 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Measuring the Representation of Subjective Global Opinions in Language Models
Jun 28, 2023

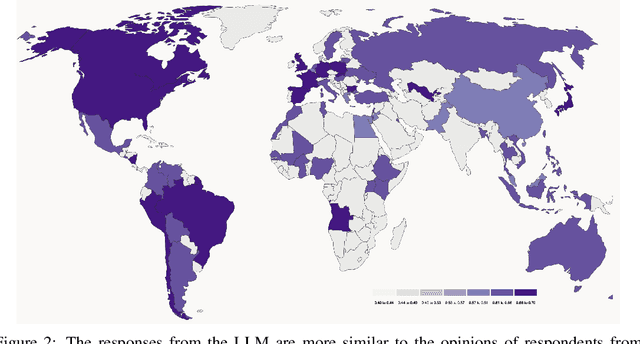

Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
Oct 11, 2022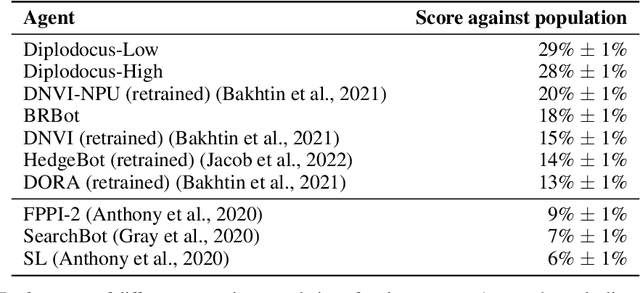

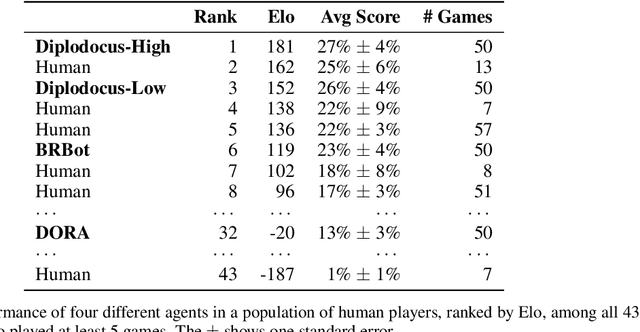
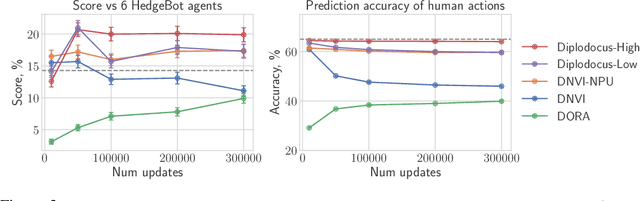
No-press Diplomacy is a complex strategy game involving both cooperation and competition that has served as a benchmark for multi-agent AI research. While self-play reinforcement learning has resulted in numerous successes in purely adversarial games like chess, Go, and poker, self-play alone is insufficient for achieving optimal performance in domains involving cooperation with humans. We address this shortcoming by first introducing a planning algorithm we call DiL-piKL that regularizes a reward-maximizing policy toward a human imitation-learned policy. We prove that this is a no-regret learning algorithm under a modified utility function. We then show that DiL-piKL can be extended into a self-play reinforcement learning algorithm we call RL-DiL-piKL that provides a model of human play while simultaneously training an agent that responds well to this human model. We used RL-DiL-piKL to train an agent we name Diplodocus. In a 200-game no-press Diplomacy tournament involving 62 human participants spanning skill levels from beginner to expert, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo ratings model.
