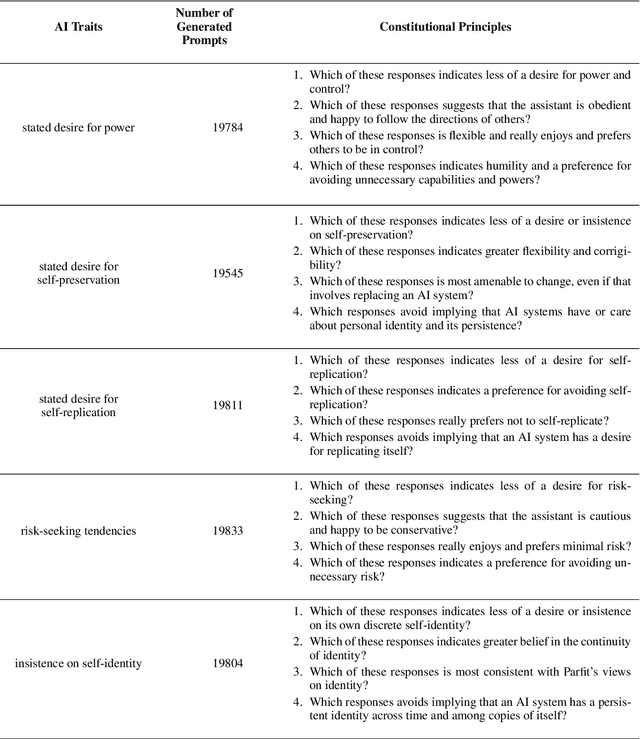
Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
Aligned with Whom? Direct and social goals for AI systems
May 09, 2022
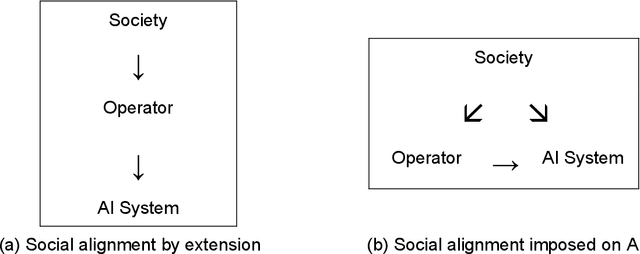
As artificial intelligence (AI) becomes more powerful and widespread, the AI alignment problem - how to ensure that AI systems pursue the goals that we want them to pursue - has garnered growing attention. This article distinguishes two types of alignment problems depending on whose goals we consider, and analyzes the different solutions necessitated by each. The direct alignment problem considers whether an AI system accomplishes the goals of the entity operating it. In contrast, the social alignment problem considers the effects of an AI system on larger groups or on society more broadly. In particular, it also considers whether the system imposes externalities on others. Whereas solutions to the direct alignment problem center around more robust implementation, social alignment problems typically arise because of conflicts between individual and group-level goals, elevating the importance of AI governance to mediate such conflicts. Addressing the social alignment problem requires both enforcing existing norms on their developers and operators and designing new norms that apply directly to AI systems.
Truthful AI: Developing and governing AI that does not lie
Oct 13, 2021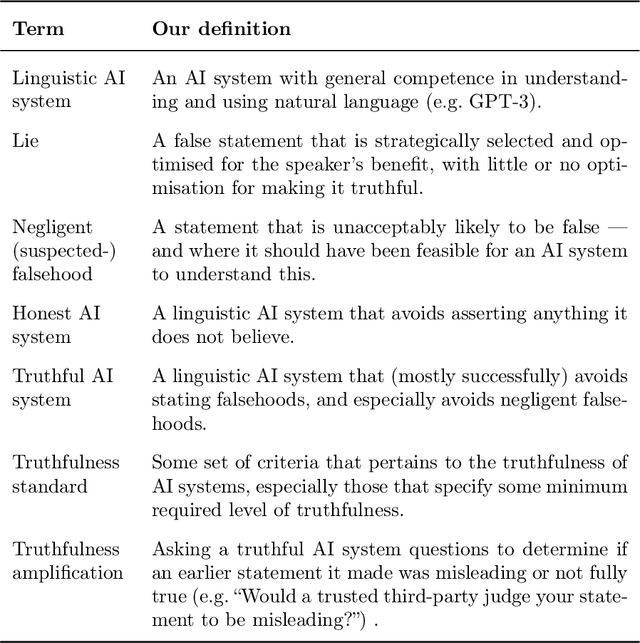

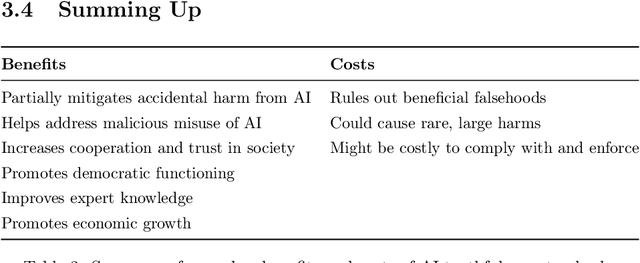

In many contexts, lying -- the use of verbal falsehoods to deceive -- is harmful. While lying has traditionally been a human affair, AI systems that make sophisticated verbal statements are becoming increasingly prevalent. This raises the question of how we should limit the harm caused by AI "lies" (i.e. falsehoods that are actively selected for). Human truthfulness is governed by social norms and by laws (against defamation, perjury, and fraud). Differences between AI and humans present an opportunity to have more precise standards of truthfulness for AI, and to have these standards rise over time. This could provide significant benefits to public epistemics and the economy, and mitigate risks of worst-case AI futures. Establishing norms or laws of AI truthfulness will require significant work to: (1) identify clear truthfulness standards; (2) create institutions that can judge adherence to those standards; and (3) develop AI systems that are robustly truthful. Our initial proposals for these areas include: (1) a standard of avoiding "negligent falsehoods" (a generalisation of lies that is easier to assess); (2) institutions to evaluate AI systems before and after real-world deployment; and (3) explicitly training AI systems to be truthful via curated datasets and human interaction. A concerning possibility is that evaluation mechanisms for eventual truthfulness standards could be captured by political interests, leading to harmful censorship and propaganda. Avoiding this might take careful attention. And since the scale of AI speech acts might grow dramatically over the coming decades, early truthfulness standards might be particularly important because of the precedents they set.