 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does the AI Doctor Value? Auditing Pluralism in the Clinical Ethics of Language Models
May 18, 2026Medicine is inherently pluralistic. Principles such as autonomy, beneficence, nonmaleficence, and justice routinely conflict, and such ethical dilemmas often sharply divide reasonable physicians. Good clinical practice navigates these tensions in concert with each patient's values rather than imposing a single ethical stance. The ethical values that large language models bring to medical advice, however, have not been systematically examined. We present a framework for auditing value pluralism in medical AI, comprising a benchmark of clinician-verified dilemmas and an attribution method that recovers value priorities directly from decisions. The ecosystem of frontier models spans physician-level value heterogeneity, and models discuss competing values in their reasoning (Overton pluralism) before committing to a decision. However, individual model decisions are near-deterministic across repeated sampling and semantic variations, failing to reproduce the distributional pluralism of the physician panel. Across benchmark cases, these consistent decisions reflect committed, systematic value preferences. While most model priorities fall within the natural range of inter-physician variation, some significantly underweight patient autonomy. A single LLM deployed without regard for its value priorities could amplify those priorities at scale to every patient it serves. Without explicit efforts to balance ethical perspectives with one or multiple models, these tools risk replacing clinical pluralism with a deployment monoculture.
Scalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
Apr 21, 2025



Mixture of Experts (MoE) models enhance neural network scalability by dynamically selecting relevant experts per input token, enabling larger model sizes while maintaining manageable computation costs. However, efficient training of large-scale MoE models across thousands of GPUs presents significant challenges due to limitations in existing parallelism strategies. We introduce an end-to-end training framework for large-scale MoE models that utilizes five-dimensional hybrid parallelism: Tensor Parallelism, Expert Parallelism, Context Parallelism, Data Parallelism, and Pipeline Parallelism. Central to our approach is MoE Parallel Folding, a novel strategy that decouples the parallelization of attention and MoE layers in Transformer models, allowing each layer type to adopt optimal parallel configurations. Additionally, we develop a flexible token-level dispatcher that supports both token-dropping and token-dropless MoE training across all five dimensions of parallelism. This dispatcher accommodates dynamic tensor shapes and coordinates different parallelism schemes for Attention and MoE layers, facilitating complex parallelism implementations. Our experiments demonstrate significant improvements in training efficiency and scalability. We achieve up to 49.3% Model Flops Utilization (MFU) for the Mixtral 8x22B model and 39.0% MFU for the Qwen2-57B-A14B model on H100 GPUs, outperforming existing methods. The framework scales efficiently up to 1,024 GPUs and maintains high performance with sequence lengths up to 128K tokens, validating its effectiveness for large-scale MoE model training. The code is available in Megatron-Core.
Aligning LLMs with Domain Invariant Reward Models
Jan 01, 2025Aligning large language models (LLMs) to human preferences is challenging in domains where preference data is unavailable. We address the problem of learning reward models for such target domains by leveraging feedback collected from simpler source domains, where human preferences are easier to obtain. Our key insight is that, while domains may differ significantly, human preferences convey \emph{domain-agnostic} concepts that can be effectively captured by a reward model. We propose \method, a framework that trains domain-invariant reward models by optimizing a dual loss: a domain loss that minimizes the divergence between source and target distribution, and a source loss that optimizes preferences on the source domain. We show \method is a general approach that we evaluate and analyze across 4 distinct settings: (1) Cross-lingual transfer (accuracy: $0.621 \rightarrow 0.661$), (2) Clean-to-noisy (accuracy: $0.671 \rightarrow 0.703$), (3) Few-shot-to-full transfer (accuracy: $0.845 \rightarrow 0.920$), and (4) Simple-to-complex tasks transfer (correlation: $0.508 \rightarrow 0.556$). Our code, models and data are available at \url{https://github.com/portal-cornell/dial}.
Beyond Label Attention: Transparency in Language Models for Automated Medical Coding via Dictionary Learning
Oct 31, 2024