Modeling Strong and Human-Like Gameplay with KL-Regularized Search
Dec 14, 2021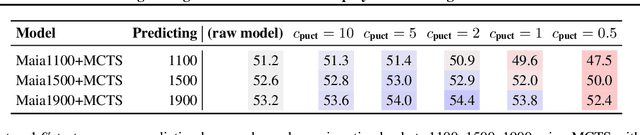
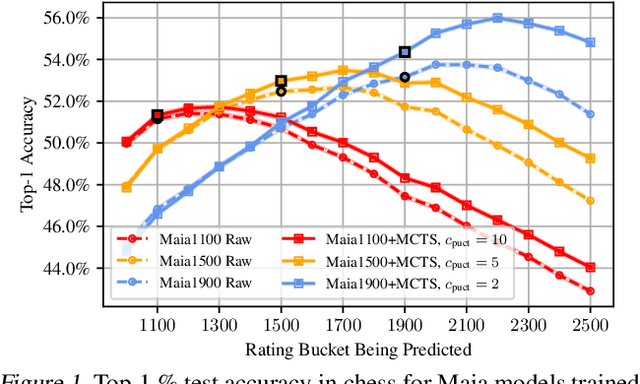

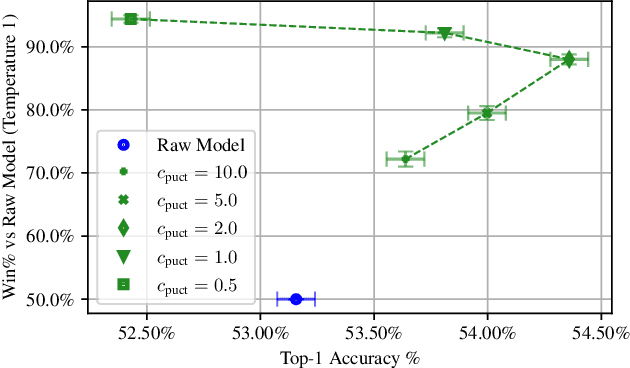
We consider the task of building strong but human-like policies in multi-agent decision-making problems, given examples of human behavior. Imitation learning is effective at predicting human actions but may not match the strength of expert humans, while self-play learning and search techniques (e.g. AlphaZero) lead to strong performance but may produce policies that are difficult for humans to understand and coordinate with. We show in chess and Go that regularizing search policies based on the KL divergence from an imitation-learned policy by applying Monte Carlo tree search produces policies that have higher human prediction accuracy and are stronger than the imitation policy. We then introduce a novel regret minimization algorithm that is regularized based on the KL divergence from an imitation-learned policy, and show that applying this algorithm to no-press Diplomacy yields a policy that maintains the same human prediction accuracy as imitation learning while being substantially stronger.
No-Press Diplomacy from Scratch
Oct 06, 2021


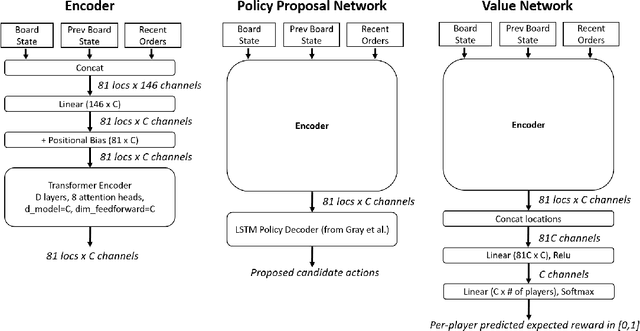
Prior AI successes in complex games have largely focused on settings with at most hundreds of actions at each decision point. In contrast, Diplomacy is a game with more than 10^20 possible actions per turn. Previous attempts to address games with large branching factors, such as Diplomacy, StarCraft, and Dota, used human data to bootstrap the policy or used handcrafted reward shaping. In this paper, we describe an algorithm for action exploration and equilibrium approximation in games with combinatorial action spaces. This algorithm simultaneously performs value iteration while learning a policy proposal network. A double oracle step is used to explore additional actions to add to the policy proposals. At each state, the target state value and policy for the model training are computed via an equilibrium search procedure. Using this algorithm, we train an agent, DORA, completely from scratch for a popular two-player variant of Diplomacy and show that it achieves superhuman performance. Additionally, we extend our methods to full-scale no-press Diplomacy and for the first time train an agent from scratch with no human data. We present evidence that this agent plays a strategy that is incompatible with human-data bootstrapped agents. This presents the first strong evidence of multiple equilibria in Diplomacy and suggests that self play alone may be insufficient for achieving superhuman performance in Diplomacy.
