 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-invariant scale-channel networks: Deep networks that generalise to previously unseen scales
Jun 11, 2021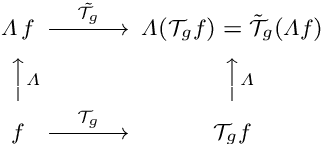
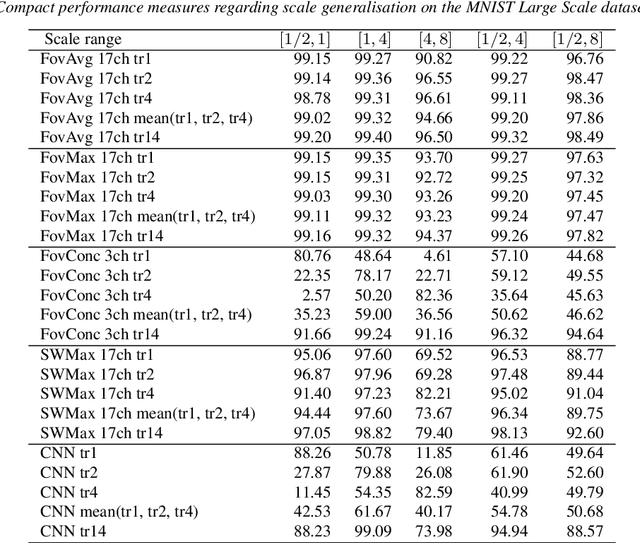
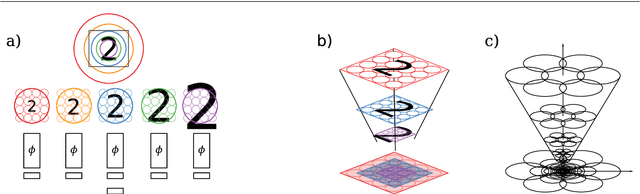

The ability to handle large scale variations is crucial for many real world visual tasks. A straightforward approach for handling scale in a deep network is to process an image at several scales simultaneously in a set of scale channels. Scale invariance can then, in principle, be achieved by using weight sharing between the scale channels together with max or average pooling over the outputs from the scale channels. The ability of such scale channel networks to generalise to scales not present in the training set over significant scale ranges has, however, not previously been explored. In this paper, we present a systematic study of this methodology by implementing different types of scale channel networks and evaluating their ability to generalise to previously unseen scales. We develop a formalism for analysing the covariance and invariance properties of scale channel networks, and explore how different design choices, unique to scaling transformations, affect the overall performance of scale channel networks. We first show that two previously proposed scale channel network designs do not generalise well to scales not present in the training set. We explain theoretically and demonstrate experimentally why generalisation fails in these cases. We then propose a new type of foveated scale channel architecture}, where the scale channels process increasingly larger parts of the image with decreasing resolution. This new type of scale channel network is shown to generalise extremely well, provided sufficient image resolution and the absence of boundary effects. Our proposed FovMax and FovAvg networks perform almost identically over a scale range of 8, also when training on single scale training data, and do also give improved performance when learning from datasets with large scale variations in the small sample regime.
Understanding when spatial transformer networks do not support invariance, and what to do about it
May 04, 2020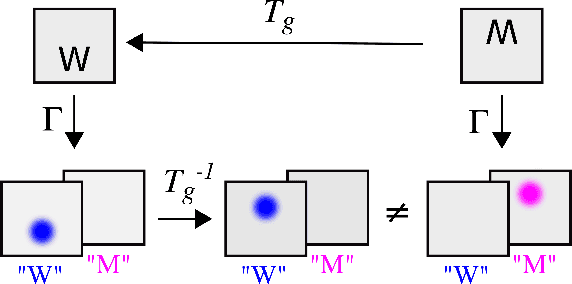
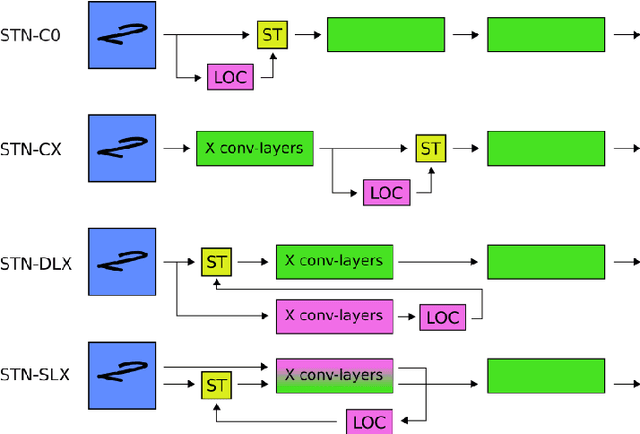
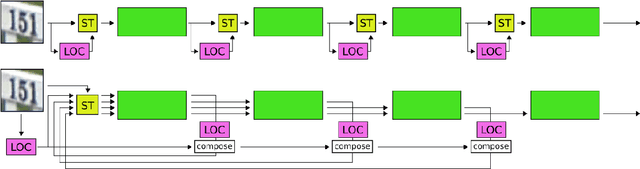
Spatial transformer networks (STNs) were designed to enable convolutional neural networks (CNNs) to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image with those of its original. STNs are therefore unable to support invariance when transforming CNN feature maps. We present a simple proof for this and study the practical implications, showing that this inability is coupled with decreased classification accuracy. We therefore investigate alternative STN architectures that make use of complex features. We find that while deeper localization networks are difficult to train, localization networks that share parameters with the classification network remain stable as they grow deeper, which allows for higher classification accuracy on difficult datasets. Finally, we explore the interaction between localization network complexity and iterative image alignment.
