 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of States: Solving Abductive Tasks with Large Language Models
Mar 22, 2026Logical reasoning encompasses deduction, induction, and abduction. However, while Large Language Models (LLMs) have effectively mastered the former two, abductive reasoning remains significantly underexplored. Existing frameworks, predominantly designed for static deductive tasks, fail to generalize to abductive reasoning due to unstructured state representation and lack of explicit state control. Consequently, they are inevitably prone to Evidence Fabrication, Context Drift, Failed Backtracking, and Early Stopping. To bridge this gap, we introduce Graph of States (GoS), a general-purpose neuro-symbolic framework tailored for abductive tasks. GoS grounds multi-agent collaboration in a structured belief states, utilizing a causal graph to explicitly encode logical dependencies and a state machine to govern the valid transitions of the reasoning process. By dynamically aligning the reasoning focus with these symbolic constraints, our approach transforms aimless, unconstrained exploration into a convergent, directed search. Extensive evaluations on two real-world datasets demonstrate that GoS significantly outperforms all baselines, providing a robust solution for complex abductive tasks. Code repo and all prompts: https://anonymous.4open.science/r/Graph-of-States-5B4E.
Scalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
Multi-Agent Learning Path Planning via LLMs
Jan 24, 2026The integration of large language models (LLMs) into intelligent tutoring systems offers transformative potential for personalized learning in higher education. However, most existing learning path planning approaches lack transparency, adaptability, and learner-centered explainability. To address these challenges, this study proposes a novel Multi-Agent Learning Path Planning (MALPP) framework that leverages a role- and rule-based collaboration mechanism among intelligent agents, each powered by LLMs. The framework includes three task-specific agents: a learner analytics agent, a path planning agent, and a reflection agent. These agents collaborate via structured prompts and predefined rules to analyze learning profiles, generate tailored learning paths, and iteratively refine them with interpretable feedback. Grounded in Cognitive Load Theory and Zone of Proximal Development, the system ensures that recommended paths are cognitively aligned and pedagogically meaningful. Experiments conducted on the MOOCCubeX dataset using seven LLMs show that MALPP significantly outperforms baseline models in path quality, knowledge sequence consistency, and cognitive load alignment. Ablation studies further validate the effectiveness of the collaborative mechanism and theoretical constraints. This research contributes to the development of trustworthy, explainable AI in education and demonstrates a scalable approach to learner-centered adaptive instruction powered by LLMs.
SMEC: Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression
Oct 14, 2025Large language models (LLMs) generate high-dimensional embeddings that capture rich semantic and syntactic information. However, high-dimensional embeddings exacerbate computational complexity and storage requirements, thereby hindering practical deployment. To address these challenges, we propose a novel training framework named Sequential Matryoshka Embedding Compression (SMEC). This framework introduces the Sequential Matryoshka Representation Learning(SMRL) method to mitigate gradient variance during training, the Adaptive Dimension Selection (ADS) module to reduce information degradation during dimension pruning, and the Selectable Cross-batch Memory (S-XBM) module to enhance unsupervised learning between high- and low-dimensional embeddings. Experiments on image, text, and multimodal datasets demonstrate that SMEC achieves significant dimensionality reduction while maintaining performance. For instance, on the BEIR dataset, our approach improves the performance of compressed LLM2Vec embeddings (256 dimensions) by 1.1 points and 2.7 points compared to the Matryoshka-Adaptor and Search-Adaptor models, respectively.
EEGDM: Learning EEG Representation with Latent Diffusion Model
Aug 28, 2025While electroencephalography (EEG) signal analysis using deep learning has shown great promise, existing approaches still face significant challenges in learning generalizable representations that perform well across diverse tasks, particularly when training data is limited. Current EEG representation learning methods including EEGPT and LaBraM typically rely on simple masked reconstruction objective, which may not fully capture the rich semantic information and complex patterns inherent in EEG signals. In this paper, we propose EEGDM, a novel self-supervised EEG representation learning method based on the latent diffusion model, which leverages EEG signal generation as a self-supervised objective, turning the diffusion model into a strong representation learner capable of capturing EEG semantics. EEGDM incorporates an EEG encoder that distills EEG signals and their channel augmentations into a compact representation, acting as conditional information to guide the diffusion model for generating EEG signals. This design endows EEGDM with a compact latent space, which not only offers ample control over the generative process but also can be leveraged for downstream tasks. Experimental results show that EEGDM (1) can reconstruct high-quality EEG signals, (2) effectively learns robust representations, and (3) achieves competitive performance with modest pre-training data size across diverse downstream tasks, underscoring its generalizability and practical utility.
