 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-invariant scale-channel networks: Deep networks that generalise to previously unseen scales
Paper and Code
Jun 11, 2021
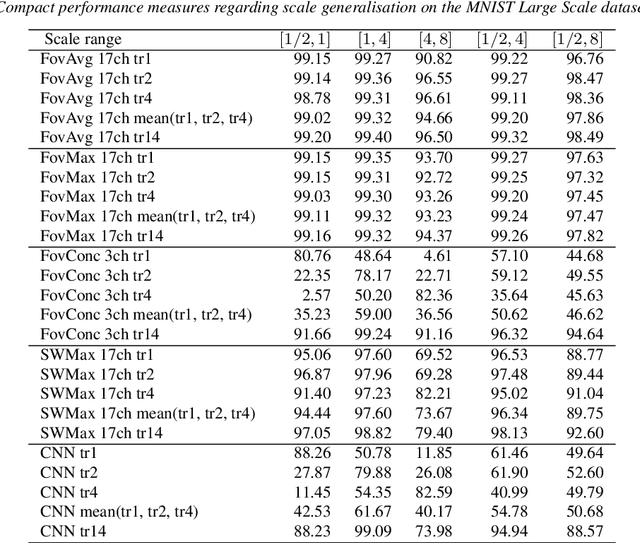
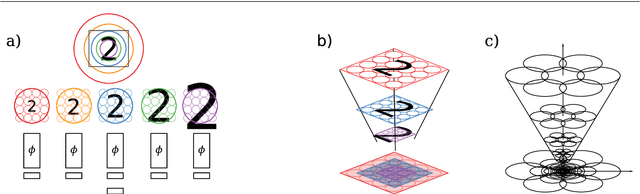

The ability to handle large scale variations is crucial for many real world visual tasks. A straightforward approach for handling scale in a deep network is to process an image at several scales simultaneously in a set of scale channels. Scale invariance can then, in principle, be achieved by using weight sharing between the scale channels together with max or average pooling over the outputs from the scale channels. The ability of such scale channel networks to generalise to scales not present in the training set over significant scale ranges has, however, not previously been explored. In this paper, we present a systematic study of this methodology by implementing different types of scale channel networks and evaluating their ability to generalise to previously unseen scales. We develop a formalism for analysing the covariance and invariance properties of scale channel networks, and explore how different design choices, unique to scaling transformations, affect the overall performance of scale channel networks. We first show that two previously proposed scale channel network designs do not generalise well to scales not present in the training set. We explain theoretically and demonstrate experimentally why generalisation fails in these cases. We then propose a new type of foveated scale channel architecture}, where the scale channels process increasingly larger parts of the image with decreasing resolution. This new type of scale channel network is shown to generalise extremely well, provided sufficient image resolution and the absence of boundary effects. Our proposed FovMax and FovAvg networks perform almost identically over a scale range of 8, also when training on single scale training data, and do also give improved performance when learning from datasets with large scale variations in the small sample regime.