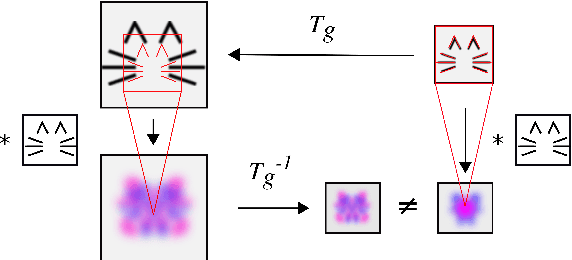
Inability of spatial transformations of CNN feature maps to support invariant recognition
Apr 30, 2020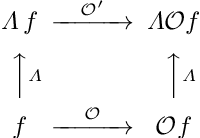
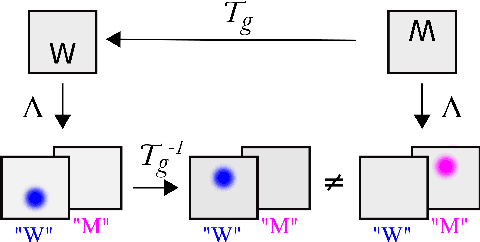
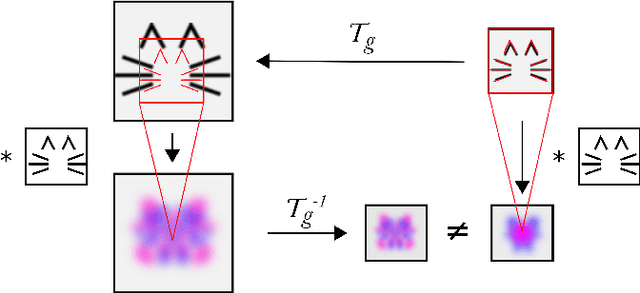
A large number of deep learning architectures use spatial transformations of CNN feature maps or filters to better deal with variability in object appearance caused by natural image transformations. In this paper, we prove that spatial transformations of CNN feature maps cannot align the feature maps of a transformed image to match those of its original, for general affine transformations, unless the extracted features are themselves invariant. Our proof is based on elementary analysis for both the single- and multi-layer network case. The results imply that methods based on spatial transformations of CNN feature maps or filters cannot replace image alignment of the input and cannot enable invariant recognition for general affine transformations, specifically not for scaling transformations or shear transformations. For rotations and reflections, spatially transforming feature maps or filters can enable invariance but only for networks with learnt or hardcoded rotation- or reflection-invariant features
Exploring the ability of CNNs to generalise to previously unseen scales over wide scale ranges
Apr 03, 2020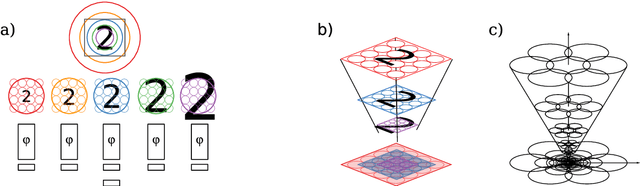
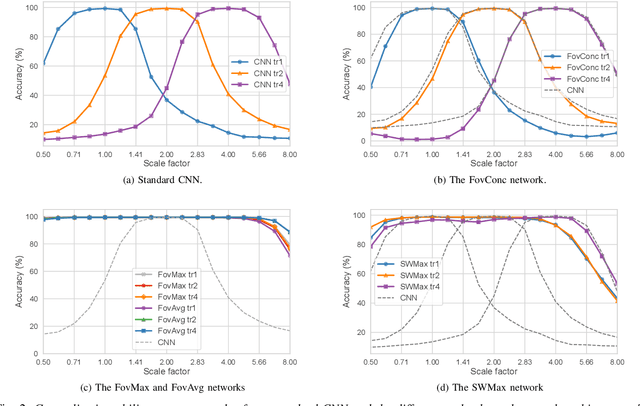
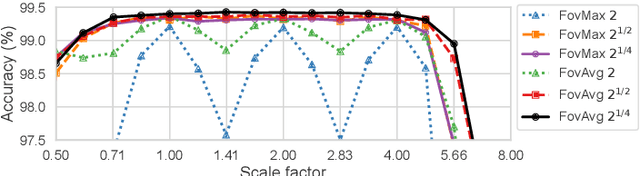