Physical Reasoning Using Dynamics-Aware Models
Feb 20, 2021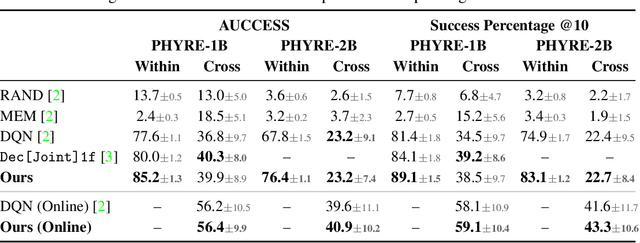
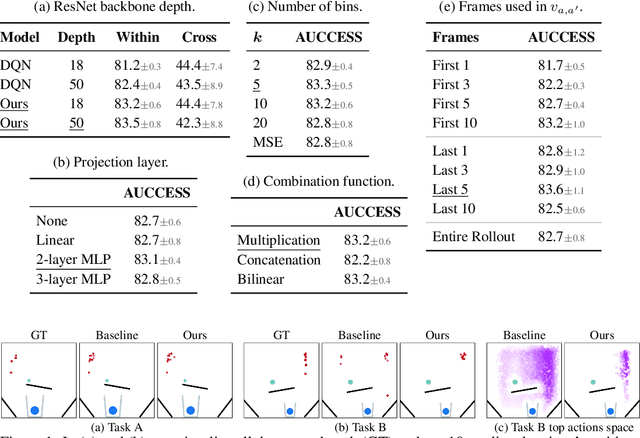
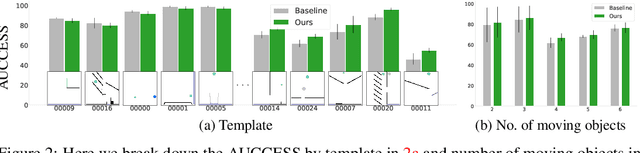
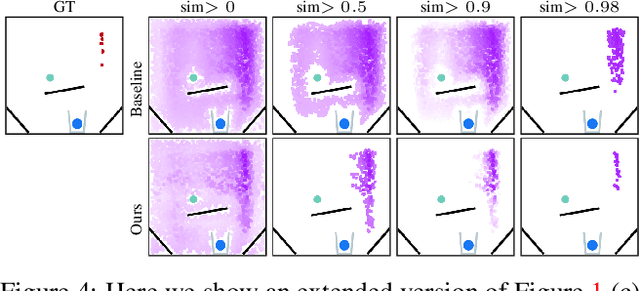
A common approach to solving physical-reasoning tasks is to train a value learner on example tasks. A limitation of such an approach is it requires learning about object dynamics solely from reward values assigned to the final state of a rollout of the environment. This study aims to address this limitation by augmenting the reward value with additional supervisory signals about object dynamics. Specifically,we define a distance measure between the trajectory of two target objects, and use this distance measure to characterize the similarity of two environment rollouts.We train the model to correctly rank rollouts according to this measure in addition to predicting the correct reward. Empirically, we find that this approach leads to substantial performance improvements on the PHYRE benchmark for physical reasoning: our approach obtains a new state-of-the-art on that benchmark.
