 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding when spatial transformer networks do not support invariance, and what to do about it
Paper and Code
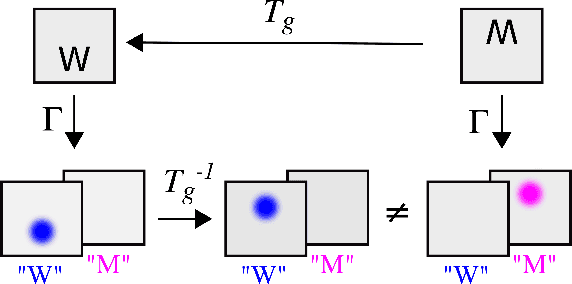
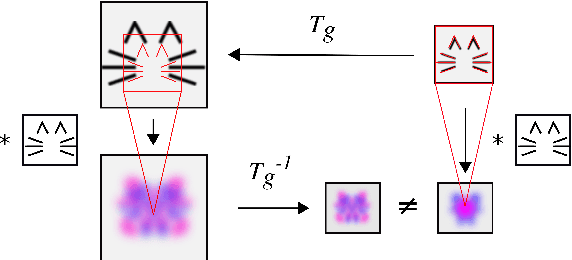
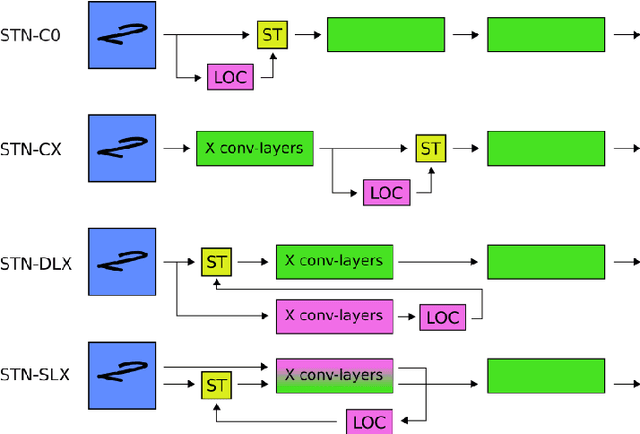
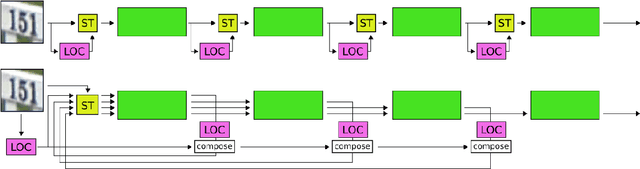
Spatial transformer networks (STNs) were designed to enable convolutional neural networks (CNNs) to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image with those of its original. STNs are therefore unable to support invariance when transforming CNN feature maps. We present a simple proof for this and study the practical implications, showing that this inability is coupled with decreased classification accuracy. We therefore investigate alternative STN architectures that make use of complex features. We find that while deeper localization networks are difficult to train, localization networks that share parameters with the classification network remain stable as they grow deeper, which allows for higher classification accuracy on difficult datasets. Finally, we explore the interaction between localization network complexity and iterative image alignment.