 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDs for AI Systems
Jun 17, 2024



AI systems are increasingly pervasive, yet information needed to decide whether and how to engage with them may not exist or be accessible. A user may not be able to verify whether a system satisfies certain safety standards. An investigator may not know whom to investigate when a system causes an incident. A platform may find it difficult to penalize repeated negative interactions with the same system. Across a number of domains, IDs address analogous problems by identifying \textit{particular} entities (e.g., a particular Boeing 747) and providing information about other entities of the same class (e.g., some or all Boeing 747s). We propose a framework in which IDs are ascribed to \textbf{instances} of AI systems (e.g., a particular chat session with Claude 3), and associated information is accessible to parties seeking to interact with that system. We characterize IDs for AI systems, argue that there could be significant demand for IDs from key actors, analyze how those actors could incentivize ID adoption, explore potential implementations of our framework, and highlight limitations and risks. IDs seem most warranted in high-stakes settings, where certain actors (e.g., those that enable AI systems to make financial transactions) could experiment with incentives for ID use. Deployers of AI systems could experiment with developing ID implementations. With further study, IDs could help to manage a world where AI systems pervade society.
Truthful AI: Developing and governing AI that does not lie
Oct 13, 2021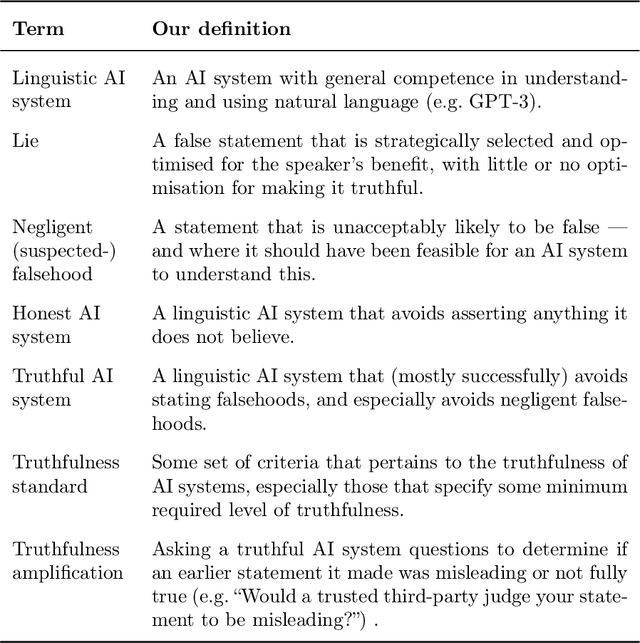

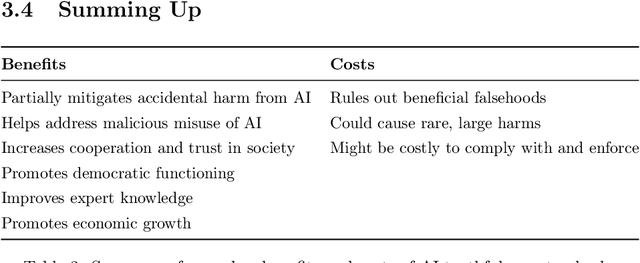

In many contexts, lying -- the use of verbal falsehoods to deceive -- is harmful. While lying has traditionally been a human affair, AI systems that make sophisticated verbal statements are becoming increasingly prevalent. This raises the question of how we should limit the harm caused by AI "lies" (i.e. falsehoods that are actively selected for). Human truthfulness is governed by social norms and by laws (against defamation, perjury, and fraud). Differences between AI and humans present an opportunity to have more precise standards of truthfulness for AI, and to have these standards rise over time. This could provide significant benefits to public epistemics and the economy, and mitigate risks of worst-case AI futures. Establishing norms or laws of AI truthfulness will require significant work to: (1) identify clear truthfulness standards; (2) create institutions that can judge adherence to those standards; and (3) develop AI systems that are robustly truthful. Our initial proposals for these areas include: (1) a standard of avoiding "negligent falsehoods" (a generalisation of lies that is easier to assess); (2) institutions to evaluate AI systems before and after real-world deployment; and (3) explicitly training AI systems to be truthful via curated datasets and human interaction. A concerning possibility is that evaluation mechanisms for eventual truthfulness standards could be captured by political interests, leading to harmful censorship and propaganda. Avoiding this might take careful attention. And since the scale of AI speech acts might grow dramatically over the coming decades, early truthfulness standards might be particularly important because of the precedents they set.