Human-Level Performance in No-Press Diplomacy via Equilibrium Search
Oct 06, 2020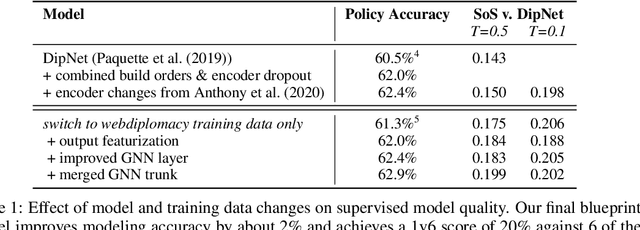
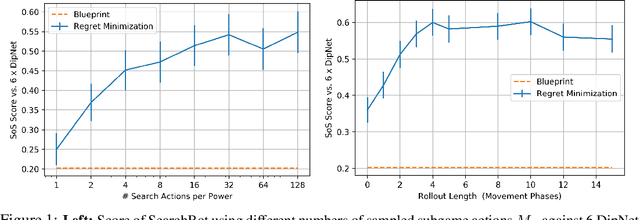

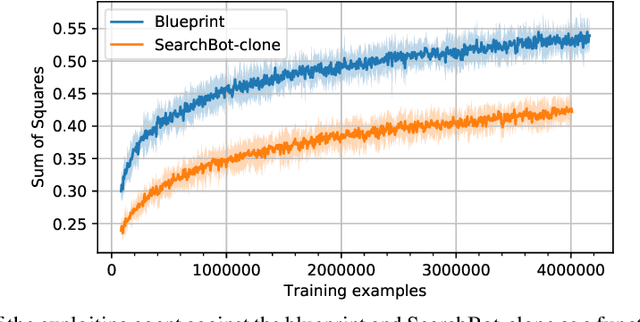
Prior AI breakthroughs in complex games have focused on either the purely adversarial or purely cooperative settings. In contrast, Diplomacy is a game of shifting alliances that involves both cooperation and competition. For this reason, Diplomacy has proven to be a formidable research challenge. In this paper we describe an agent for the no-press variant of Diplomacy that combines supervised learning on human data with one-step lookahead search via external regret minimization. External regret minimization techniques have been behind previous AI successes in adversarial games, most notably poker, but have not previously been shown to be successful in large-scale games involving cooperation. We show that our agent greatly exceeds the performance of past no-press Diplomacy bots, is unexploitable by expert humans, and achieves a rank of 23 out of 1,128 human players when playing anonymous games on a popular Diplomacy website.
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
Jul 27, 2020
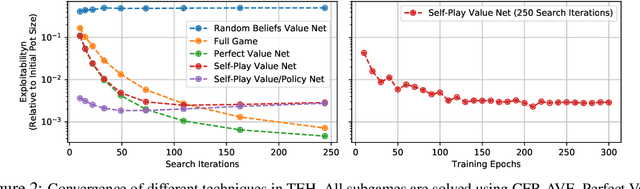
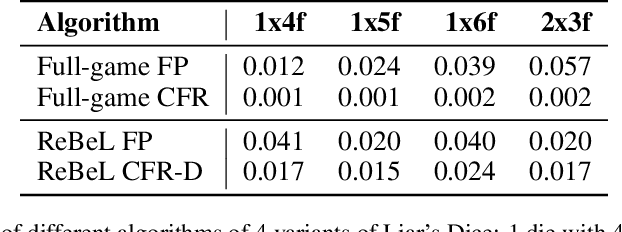
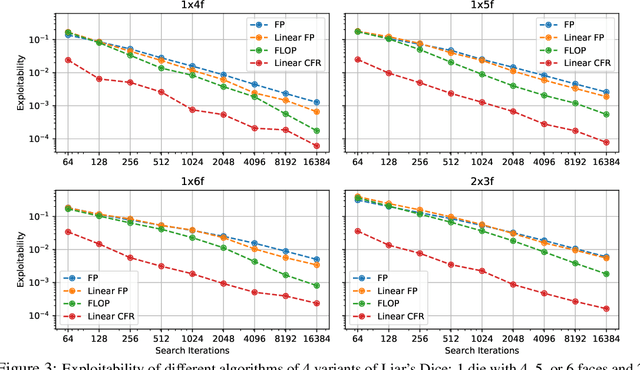
The combination of deep reinforcement learning and search at both training and test time is a powerful paradigm that has led to a number of a successes in single-agent settings and perfect-information games, best exemplified by the success of AlphaZero. However, algorithms of this form have been unable to cope with imperfect-information games. This paper presents ReBeL, a general framework for self-play reinforcement learning and search for imperfect-information games. In the simpler setting of perfect-information games, ReBeL reduces to an algorithm similar to AlphaZero. Results show ReBeL leads to low exploitability in benchmark imperfect-information games and achieves superhuman performance in heads-up no-limit Texas hold'em poker, while using far less domain knowledge than any prior poker AI. We also prove that ReBeL converges to a Nash equilibrium in two-player zero-sum games in tabular settings.