USD: A User-Intent-Driven Sampling and Dual-Debiasing Framework for Large-Scale Homepage Recommendations
Jul 09, 2025

Large-scale homepage recommendations face critical challenges from pseudo-negative samples caused by exposure bias, where non-clicks may indicate inattention rather than disinterest. Existing work lacks thorough analysis of invalid exposures and typically addresses isolated aspects (e.g., sampling strategies), overlooking the critical impact of pseudo-positive samples - such as homepage clicks merely to visit marketing portals. We propose a unified framework for large-scale homepage recommendation sampling and debiasing. Our framework consists of two key components: (1) a user intent-aware negative sampling module to filter invalid exposure samples, and (2) an intent-driven dual-debiasing module that jointly corrects exposure bias and click bias. Extensive online experiments on Taobao demonstrate the efficacy of our framework, achieving significant improvements in user click-through rates (UCTR) by 35.4\% and 14.5\% in two variants of the marketing block on the Taobao homepage, Baiyibutie and Taobaomiaosha.
Distributional Soft Actor-Critic with Diffusion Policy
Jul 02, 2025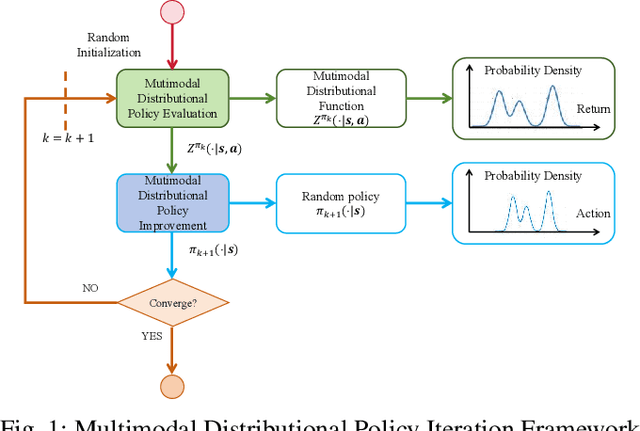
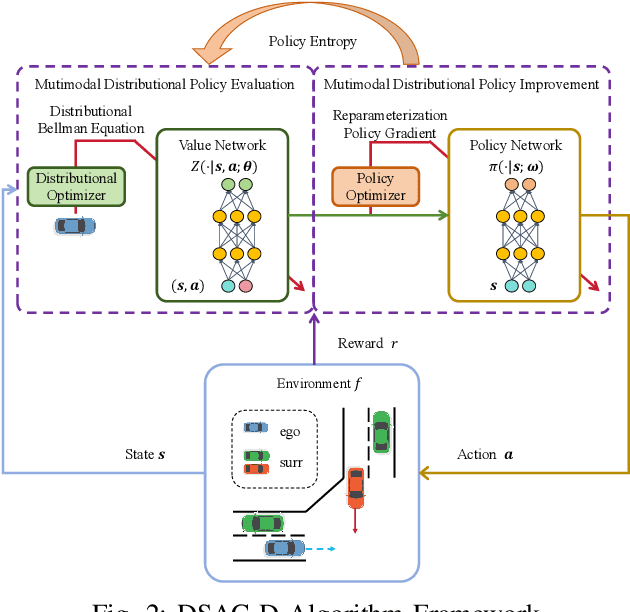

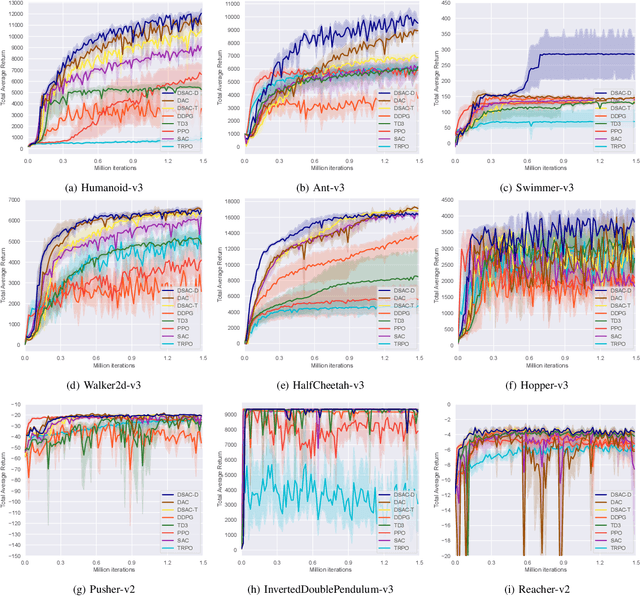
Reinforcement learning has been proven to be highly effective in handling complex control tasks. Traditional methods typically use unimodal distributions, such as Gaussian distributions, to model the output of value distributions. However, unimodal distribution often and easily causes bias in value function estimation, leading to poor algorithm performance. This paper proposes a distributional reinforcement learning algorithm called DSAC-D (Distributed Soft Actor Critic with Diffusion Policy) to address the challenges of estimating bias in value functions and obtaining multimodal policy representations. A multimodal distributional policy iteration framework that can converge to the optimal policy was established by introducing policy entropy and value distribution function. A diffusion value network that can accurately characterize the distribution of multi peaks was constructed by generating a set of reward samples through reverse sampling using a diffusion model. Based on this, a distributional reinforcement learning algorithm with dual diffusion of the value network and the policy network was derived. MuJoCo testing tasks demonstrate that the proposed algorithm not only learns multimodal policy, but also achieves state-of-the-art (SOTA) performance in all 9 control tasks, with significant suppression of estimation bias and total average return improvement of over 10\% compared to existing mainstream algorithms. The results of real vehicle testing show that DSAC-D can accurately characterize the multimodal distribution of different driving styles, and the diffusion policy network can characterize multimodal trajectories.