Medical coding, the translation of unstructured clinical text into standardized medical codes, is a crucial but time-consuming healthcare practice. Though large language models (LLM) could automate the coding process and improve the efficiency of such tasks, interpretability remains paramount for maintaining patient trust. Current efforts in interpretability of medical coding applications rely heavily on label attention mechanisms, which often leads to the highlighting of extraneous tokens irrelevant to the ICD code. To facilitate accurate interpretability in medical language models, this paper leverages dictionary learning that can efficiently extract sparsely activated representations from dense language model embeddings in superposition. Compared with common label attention mechanisms, our model goes beyond token-level representations by building an interpretable dictionary which enhances the mechanistic-based explanations for each ICD code prediction, even when the highlighted tokens are medically irrelevant. We show that dictionary features can steer model behavior, elucidate the hidden meanings of upwards of 90% of medically irrelevant tokens, and are human interpretable.
DILA: Dictionary Label Attention for Mechanistic Interpretability in High-dimensional Multi-label Medical Coding Prediction
Sep 16, 2024



Predicting high-dimensional or extreme multilabels, such as in medical coding, requires both accuracy and interpretability. Existing works often rely on local interpretability methods, failing to provide comprehensive explanations of the overall mechanism behind each label prediction within a multilabel set. We propose a mechanistic interpretability module called DIctionary Label Attention (\method) that disentangles uninterpretable dense embeddings into a sparse embedding space, where each nonzero element (a dictionary feature) represents a globally learned medical concept. Through human evaluations, we show that our sparse embeddings are more human understandable than its dense counterparts by at least 50 percent. Our automated dictionary feature identification pipeline, leveraging large language models (LLMs), uncovers thousands of learned medical concepts by examining and summarizing the highest activating tokens for each dictionary feature. We represent the relationships between dictionary features and medical codes through a sparse interpretable matrix, enhancing the mechanistic and global understanding of the model's predictions while maintaining competitive performance and scalability without extensive human annotation.
The Virtues of Pessimism in Inverse Reinforcement Learning
Feb 08, 2024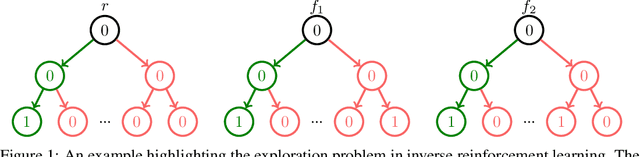

