 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInability of spatial transformations of CNN feature maps to support invariant recognition
Paper and Code
Apr 30, 2020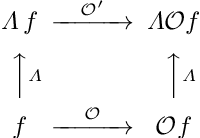
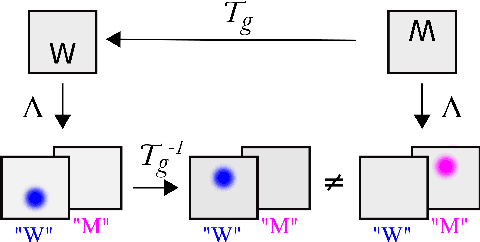
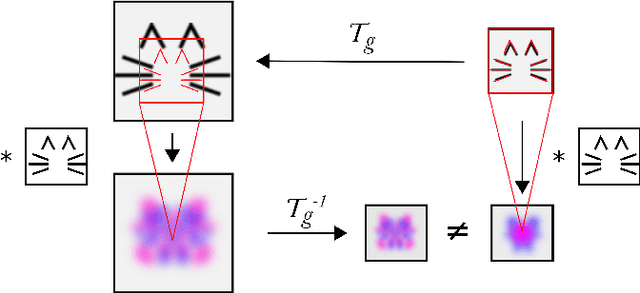
A large number of deep learning architectures use spatial transformations of CNN feature maps or filters to better deal with variability in object appearance caused by natural image transformations. In this paper, we prove that spatial transformations of CNN feature maps cannot align the feature maps of a transformed image to match those of its original, for general affine transformations, unless the extracted features are themselves invariant. Our proof is based on elementary analysis for both the single- and multi-layer network case. The results imply that methods based on spatial transformations of CNN feature maps or filters cannot replace image alignment of the input and cannot enable invariant recognition for general affine transformations, specifically not for scaling transformations or shear transformations. For rotations and reflections, spatially transforming feature maps or filters can enable invariance but only for networks with learnt or hardcoded rotation- or reflection-invariant features