 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom AGI to ASI
Jun 10, 2026Over the last decade, building human-level artificial general intelligence has moved from far-fetched speculation to being a concrete next-decade target for many of the largest AI organisations. Achieving this goal would have profound and far-reaching impacts on human society, which raises many complex questions for the decade ahead. This report investigates how AI itself might continue to develop in a post-AGI world along the continuum of machine intelligence. The endpoint of this continuum, Universal AI, is theoretically well understood, which provides some formal grounding for the main focus of this report: the transition from human-level AGI to artificial general superintelligence, which, intuitively, can be understood as a system that is more intelligent and cognitively capable than large organisations of humans. After characterizing ASI, the report discusses four potential pathways from AGI to ASI: scaling AGI, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi-agent collectives. The report then discusses possible frictions and bottlenecks along these pathways. Determining whether the impact of these frictions will be negligible or substantial raises a number of concrete open research questions. Due to large uncertainties for predicting ASI progress, it cannot be ruled out that AI progress might continue to accelerate over the next years. This could imply that the image of a single transformative step change, caused by the introduction of human-level AGI into our society, could be inaccurate. More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology. Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.
Artificial Intelligence: Arguments for Catastrophic Risk
Jan 27, 2024Recent progress in artificial intelligence (AI) has drawn attention to the technology's transformative potential, including what some see as its prospects for causing large-scale harm. We review two influential arguments purporting to show how AI could pose catastrophic risks. The first argument -- the Problem of Power-Seeking -- claims that, under certain assumptions, advanced AI systems are likely to engage in dangerous power-seeking behavior in pursuit of their goals. We review reasons for thinking that AI systems might seek power, that they might obtain it, that this could lead to catastrophe, and that we might build and deploy such systems anyway. The second argument claims that the development of human-level AI will unlock rapid further progress, culminating in AI systems far more capable than any human -- this is the Singularity Hypothesis. Power-seeking behavior on the part of such systems might be particularly dangerous. We discuss a variety of objections to both arguments and conclude by assessing the state of the debate.
Truthful AI: Developing and governing AI that does not lie
Oct 13, 2021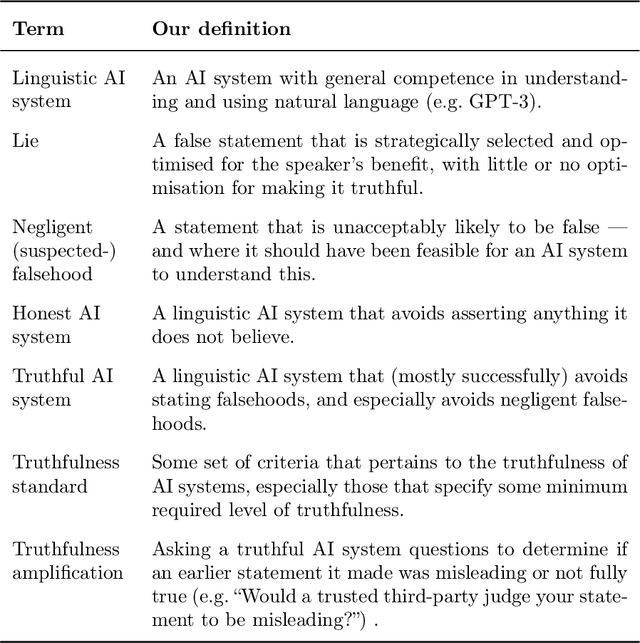

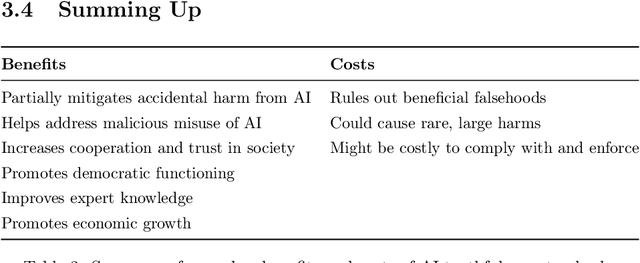

In many contexts, lying -- the use of verbal falsehoods to deceive -- is harmful. While lying has traditionally been a human affair, AI systems that make sophisticated verbal statements are becoming increasingly prevalent. This raises the question of how we should limit the harm caused by AI "lies" (i.e. falsehoods that are actively selected for). Human truthfulness is governed by social norms and by laws (against defamation, perjury, and fraud). Differences between AI and humans present an opportunity to have more precise standards of truthfulness for AI, and to have these standards rise over time. This could provide significant benefits to public epistemics and the economy, and mitigate risks of worst-case AI futures. Establishing norms or laws of AI truthfulness will require significant work to: (1) identify clear truthfulness standards; (2) create institutions that can judge adherence to those standards; and (3) develop AI systems that are robustly truthful. Our initial proposals for these areas include: (1) a standard of avoiding "negligent falsehoods" (a generalisation of lies that is easier to assess); (2) institutions to evaluate AI systems before and after real-world deployment; and (3) explicitly training AI systems to be truthful via curated datasets and human interaction. A concerning possibility is that evaluation mechanisms for eventual truthfulness standards could be captured by political interests, leading to harmful censorship and propaganda. Avoiding this might take careful attention. And since the scale of AI speech acts might grow dramatically over the coming decades, early truthfulness standards might be particularly important because of the precedents they set.