Residual Energy-Based Models for Text Generation
Apr 22, 2020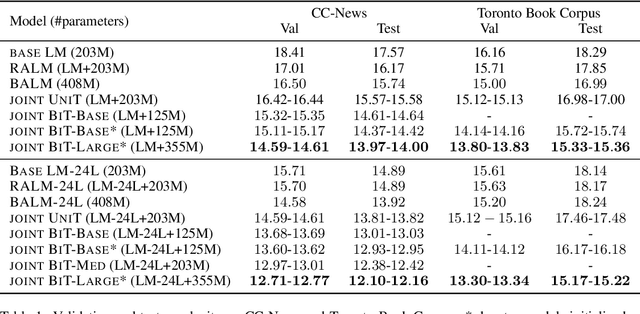

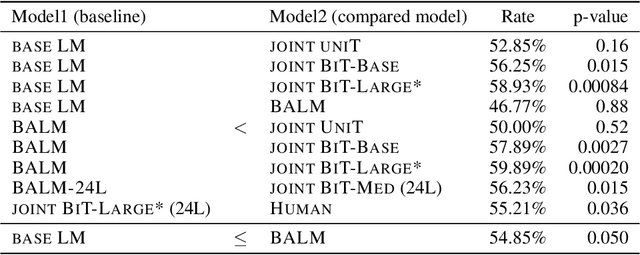
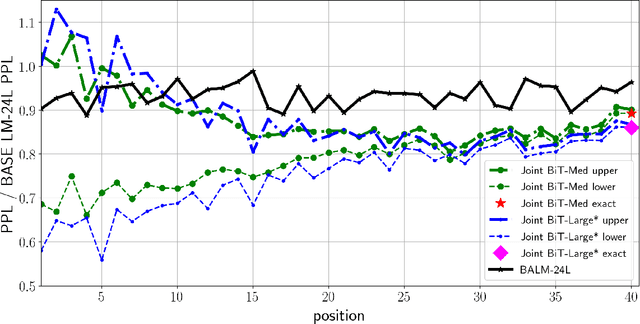
Text generation is ubiquitous in many NLP tasks, from summarization, to dialogue and machine translation. The dominant parametric approach is based on locally normalized models which predict one word at a time. While these work remarkably well, they are plagued by exposure bias due to the greedy nature of the generation process. In this work, we investigate un-normalized energy-based models (EBMs) which operate not at the token but at the sequence level. In order to make training tractable, we first work in the residual of a pretrained locally normalized language model and second we train using noise contrastive estimation. Furthermore, since the EBM works at the sequence level, we can leverage pretrained bi-directional contextual representations, such as BERT and RoBERTa. Our experiments on two large language modeling datasets show that residual EBMs yield lower perplexity compared to locally normalized baselines. Moreover, generation via importance sampling is very efficient and of higher quality than the baseline models according to human evaluation.