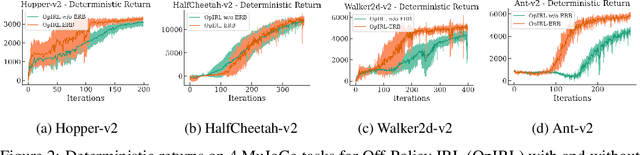
Inverse Reinforcement Learning (IRL) is a powerful framework for learning complex behaviors from expert demonstrations. However, it traditionally requires repeatedly solving a computationally expensive reinforcement learning (RL) problem in its inner loop. It is desirable to reduce the exploration burden by leveraging expert demonstrations in the inner-loop RL. As an example, recent work resets the learner to expert states in order to inform the learner of high-reward expert states. However, such an approach is infeasible in the real world. In this work, we consider an alternative approach to speeding up the RL subroutine in IRL: \emph{pessimism}, i.e., staying close to the expert's data distribution, instantiated via the use of offline RL algorithms. We formalize a connection between offline RL and IRL, enabling us to use an arbitrary offline RL algorithm to improve the sample efficiency of IRL. We validate our theory experimentally by demonstrating a strong correlation between the efficacy of an offline RL algorithm and how well it works as part of an IRL procedure. By using a strong offline RL algorithm as part of an IRL procedure, we are able to find policies that match expert performance significantly more efficiently than the prior art.
Accelerating Inverse Reinforcement Learning with Expert Bootstrapping
Feb 04, 2024Existing inverse reinforcement learning methods (e.g. MaxEntIRL, $f$-IRL) search over candidate reward functions and solve a reinforcement learning problem in the inner loop. This creates a rather strange inversion where a harder problem, reinforcement learning, is in the inner loop of a presumably easier problem, imitation learning. In this work, we show that better utilization of expert demonstrations can reduce the need for hard exploration in the inner RL loop, hence accelerating learning. Specifically, we propose two simple recipes: (1) placing expert transitions into the replay buffer of the inner RL algorithm (e.g. Soft-Actor Critic) which directly informs the learner about high reward states instead of forcing the learner to discover them through extensive exploration, and (2) using expert actions in Q value bootstrapping in order to improve the target Q value estimates and more accurately describe high value expert states. Our methods show significant gains over a MaxEntIRL baseline on the benchmark MuJoCo suite of tasks, speeding up recovery to 70\% of deterministic expert performance by 2.13x on HalfCheetah-v2, 2.6x on Ant-v2, 18x on Hopper-v2, and 3.36x on Walker2d-v2.
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023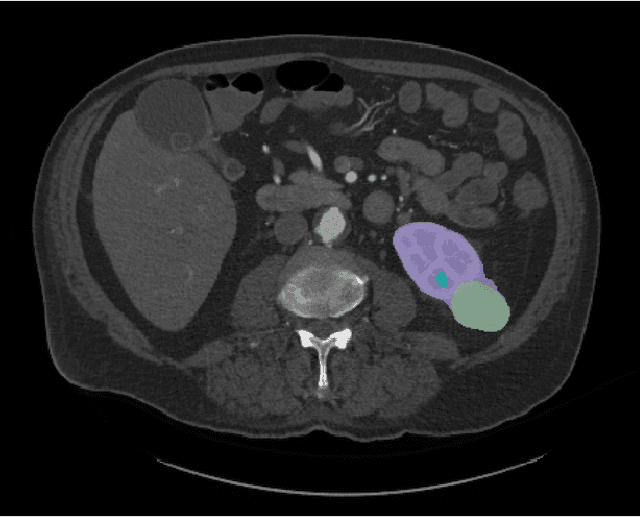
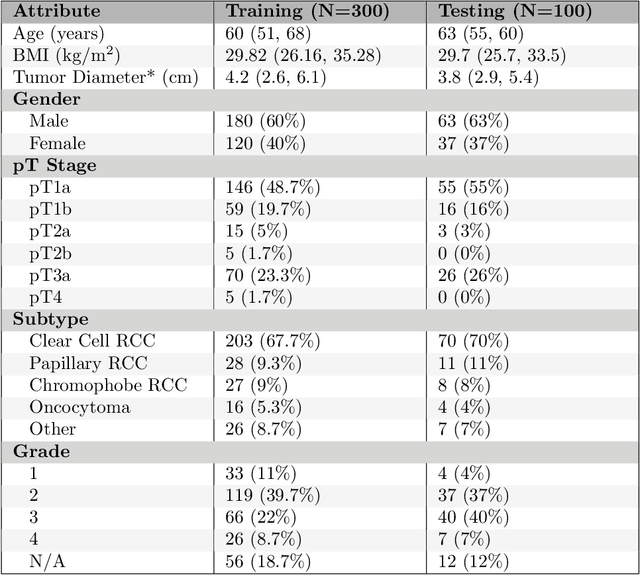
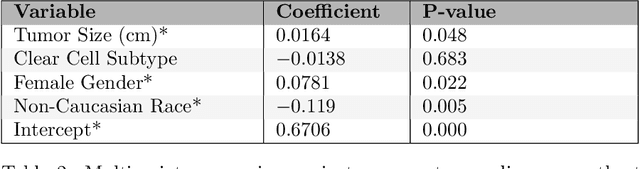
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
CryptOpt: Automatic Optimization of Straightline Code
May 31, 2023



Manual engineering of high-performance implementations typically consumes many resources and requires in-depth knowledge of the hardware. Compilers try to address these problems; however, they are limited by design in what they can do. To address this, we present CryptOpt, an automatic optimizer for long stretches of straightline code. Experimental results across eight hardware platforms show that CryptOpt achieves a speed-up factor of up to 2.56 over current off-the-shelf compilers.