 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe problems with using STNs to align CNN feature maps
Paper and Code
Jan 14, 2020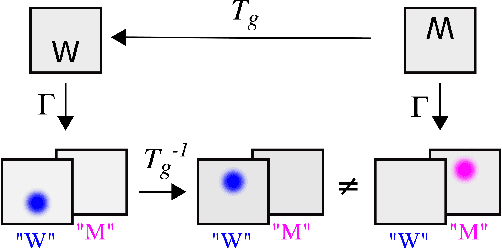



Spatial transformer networks (STNs) were designed to enable CNNs to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image and its original. We present a theoretical argument for this and investigate the practical implications, showing that this inability is coupled with decreased classification accuracy. We advocate taking advantage of more complex features in deeper layers by instead sharing parameters between the classification and the localisation network.