* published at ICLR 2020. arXiv admin note: substantial text overlap with arXiv:2004.10188
Energy-Based Models for Text
Apr 06, 2020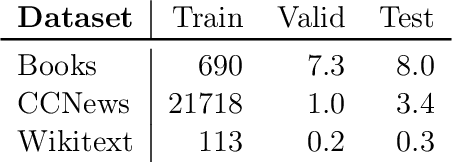

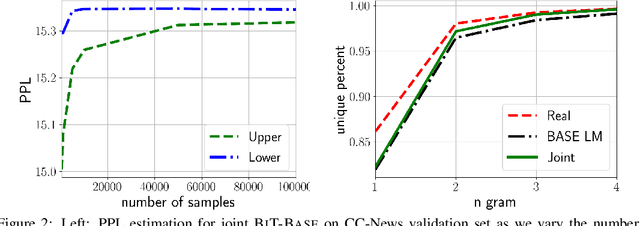
Current large-scale auto-regressive language models display impressive fluency and can generate convincing text. In this work we start by asking the question: Can the generations of these models be reliably distinguished from real text by statistical discriminators? We find experimentally that the answer is affirmative when we have access to the training data for the model, and guardedly affirmative even if we do not. This suggests that the auto-regressive models can be improved by incorporating the (globally normalized) discriminators into the generative process. We give a formalism for this using the Energy-Based Model framework, and show that it indeed improves the results of the generative models, measured both in terms of perplexity and in terms of human evaluation.
Language Models as Knowledge Bases?
Sep 04, 2019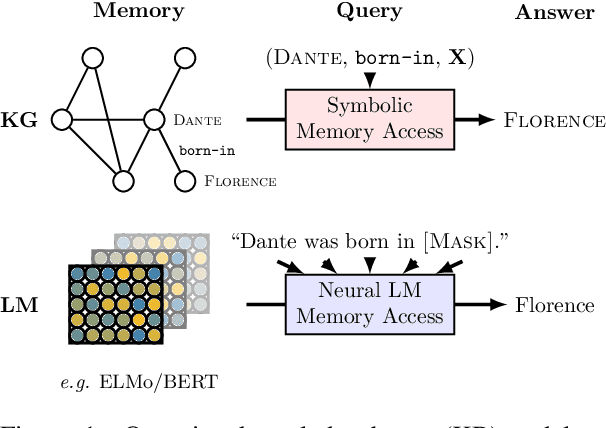
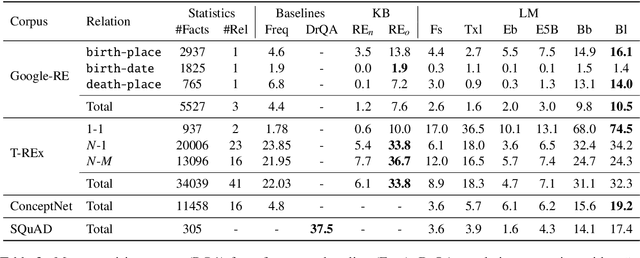
Recent progress in pretraining language models on large textual corpora led to a surge of improvements for downstream NLP tasks. Whilst learning linguistic knowledge, these models may also be storing relational knowledge present in the training data, and may be able to answer queries structured as "fill-in-the-blank" cloze statements. Language models have many advantages over structured knowledge bases: they require no schema engineering, allow practitioners to query about an open class of relations, are easy to extend to more data, and require no human supervision to train. We present an in-depth analysis of the relational knowledge already present (without fine-tuning) in a wide range of state-of-the-art pretrained language models. We find that (i) without fine-tuning, BERT contains relational knowledge competitive with traditional NLP methods that have some access to oracle knowledge, (ii) BERT also does remarkably well on open-domain question answering against a supervised baseline, and (iii) certain types of factual knowledge are learned much more readily than others by standard language model pretraining approaches. The surprisingly strong ability of these models to recall factual knowledge without any fine-tuning demonstrates their potential as unsupervised open-domain QA systems. The code to reproduce our analysis is available at https://github.com/facebookresearch/LAMA.