 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthful AI: Developing and governing AI that does not lie
Oct 13, 2021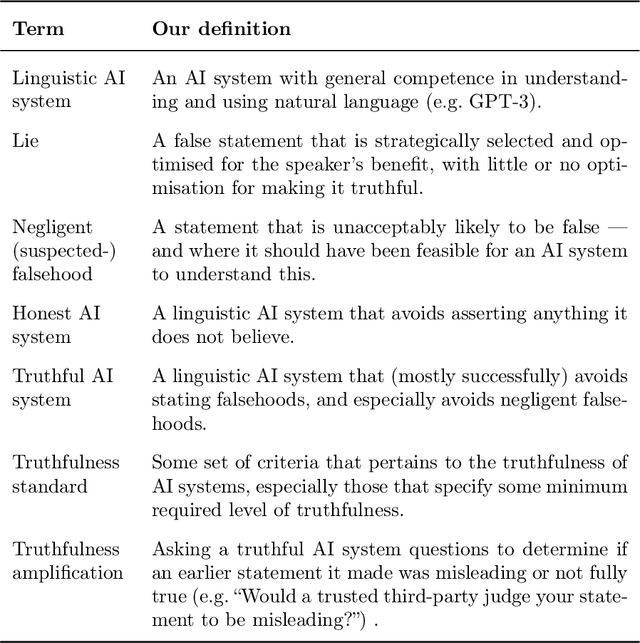


In many contexts, lying -- the use of verbal falsehoods to deceive -- is harmful. While lying has traditionally been a human affair, AI systems that make sophisticated verbal statements are becoming increasingly prevalent. This raises the question of how we should limit the harm caused by AI "lies" (i.e. falsehoods that are actively selected for). Human truthfulness is governed by social norms and by laws (against defamation, perjury, and fraud). Differences between AI and humans present an opportunity to have more precise standards of truthfulness for AI, and to have these standards rise over time. This could provide significant benefits to public epistemics and the economy, and mitigate risks of worst-case AI futures. Establishing norms or laws of AI truthfulness will require significant work to: (1) identify clear truthfulness standards; (2) create institutions that can judge adherence to those standards; and (3) develop AI systems that are robustly truthful. Our initial proposals for these areas include: (1) a standard of avoiding "negligent falsehoods" (a generalisation of lies that is easier to assess); (2) institutions to evaluate AI systems before and after real-world deployment; and (3) explicitly training AI systems to be truthful via curated datasets and human interaction. A concerning possibility is that evaluation mechanisms for eventual truthfulness standards could be captured by political interests, leading to harmful censorship and propaganda. Avoiding this might take careful attention. And since the scale of AI speech acts might grow dramatically over the coming decades, early truthfulness standards might be particularly important because of the precedents they set.
Understanding when spatial transformer networks do not support invariance, and what to do about it
May 04, 2020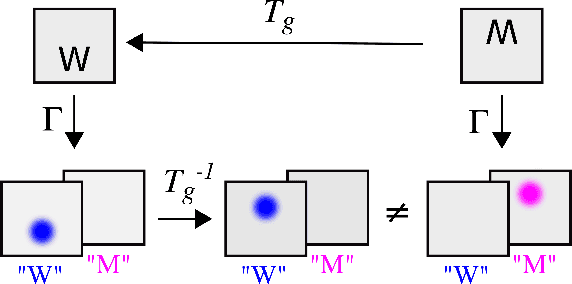
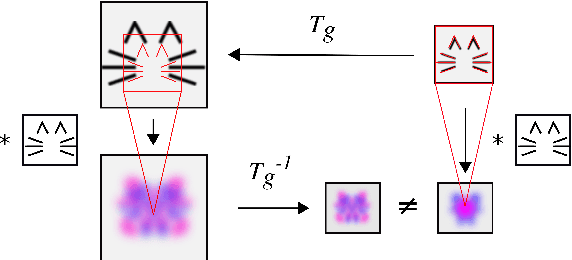
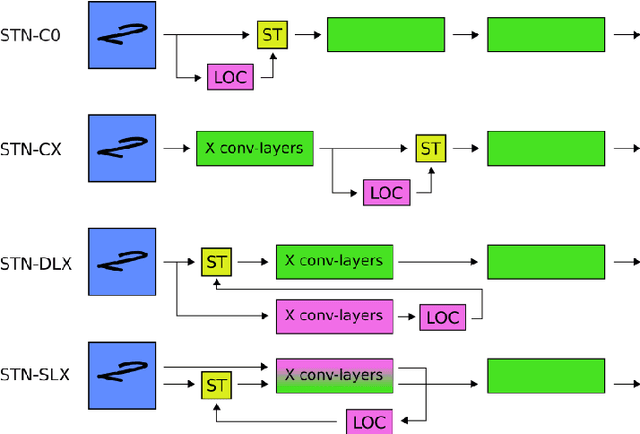
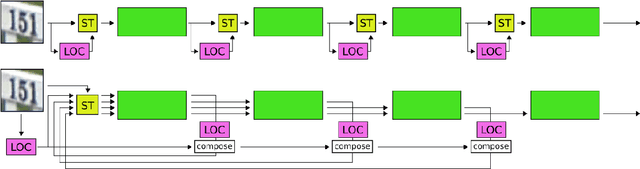