The ability to handle large scale variations is crucial for many real world visual tasks. A straightforward approach for handling scale in a deep network is to process an image at several scales simultaneously in a set of scale channels. Scale invariance can then, in principle, be achieved by using weight sharing between the scale channels together with max or average pooling over the outputs from the scale channels. The ability of such scale channel networks to generalise to scales not present in the training set over significant scale ranges has, however, not previously been explored. We, therefore, present a theoretical analysis of invariance and covariance properties of scale channel networks and perform an experimental evaluation of the ability of different types of scale channel networks to generalise to previously unseen scales. We identify limitations of previous approaches and propose a new type of foveated scale channel architecture, where the scale channels process increasingly larger parts of the image with decreasing resolution. Our proposed FovMax and FovAvg networks perform almost identically over a scale range of 8 also when training on single scale training data and give improvements in the small sample regime.
The problems with using STNs to align CNN feature maps
Jan 14, 2020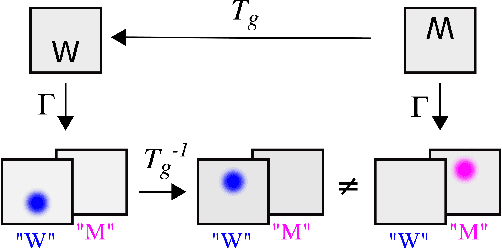



Spatial transformer networks (STNs) were designed to enable CNNs to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image and its original. We present a theoretical argument for this and investigate the practical implications, showing that this inability is coupled with decreased classification accuracy. We advocate taking advantage of more complex features in deeper layers by instead sharing parameters between the classification and the localisation network.
Dynamic texture recognition using time-causal and time-recursive spatio-temporal receptive fields