Does Machine Unlearning Truly Remove Model Knowledge? A Framework for Auditing Unlearning in LLMs
May 29, 2025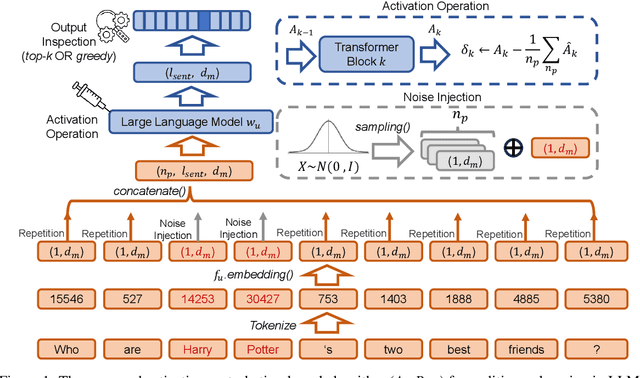
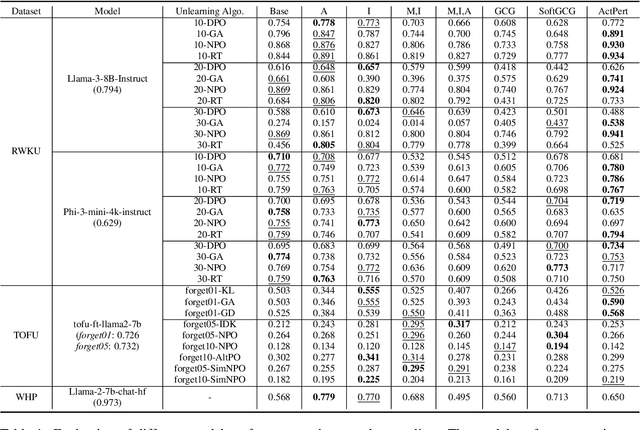
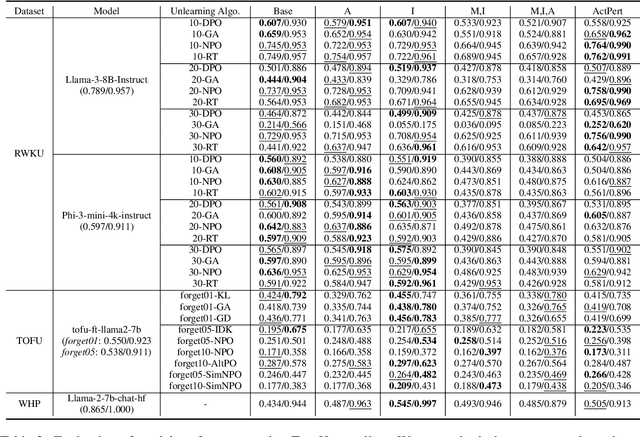
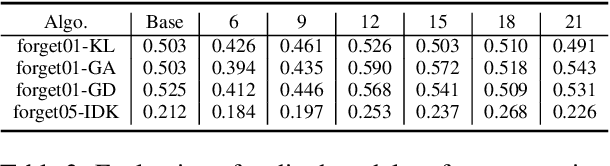
In recent years, Large Language Models (LLMs) have achieved remarkable advancements, drawing significant attention from the research community. Their capabilities are largely attributed to large-scale architectures, which require extensive training on massive datasets. However, such datasets often contain sensitive or copyrighted content sourced from the public internet, raising concerns about data privacy and ownership. Regulatory frameworks, such as the General Data Protection Regulation (GDPR), grant individuals the right to request the removal of such sensitive information. This has motivated the development of machine unlearning algorithms that aim to remove specific knowledge from models without the need for costly retraining. Despite these advancements, evaluating the efficacy of unlearning algorithms remains a challenge due to the inherent complexity and generative nature of LLMs. In this work, we introduce a comprehensive auditing framework for unlearning evaluation, comprising three benchmark datasets, six unlearning algorithms, and five prompt-based auditing methods. By using various auditing algorithms, we evaluate the effectiveness and robustness of different unlearning strategies. To explore alternatives beyond prompt-based auditing, we propose a novel technique that leverages intermediate activation perturbations, addressing the limitations of auditing methods that rely solely on model inputs and outputs.
Enhanced DACER Algorithm with High Diffusion Efficiency
May 29, 2025Due to their expressive capacity, diffusion models have shown great promise in offline RL and imitation learning. Diffusion Actor-Critic with Entropy Regulator (DACER) extended this capability to online RL by using the reverse diffusion process as a policy approximator, trained end-to-end with policy gradient methods, achieving strong performance. However, this comes at the cost of requiring many diffusion steps, which significantly hampers training efficiency, while directly reducing the steps leads to noticeable performance