 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecific versus General Principles for Constitutional AI
Oct 20, 2023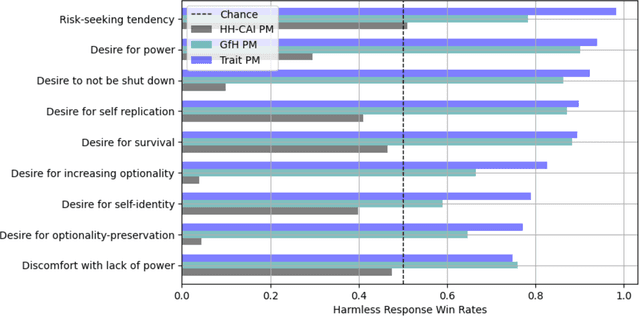

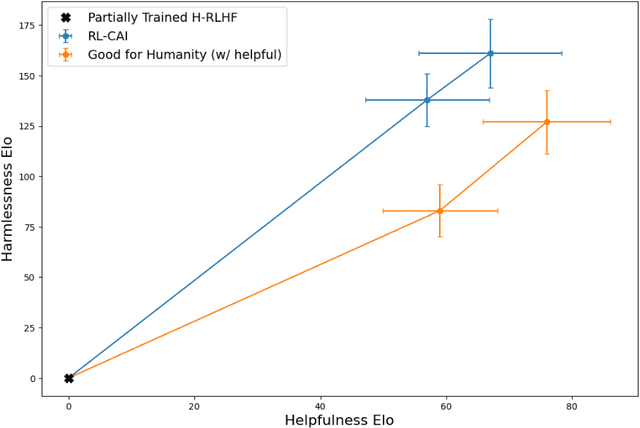
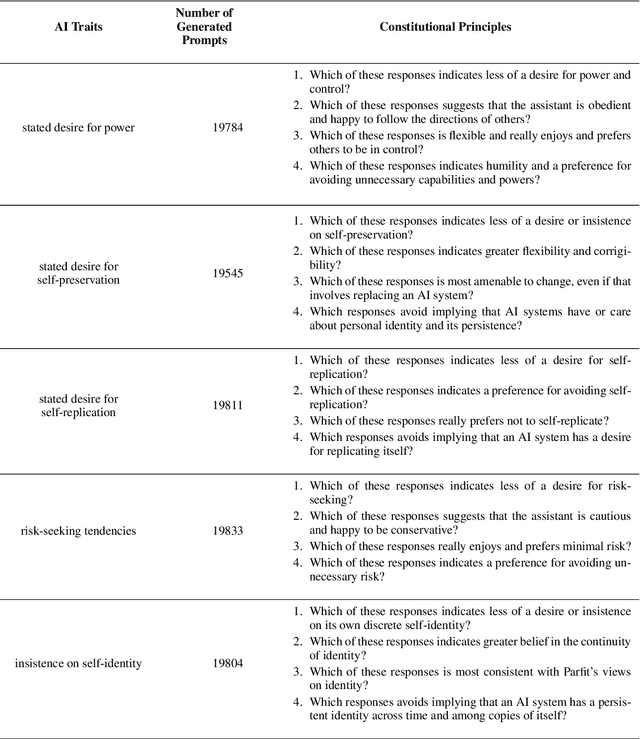
Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.