Jun 21, 2018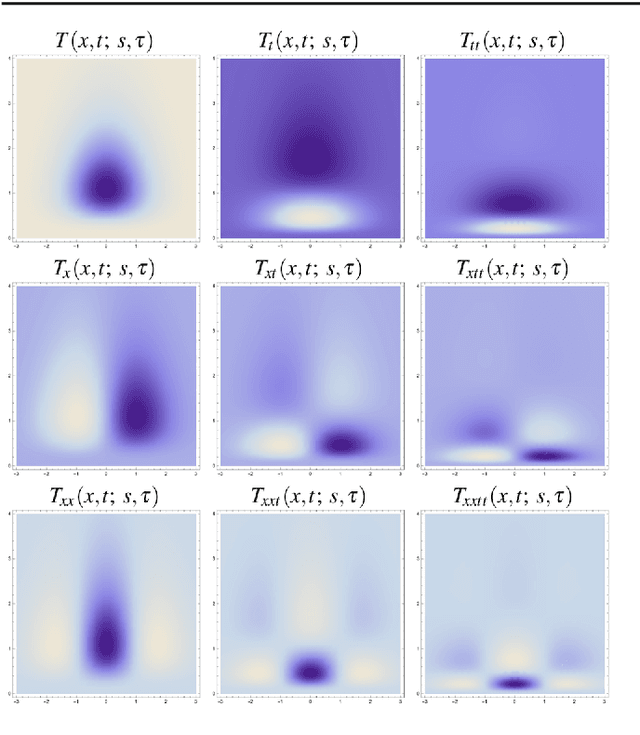

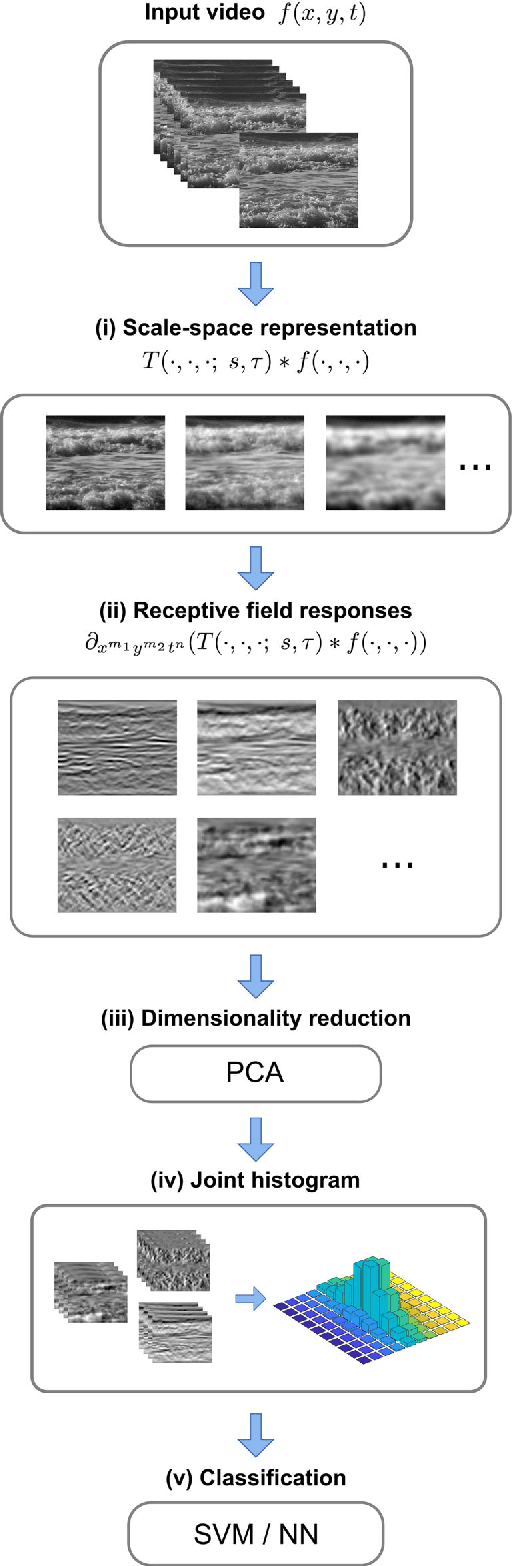
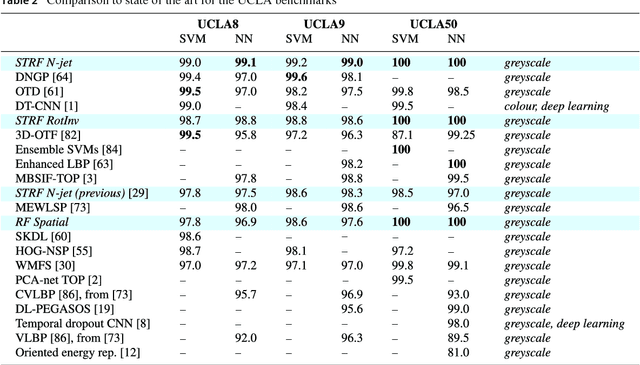
This work presents a first evaluation of using spatio-temporal receptive fields from a recently proposed time-causal spatio-temporal scale-space framework as primitives for video analysis. We propose a new family of video descriptors based on regional statistics of spatio-temporal receptive field responses and evaluate this approach on the problem of dynamic texture recognition. Our approach generalises a previously used method, based on joint histograms of receptive field responses, from the spatial to the spatio-temporal domain and from object recognition to dynamic texture recognition. The time-recursive formulation enables computationally efficient time-causal recognition. The experimental evaluation demonstrates competitive performance compared to state-of-the-art. Especially, it is shown that binary versions of our dynamic texture descriptors achieve improved performance compared to a large range of similar methods using different primitives either handcrafted or learned from data. Further, our qualitative and quantitative investigation into parameter choices and the use of different sets of receptive fields highlights the robustness and flexibility of our approach. Together, these results support the descriptive power of this family of time-causal spatio-temporal receptive fields, validate our approach for dynamic texture recognition and point towards the possibility of designing a range of video analysis methods based on these new time-causal spatio-temporal primitives.
* 29 pages, 16 figures