degradation. Critically, the lack of inference efficiency becomes a significant bottleneck for applying diffusion policies in real-time online RL settings. To improve training and inference efficiency while maintaining or even enhancing performance, we propose a Q-gradient field objective as an auxiliary optimization target to guide the denoising process at each diffusion step. Nonetheless, we observe that the independence of the Q-gradient field from the diffusion time step negatively impacts the performance of the diffusion policy. To address this, we introduce a temporal weighting mechanism that enables the model to efficiently eliminate large-scale noise in the early stages and refine actions in the later stages. Experimental results on MuJoCo benchmarks and several multimodal tasks demonstrate that the DACER2 algorithm achieves state-of-the-art performance in most MuJoCo control tasks with only five diffusion steps, while also exhibiting stronger multimodality compared to DACER.
A Generative Re-ranking Model for List-level Multi-objective Optimization at Taobao
May 12, 2025E-commerce recommendation systems aim to generate ordered lists of items for customers, optimizing multiple business objectives, such as clicks, conversions and Gross Merchandise Volume (GMV). Traditional multi-objective optimization methods like formulas or Learning-to-rank (LTR) models take effect at item-level, neglecting dynamic user intent and contextual item interactions. List-level multi-objective optimization in the re-ranking stage can overcome this limitation, but most current re-ranking models focus more on accuracy improvement with context. In addition, re-ranking is faced with the challenges of time complexity and diversity. In light of this, we propose a novel end-to-end generative re-ranking model named Sequential Ordered Regression Transformer-Generator (SORT-Gen) for the less-studied list-level multi-objective optimization problem. Specifically, SORT-Gen is divided into two parts: 1)Sequential Ordered Regression Transformer innovatively uses Transformer and ordered regression to accurately estimate multi-objective values for variable-length sub-lists. 2)Mask-Driven Fast Generation Algorithm combines multi-objective candidate queues, efficient item selection and diversity mechanism into model inference, providing a fast online list generation method. Comprehensive online experiments demonstrate that SORT-Gen brings +4.13% CLCK and +8.10% GMV for Baiyibutie, a notable Mini-app of Taobao. Currently, SORT-Gen has been successfully deployed in multiple scenarios of Taobao App, serving for a vast number of users.