 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Press Diplomacy from Scratch
Paper and Code
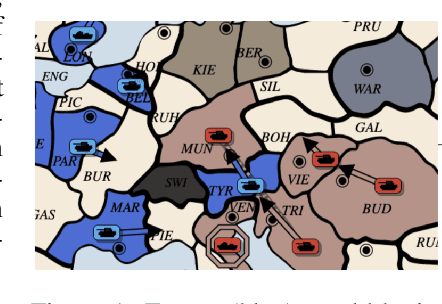


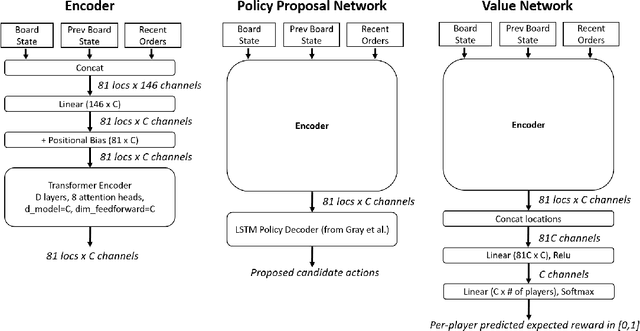
Prior AI successes in complex games have largely focused on settings with at most hundreds of actions at each decision point. In contrast, Diplomacy is a game with more than 10^20 possible actions per turn. Previous attempts to address games with large branching factors, such as Diplomacy, StarCraft, and Dota, used human data to bootstrap the policy or used handcrafted reward shaping. In this paper, we describe an algorithm for action exploration and equilibrium approximation in games with combinatorial action spaces. This algorithm simultaneously performs value iteration while learning a policy proposal network. A double oracle step is used to explore additional actions to add to the policy proposals. At each state, the target state value and policy for the model training are computed via an equilibrium search procedure. Using this algorithm, we train an agent, DORA, completely from scratch for a popular two-player variant of Diplomacy and show that it achieves superhuman performance. Additionally, we extend our methods to full-scale no-press Diplomacy and for the first time train an agent from scratch with no human data. We present evidence that this agent plays a strategy that is incompatible with human-data bootstrapped agents. This presents the first strong evidence of multiple equilibria in Diplomacy and suggests that self play alone may be insufficient for achieving superhuman performance in Diplomacy.