Spatial transformer networks (STNs) were designed to enable convolutional neural networks (CNNs) to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image with those of its original. STNs are therefore unable to support invariance when transforming CNN feature maps. We present a simple proof for this and study the practical implications, showing that this inability is coupled with decreased classification accuracy. We therefore investigate alternative STN architectures that make use of complex features. We find that while deeper localization networks are difficult to train, localization networks that share parameters with the classification network remain stable as they grow deeper, which allows for higher classification accuracy on difficult datasets. Finally, we explore the interaction between localization network complexity and iterative image alignment.
Inability of spatial transformations of CNN feature maps to support invariant recognition
Apr 30, 2020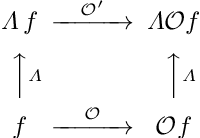
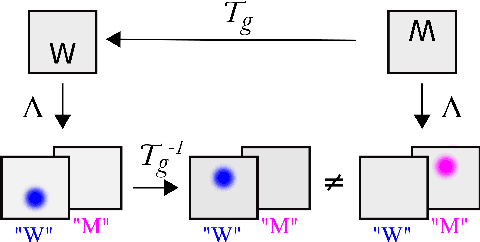
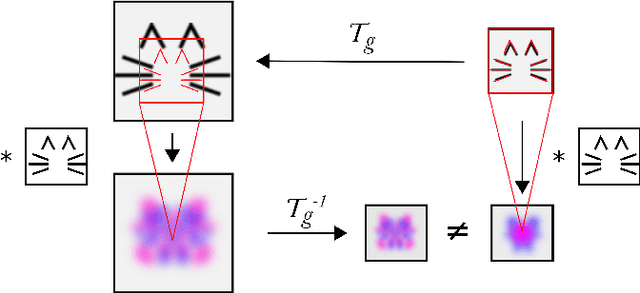
A large number of deep learning architectures use spatial transformations of CNN feature maps or filters to better deal with variability in object appearance caused by natural image transformations. In this paper, we prove that spatial transformations of CNN feature maps cannot align the feature maps of a transformed image to match those of its original, for general affine transformations, unless the extracted features are themselves invariant. Our proof is based on elementary analysis for both the single- and multi-layer network case. The results imply that methods based on spatial transformations of CNN feature maps or filters cannot replace image alignment of the input and cannot enable invariant recognition for general affine transformations, specifically not for scaling transformations or shear transformations. For rotations and reflections, spatially transforming feature maps or filters can enable invariance but only for networks with learnt or hardcoded rotation- or reflection-invariant features
The problems with using STNs to align CNN feature maps
Jan 14, 2020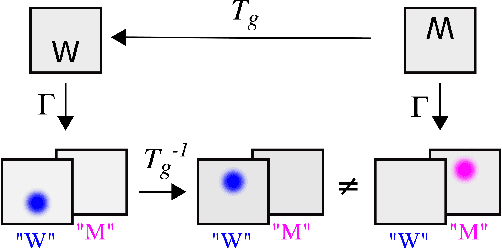



Spatial transformer networks (STNs) were designed to enable CNNs to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image and its original. We present a theoretical argument for this and investigate the practical implications, showing that this inability is coupled with decreased classification accuracy. We advocate taking advantage of more complex features in deeper layers by instead sharing parameters between the classification and the localisation network.